发表于: 2017-12-15 21:46:20
0 586
一.今天完成的主要事情
1.和小组成员讨论,解决了昨天遗留的问题
这个问题是关于如何实现学员端随机题目的问题,最后讨论出的方案是我们后端先从数据库中获取所有的id,组成一个List,然后对这个List进行乱序,最后再将这个IdList直接返回给app端,app端则每次截取相应的id访问接口,获取数据.
那么问题的关键就是将List中的所有数据乱序,需要花费多长时间,实现是否复杂?
张帆师兄在网上找了一个方案,用Collections接口中自带的 shuffle方法实现将一个list中的数据乱序.
然后由于张帆师兄没有时间,所以由我来写demo调研,demo代码如下
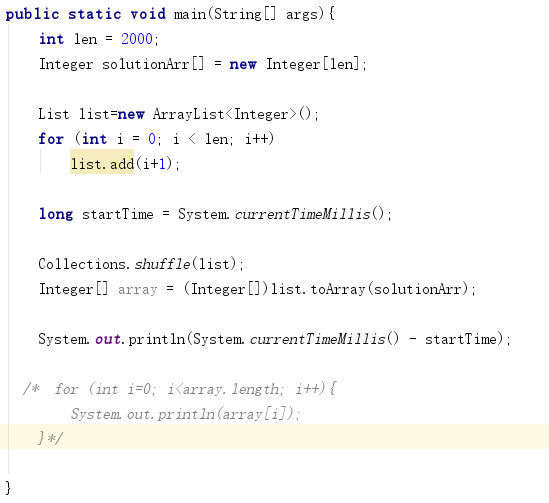
从输出的结果来看,一个由2000个元素的list,经过Collections接口的shuffle方法,成功的实现了乱序,而且记录消耗时间只用差不多3到4ms.完全不会成为性能的瓶颈.
这是输出结果

2.继续学习付老师的课程
学习了数据结构的Set,List,Map以及查找算法(Hash)一节

.png)
.png)
.png)
.png)
.png) 一是结合链表实现,即先对数据的关键字进行hash函数计算,计算得到之后如果发生冲突则生成一个链表,将新加的数据加到链表后面,查找时先计算哈希值,然后再遍历链表
一是结合链表实现,即先对数据的关键字进行hash函数计算,计算得到之后如果发生冲突则生成一个链表,将新加的数据加到链表后面,查找时先计算哈希值,然后再遍历链表
二是当计算出来的值所在的位置已经有数据的时候,将该值顺序再进行移动,直到找到一个不冲突的位置,存放进去
.png)
.png)
.png)
ArrayList和LinkedList的区别
这两个List的区别实际上就是顺序存储和链式存储之间的区别
ArrayList通过序号查找元素快,但是增加和删除元素效率比较低,尤其是当原来分配的空间用完,需要对数组进行扩容的时候会对整个数组进行复制,非常消耗内存,所以适用于遍历和查找元素时使用,不适合删除和增加元素操作比较多的情况使用.
LinkedList插入和删除时的速度会更快,因为链表中插入和删除的时候只需要更改指针的指向即可,但是通过下标进行遍历的时候速度会很慢,因为要先计算出该下标在整个链表的前半段还是后半段,然后顺序查找到元素,所以LinkedList适合插入和删除比较频繁,而随机查找比较少的情况.
.png)
.png) HashSet的内部实现时通过散列表实现的,查找速度非常快,适合经常查找的场合,而且HashSet的性能通常比TreeSet的性能要快,但是由于TreeSet的内部实现是通过平衡二叉树实现的,所以天生已经排好序了,所以TreeSet适合需要有序的场景.当然,由于两者都实现了Set接口,所以HashSet和TreeSet之间的值都不能为空.
HashSet的内部实现时通过散列表实现的,查找速度非常快,适合经常查找的场合,而且HashSet的性能通常比TreeSet的性能要快,但是由于TreeSet的内部实现是通过平衡二叉树实现的,所以天生已经排好序了,所以TreeSet适合需要有序的场景.当然,由于两者都实现了Set接口,所以HashSet和TreeSet之间的值都不能为空.HashMap和TreeMap之间的区别
HashMap,TreeMap之家的区别基本和HashSet,TreeSet之间的区别相同,只不过由于两者都实现了Map接口,所以这两个Map中都必须是通过Key-Value来存储数据,所以HashMap适合查找,删除,定位元素,而TreeMap更适合有序的场景.
.png)




评论