发表于: 2017-12-26 17:22:29
3 687
主要是完成任务25的在main里面测试1000次的查询---->
主要的的代码就是这个
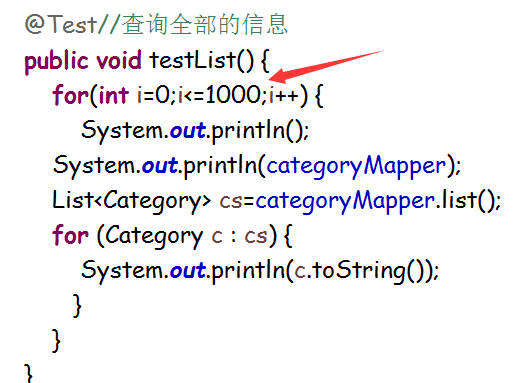
测试完成后(测试成功)
控制台里面的打印的信息
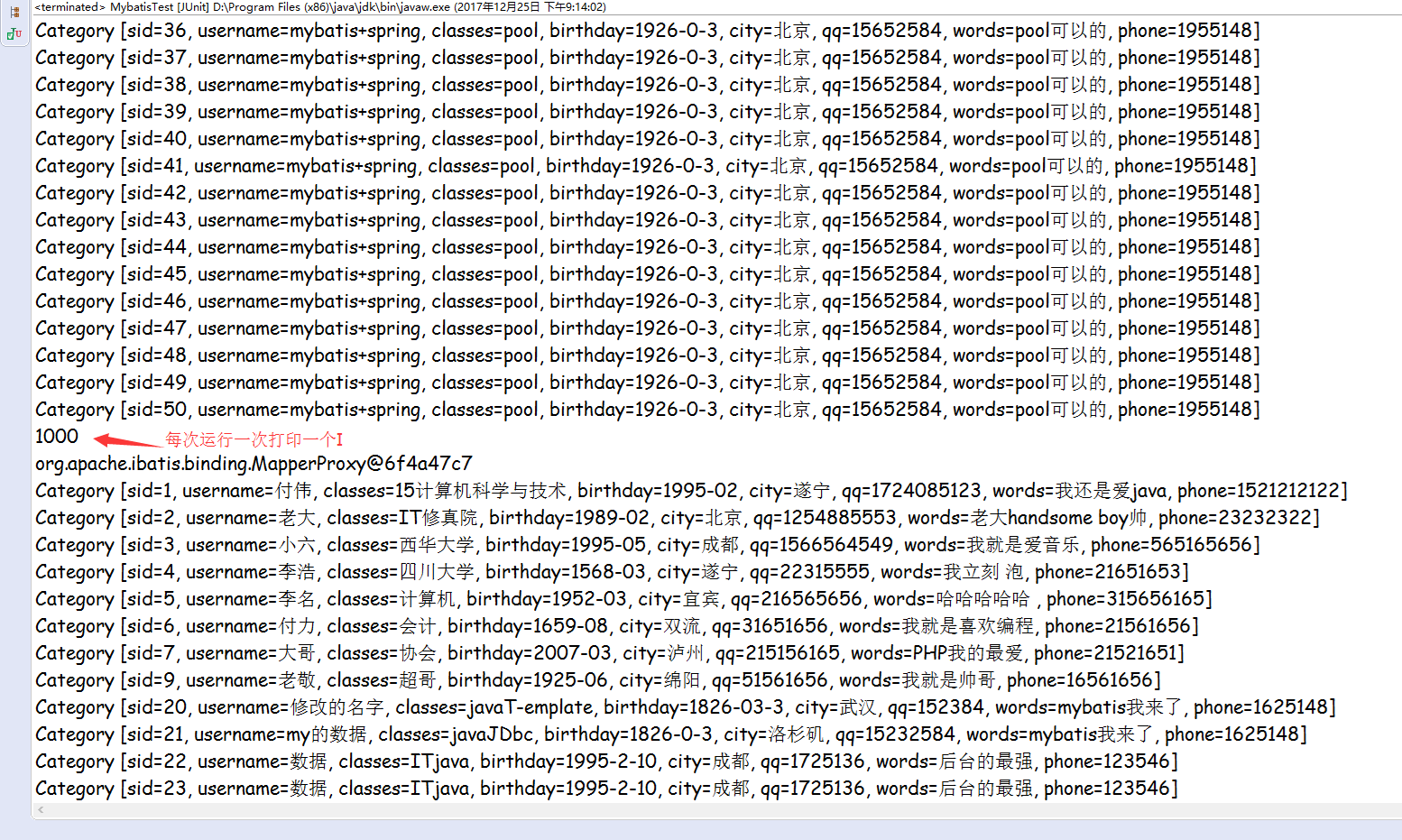
运行成功
运行的过程中明显的感觉就是运行的时间在边长---->不像以前的马上就在控制台里面打印出最后的信息---->Junit测试运行完成
接下来就是中断DB,看异常能否捕捉到----->
开始正常运行一次

断开DB错误的密码mybatis里面的密码少个6
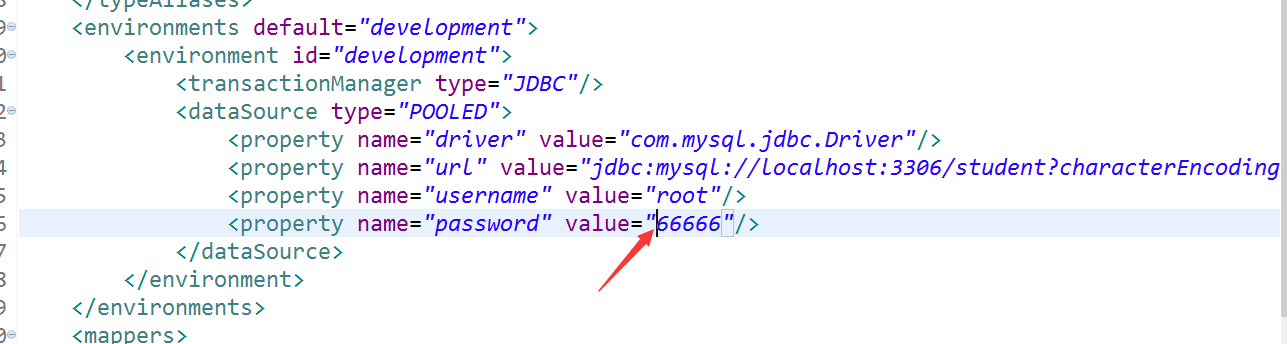
再次运行测试

我还测试另一种把表的名字删除一个n

运行打印的信息

测试了连个信息的错误的DB断开---->可以try ---catch捕捉到异常
任务26的try--catchDB断开可以捕捉到异常
准备检查自己的代码的规范是否合格----->
如果DB的表有改动------>
要保证查询的信息保证可以查询到
开始的模型层的字段要改一下------>那个是和后面的查询的字段相对应的

还有需要修改的地方就是category.XML查询的语句对应的SQL的具体用到字段语句需要修改

还有需要修改的地方就是插入数据的具体修改的字段需要修改(在测试类的里面)

要修改的地方知识对应的字段修改的地方---->java的代码最好要少的修改
最多的是XML里面的配置详细信息修改
对于上面如果DB里面的信息发生了改变 --->修改了也就几分钟可以讲对应的字段修改好----->花费的时间比较短就可以完成
接下来就是讲数据库里面插入100万条数据

不知道怎么了运行了1000条就不运行了
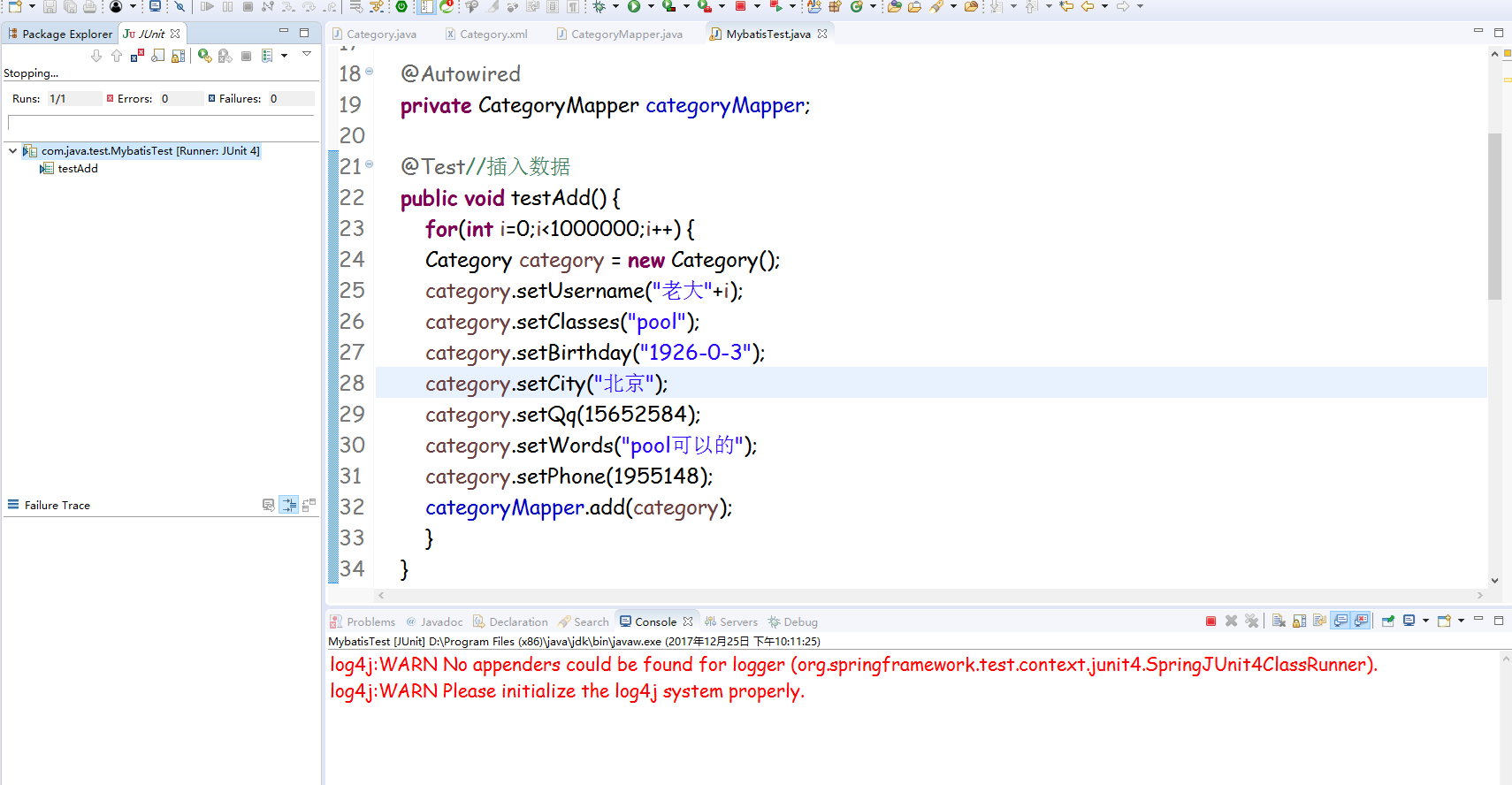
可能是username的字段的范围有关
在师兄的指点下package com.java.test;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class InsertTest {
public static void main(String[] args) {
Connection conn = DBUtil.getConnection();
String sql = "insert into stu_information (username,classes,birthday,city,qq,words,phone) values (?,?,?,?,?,?,?)";
try {
PreparedStatement prep = conn.prepareStatement(sql);
// 将连接的自动提交关闭,数据在传送到数据库的过程中相当耗时
conn.setAutoCommit(false);
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
long start2 = System.currentTimeMillis();
// 一次性执行插入10万条数据
for (int j = 0; j < 100000; j++) {
prep.setString(1, "老大"+i*j);
prep.setString(2, "java");
prep.setInt(3, 1995-02-02);
prep.setString(4, "成都");
prep.setInt(5, 18515465);
prep.setString(6, "插入100万条记录");
prep.setInt(7, 11598257);
// 将预处理添加到批中
prep.addBatch();
}
// 预处理批量执行
prep.executeBatch();
prep.clearBatch();
conn.commit();
long end2 = System.currentTimeMillis();
// 批量执行一次批量打印执行依次的时间
System.out.print("inner"+i+": ");
System.out.println(end2 - start2);
}
long end = System.currentTimeMillis();
System.out.print("total: ");
System.out.println(end - start);
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
conn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
http://blog.csdn.net/zhangjinpeng66/article/details/10416721(参考的文档)
最后运行的时间的输出
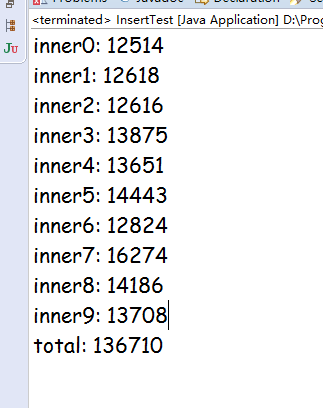
在数据库里面
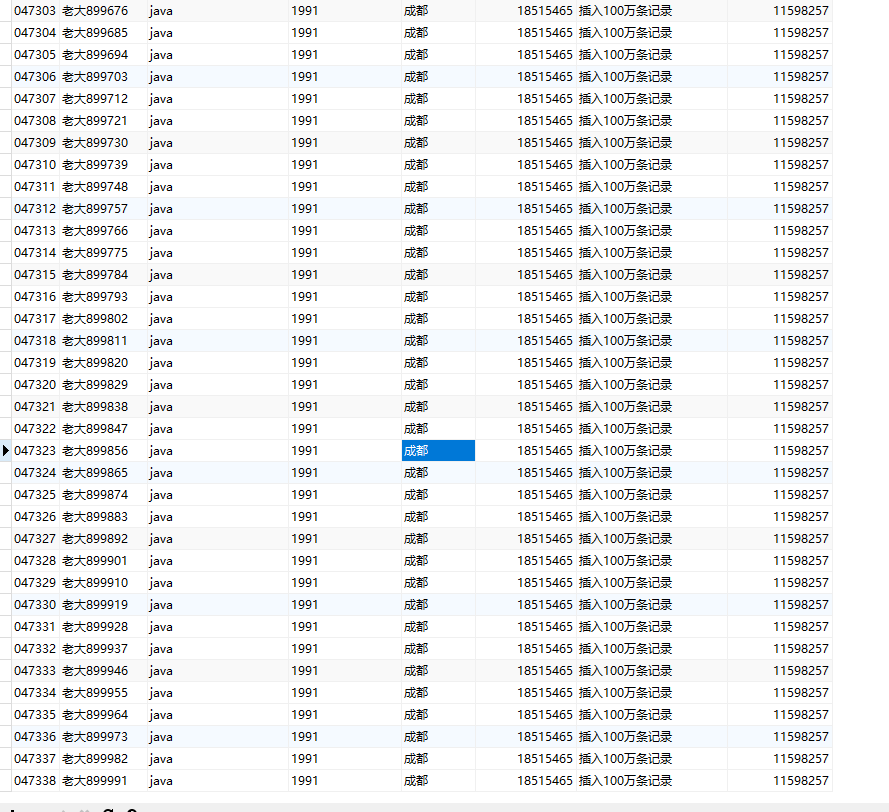
我在cmd控制台里面查询了一下

我在控制台里面查询了一下全部的数据跑了好久
100万次太久了我就测试没有索引的查询

添加了索引的速度加快


开始老大说的量级不够----?>现在觉得100万的查询的时间的的数据差别也是不很大
100万的数据量的测试完成了----->看见那个索引的优越性还是有一点不是很明显
接下来准备3000万的数据
这次写进去的数据感觉时间很久运行了很久现在才10个循环---->还有90个循环

这个写入的速度很慢---->可能太多了
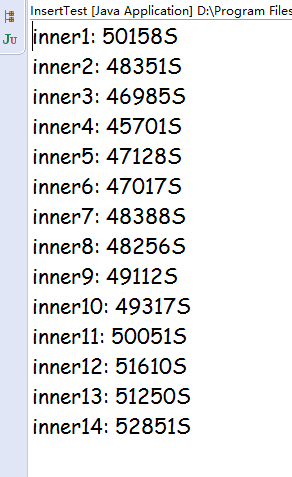
终于运行完了(找了一个偏后面的数据改了一下准备测试)
开始是没有索引的测试(这次比较明显29s左右)

接下来建立索引的查询测试(这个索引的作用比较直观)

测试基本就感受到比较直观了
今天完成的事情:前面的数据库里面插入100万条记录和3000万条记录,在开始100万比较轻松,到3000万的时候那个就时间比较久,后面测试的索引和没有索引的记录也比较直观,查询的效率和速度也比较直观,还有try---catchde 异常能够捕捉到的实现
明天的计划:准备将自己关于任务一学习的做一个总结---->还有将项目的提交到GitHub是上面
今天遇到的困难:就是在插入数据3000万的数据.电脑快爆炸了----->运行了一个多小时终于搞定了最后的数据库性能测试
今天的收获:感觉索引的强大,还有好处,还有开始数据怎么插入到数据库这么大的数量
加油----->坚持




评论