发表于: 2017-12-24 19:52:58
1 599
昨天对于MYSQL有了初步的认知,今天继续学习,完成任务一的要求。
昨天用Navicat创建表“table28”,用cmd命令行创建了“table_28”(复制)和“students_28”(手动键入)。
****
今天做的内容:task1 1~11
当我使用SELECT ... FROM ...时,发现不管哪个表。查询name时,中文内容统统乱码。百度提供的方案是将设置里面所有的编码都改为utf8,然而,即便如此,依旧出现乱码情况:
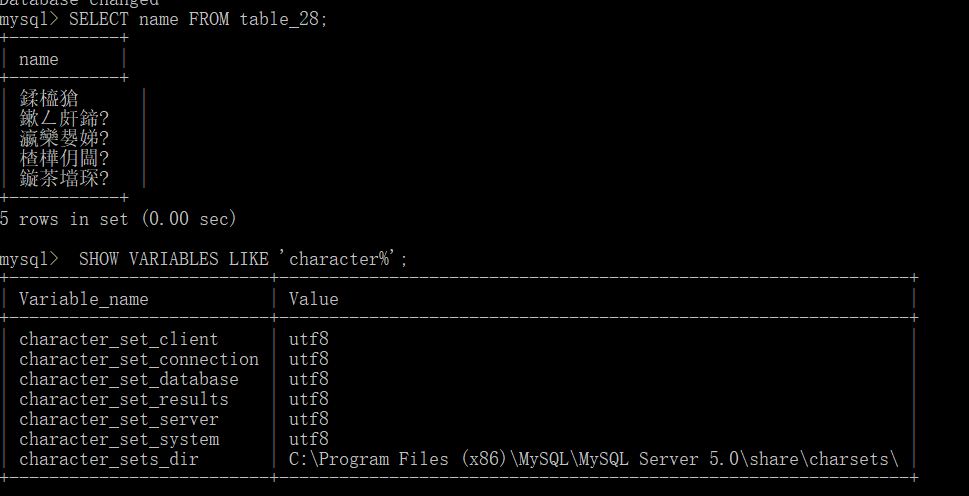
而我用Navicat打开时,发现数据本身并没有出现什么错误。于是我继续百度了下,发现原因在cmd窗口上:
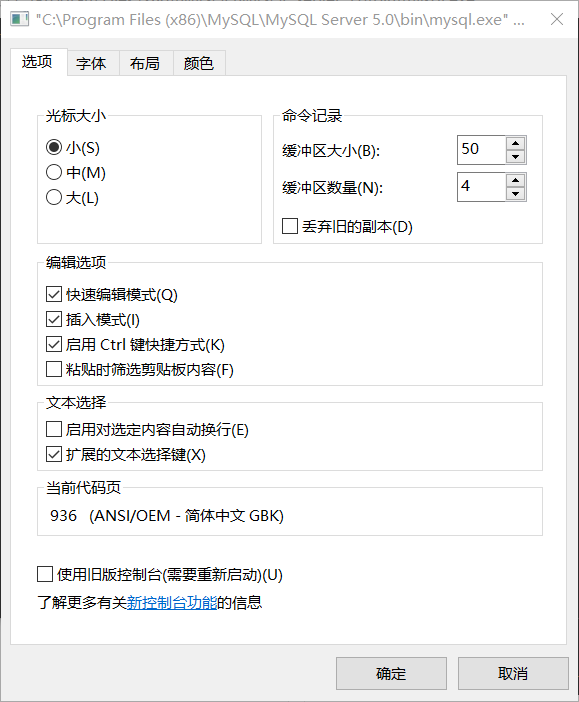
当前代码页为936,也就是gbk编码,显然和utf8不搭配。
在这里,我尝试了另一种方法:干脆将服务端的编码改为gbk,服务器端编码为utf8。
效果如下所示:
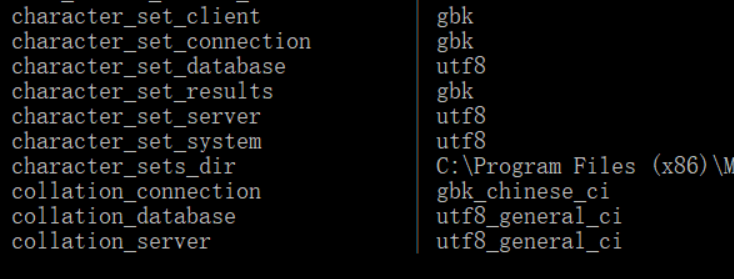
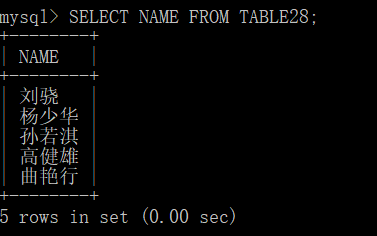
因为校对规则是utf_general_ci,ci代表case insentitive 表示对大小写不敏感 所以我用大写的“NAME”也成功识别了字段“name”,而且下面显示的也是NAME,这个机制有点神奇...
可以看到,修改之后成功运行,目前看来并没有出现什么差错——当然这只是一个个小小的实验,只是为了加深知识的理解。百度了下有关知识点,我们最好还是把所有的编码统一为utf8,以免发生意外的错误。
通过百度可知,可以用cmd指令“CHCP 65001”改变cmd.exe的代码页,改变代码页后,再通过键入命令行“mysql -u root -p”的方法进入mysql。但麻烦的是,“CHCP 65001”指令的效果是一次性的 下次打开的时候还需要重新输入。通过百度,我又找到了一个解决办法,通过修改注册表的方式:
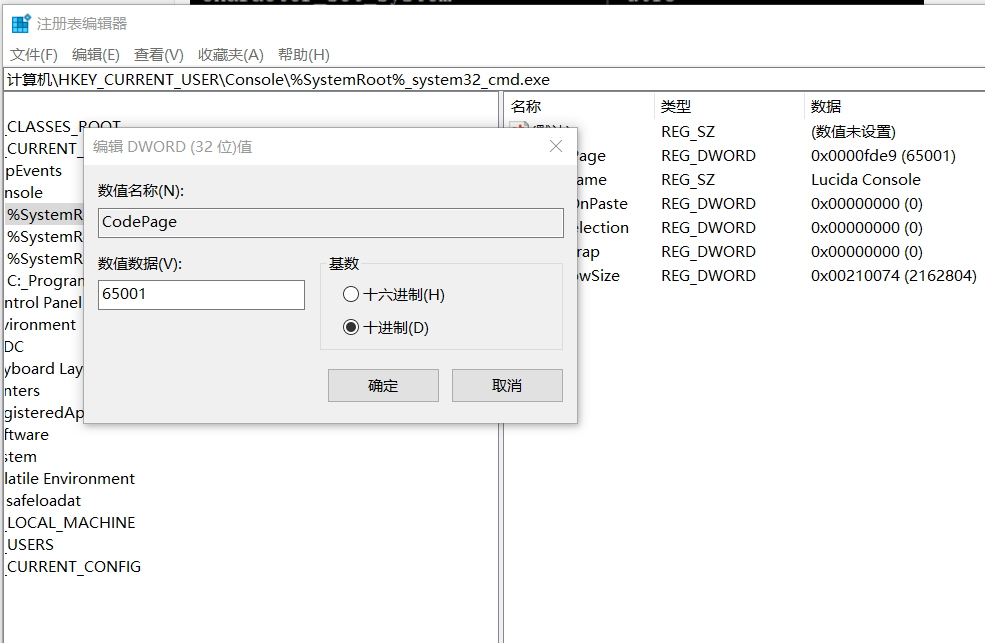
然后再次修改MYSQL的配置,再次实验:
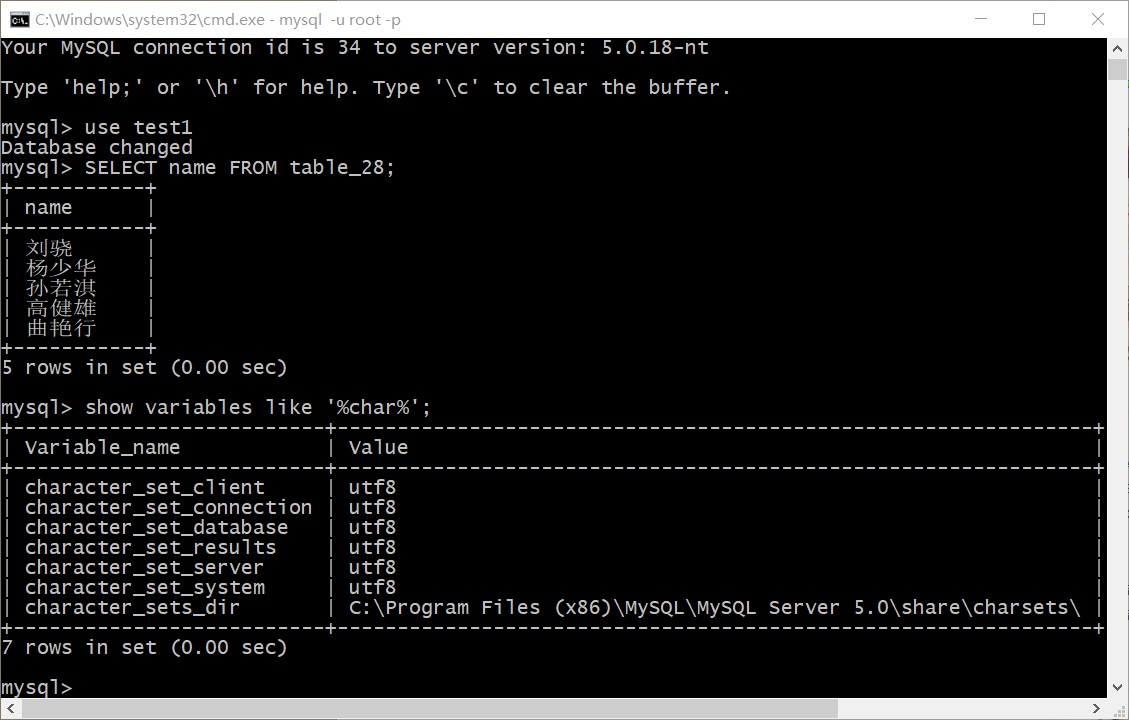
接下来是实验了一下UPDATE,用到了WHERE子句,首先用Navicat修改了表的内容,然后用cmd命令行修改:
 ........
........
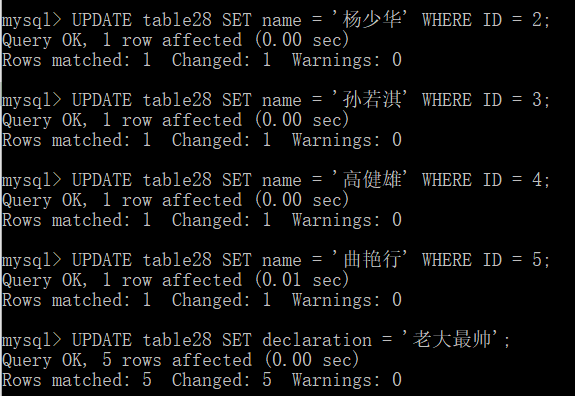
这里有个小插曲,当我用cmd修改完,我用Navicat再次打开(没有提交事务)的时候,发现显示的内容丝毫没有发生改变。我百度了下,知道了事务的一些概念(ACID),其中为了保证隔离性,设置有四个隔离登记,从宽松到严格分别是READ UNCOMMITTED 、 READ COMMITTED 、REPEATABLE READ 以及SERIALIZABLE,其中MYSQL的默认事务隔离级别是REPEATABLE READ(可重复读)。
这其中涉及到一些知识点,比如脏读、换行、读写锁等,不过和任务一的关系都不是很大,暂且跳过,以后有余裕的时候可以回头仔细了解。
然后用ALTER TABLE ...(表名) CHANGE ...(旧项) ......(新项及其属性)修正了昨天创建表格时的拼写错误:
ALTER TABLE students_28 CHANGE graducated_school graduated_scholl VARCHAR(10) NOT NULL;
检查,成功修改了字段名。
接下来,尝试导出导入表“students_28”为sql文件:
首先 从cmd 窗口进入MYSQL,导出MyTable.sql文件,然后删除了学院“刘骁”的信息,然后再导入sql文件,观察文件是否复原,导出路径下是否存在相应的sql文件:
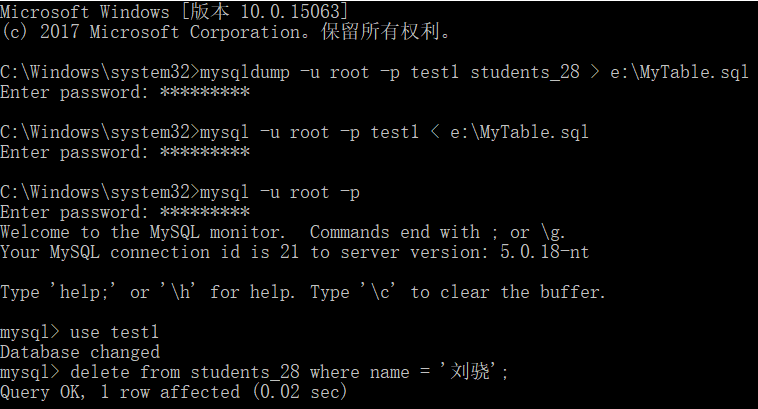
(PS:总共导入了两次 第一次只是实验 第二次为有效操作 但我截漏了...)
可以看出来 “MyTable”只是sql文件的名字,和MYSQL中的表名没有直接关系,只不过被导出的表的表名存储在sql文件里。所以,在导入的时候,无需再次键入表名。经过试验,当被导出表被删除后,导入sql备份文件,将会新建一个同名表。
因为之前设置过了主键 所以就给name加了普通索引:
alter table students_28 add index num(name);
在Navicat中打开表->设计表 可以看见索引的属性:
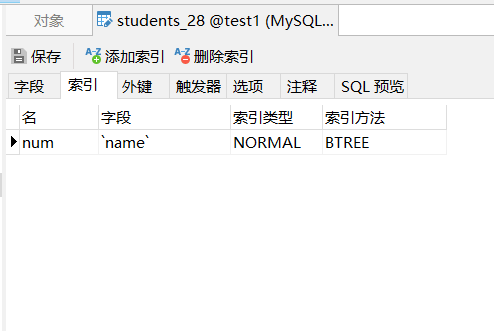
这里我遇见了比较熟悉的字眼“BTREE”,基数为2(InnoDB表默认)的时候也就是二叉树。当初我学C语言的时候,自己写过二叉树的接口,所以对其实现方式比较熟悉。
结合网上百度的一些知识,我感觉索引就是拥有特定数据结构的目录...然后我用Navicat尝试了多条数据的crub操作,发现索引的确有作用,只不过这张表储存的行数很少,只有当数据量大的时候索引的优势才能体现出来。
自此 MYSQL的内容告一段落。
明天计划的事情:
1、JDBC
2、继续结合任务一学习
收获:MYSQL语法的继续熟悉、数据结构有关知识、软件常见问题解决的经验。




评论