发表于: 2017-12-13 23:26:39
1 686
今天完成的事
学习范式概念 也在知乎上摘了些笔记
范式:实际上你可以把它粗略地理解为一张数据表的表结构所符合的某种设计标准的级别

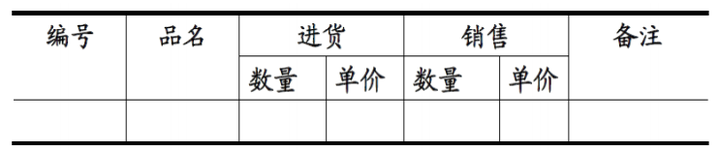
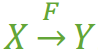
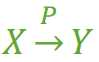
指出的错误,这里改为:『Y 不包含于 X,且 X 不函数依赖于 Y』这个前提),那么我们就称 Z 传递函数依赖于 X ,记作 X T→ Z,如图3。
作者:刘慰
总结原型图中的字段写成表 刚上手比较生 搞得比较慢
直接按照wiki的格式
| CLOUMN | COMMENT | REMARKS |
| id | 自增ID | |
| user_name | 昵称 | 账户 |
| user_phone_number | 用户手机号 | |
| user_password | 用户密码 | 加密 |
| user_account | 用户账户 | |
| user_wechat_account | 用户微信账户 | |
| user_status | 用户状态 | |
| user_picture | 用户头像链接 | |
| user_email | 用户邮箱 | |
| create_by | 创建者 | |
| update_by | 更新者 | |
| create_at | 创建时间 | |
| update_at | 更新时间 |
| CLOUMN | COMMENT | REMARKS |
| id | 自增ID | |
| user_phone_number | 用户手机 | |
| user_account | 用户账户 | |
| study_star | 学习星 | |
| grade | 年级 | |
| course | 课程 | |
| study_time | 学习天数 | |
| course_time | 已学课时 | |
| create_by | 创建者 | |
| update_by | 更新者 | |
| create_at | 创建时间 | |
| update_at | 更新时间 |
| CLOUMN | COMMENT | REMARKS |
| id | 课程ID | |
| course_title | 课程标题 | |
| course_intro | 课程介绍 | |
| grade | 所属年纪 | |
| subject | 所属科目 | |
| course_time_sum | 课时总数 | |
| document_number | 资料数 | |
| course_price | 课程价格 | |
| course_start | 解锁课程星数 | |
| course_status | 课程状态 | |
| award_start | 奖励星星 | |
| need_pay | 是否付费 | |
| create_by | 创建者 | |
| update_by | 更新者 | |
| create_at | 创建时间 | |
| update_at | 更新时间 |
| CLOUMN | COMMENT | REMARKS |
| id | 任务id | |
| task_name | 任务名称 | |
| need_tips | 提示状态 | |
| tips_sort | 提示种类 | |
| tips_info | 提示信息 | |
| tips_time | 提示时间 | |
| create_by | ||
| update_by | ||
| create_at | ||
| update_at |
就弄了这么些 已经上手了 剩下的明天弄出来
下午抽空看了下腾讯公开课讲的JVM 稍微总结了一下
讲的不是特别深 边听边做了些笔记
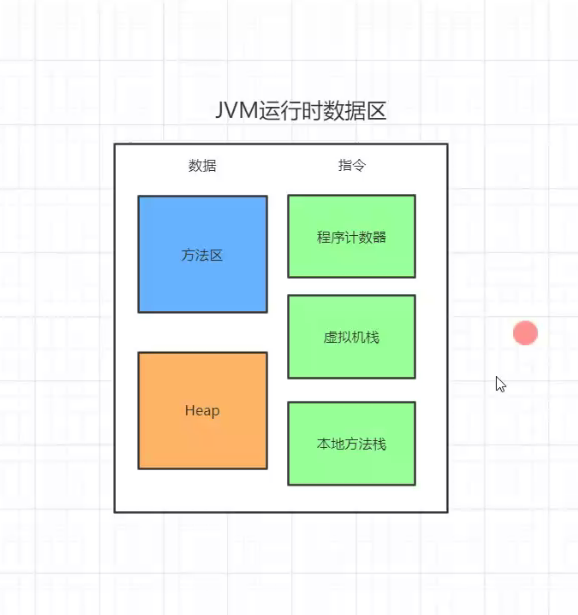
指向当前线程正在执行的字节码指令的地址 行号
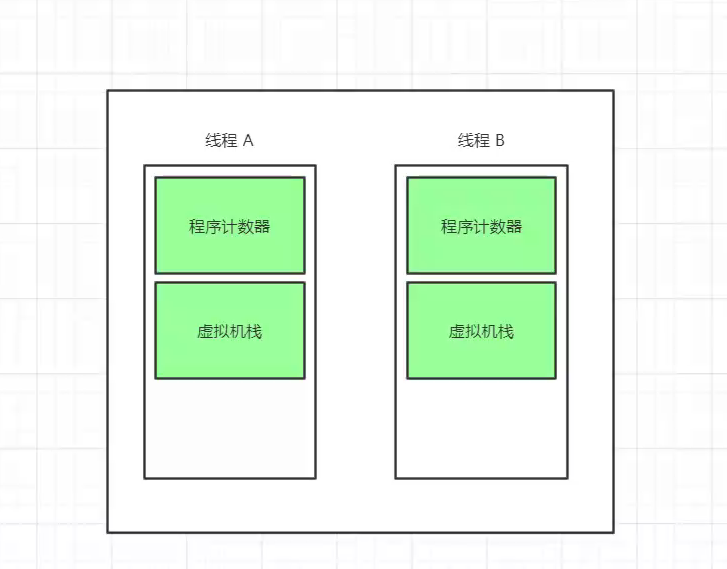
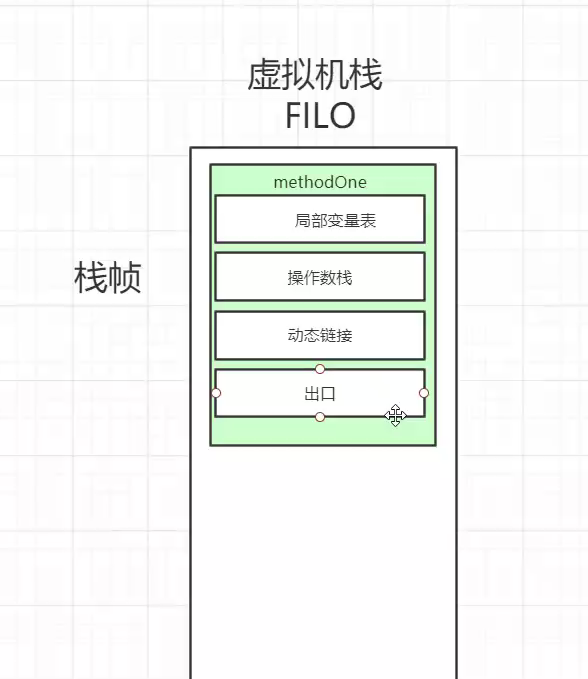
看穿代码运行的套路
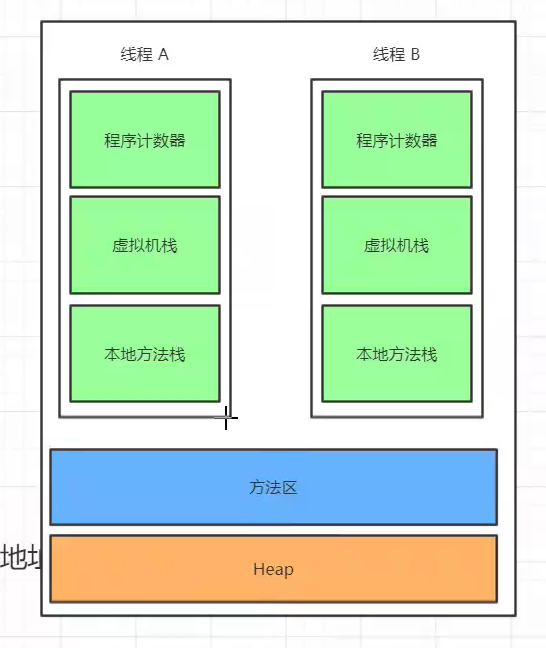
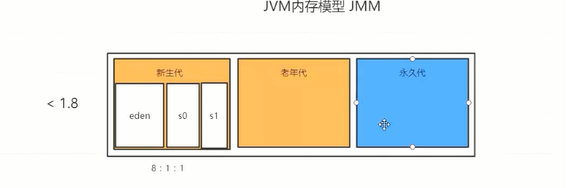
1.8取消了 永久代
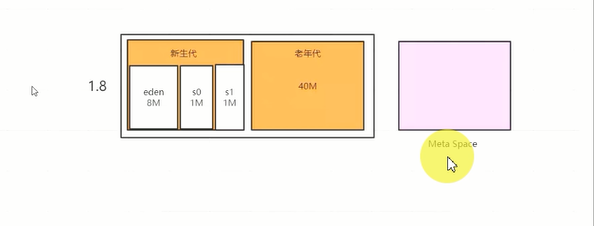
遇到的问题:
范式还是不太理解 在博客上找了几篇写的通俗易懂的 没来的及总结笔记
先放上链接吧
http://blog.jobbole.com/92442/
表和表之间的关系没太弄清楚 还需要再捋一下
明天的计划:
把字段挖完 听需求讲解
收获:范式初步认识 JVM初步了解 大概概念清楚了 以后学着没那么难
任务进度:复盘评审通过 开始DB设计
开始时间:2017.12.12
预计评审时间:12.20
禅道:http://task.ptteng.com/zentao/project-task-276.html




评论