今天完成的事情:
1. 字段整理
2. 哈希表
明天计划的事情
1. 开始看回家学习的相关的内容。
遇到的问题:
无
收获:
1. 前台字段整理版本1.0
用户:
手机号(11位),密码,头像,昵称,年级,学习星(积分?)
关联(qq, 微信, 微博,教育云),购买资料数,击败用户百分比,学习天数,
邮箱,用户名,昵称,上次登录时间(签到用),个人分享注册链接,邀请人
最近学习课程(完成的课时,),同步预习绑定的教材,收藏/购买/分享的课程,试卷,消息(系统通知),
管理者:
用户AND 课程:
我的课程,进度(已完成课时/总课时) ,是否收藏,购买否,购买时间,支付方式,邮箱
课时:
课程,课时题目,购买费用,任务数量,需要学习星,资料(考虑),小贴士,完成后获得学习星,是否有资料,知识剖析
用户AND课时下:
状态(正在学习/已完成),是否解锁,是否收藏
课程(教材下):
年级,科目,难度等级,课时,题目,教材版本,价格,资料(试卷?)数,(相关任务),是否解锁,需要学习星,多少人正学习,购买费用,是否下架,是否热门,是否推荐,简介
课程AND标签:
资料:
所属课程,正文
试卷:
时间,所属任务,名称,价格
难度:
科目,难度(填写1,2等),难度说明
任务:
课时题目,课程,任务(字段填写1, 2等),例题(一个任务几个例题?,图片),动画(音频),小贴士,文本(或步骤)
用户AND任务:
分数,录音
教材:
出版社,年级,科目
用户AND分享注册:
来源的课时,在该课时下分享链接注册的人
资讯:
图片,正文,发表时间,阅读量
用户AND消息(资讯吗?)
APP本身
版本特性,版本号,客服电话,公众号,邮箱
帮助:
(我的—我的设置—使用帮助下)
问题名称,解决方案
意见反馈:
用户,意见
2. 哈希表
本质上是把要存入信息的关键字(key?)和要保存的内存地址进行一个映射,建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应。
hash 不允许重复就是因为根据关键字进行存储,如果key相同就会造成value覆盖
对关键字进行计算,例如:

用上述得到的数值作为对应记录在表中的位置,得到下表:
哈希表算法-哈希表的构造方法
1、直接定址法
例如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。
2、数字分析法
有学生的生日数据如下:
年.月.日
75.10.03
75.11.23
76.03.02
76.07.12
75.04.21
76.02.15
...
经分析,第一位,第二位,第三位重复的可能性大,取这三位造成冲突的机会增加,所以尽量不取前三位,取后三位比较好。
3、平方取中法(????)
取关键字平方后的中间几位为哈希地址。
4、折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
例如:每一种西文图书都有一个国际标准图书编号,它是一个10位的十进制数字,若要以它作关键字建立一个哈希表,当馆藏书种类不到10,000时,可采用此法构造一个四位数的哈希函数。如果一本书的编号为0-442-20586-4,则:
0-442-20586-4, 4220 5864 04

5、除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key) ,其中random为随机函数。通常用于关键字长度不等时采用此法。
哈希表算法-处理冲突的方法
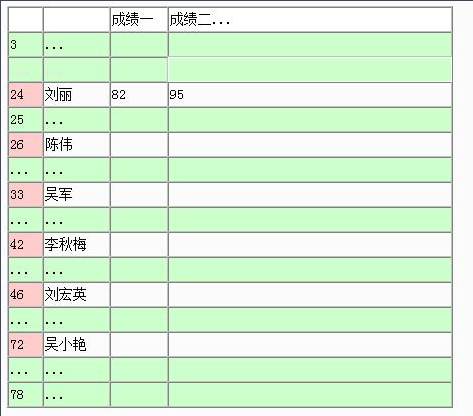
如果两个同学分别叫 刘丽 刘兰,当加入刘兰时,地址24发生了冲突,我们可以以某种规律使用其它的存储位置,如果选择的一个其它位置仍有冲突,则再选下一个,直到找到没有冲突的位置。选择其它位置的方法有:
1、开放定址法
Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中m为表长,di为增量序列
如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
如果di取值可能为伪随机数列。称伪随机探测再散列。
例:在长度为11的哈希表中已填有关键字分别为17,60,29的记录,现有第四个记录,其关键字为38,由哈希函数得到地址为5,若用线性探测再散列,如下:

2、再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
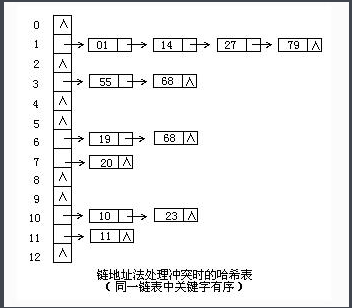
3、链地址法
将所有关键字为同义词的记录存储在同一线性链表中。
4、建立一个公共溢出区(????)(不懂)
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
进度:
禅道:http://task.ptteng.com/zentao/project-task-264.htm




评论