发表于: 2017-12-11 00:10:19
1 777
12.10
今天完成的事:
1、完成mybatis注解式开发;
2、在师兄的帮助下解决了远程连接mysql的问题;
3、将任务1的代码上传至svn。
遇到的困难:
1、Navicat远程连接mysql出现如下错误:
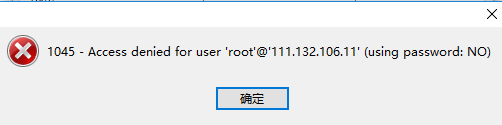
111.132.106.11是北京铁通的ip,这个错误说明是mysql没有对这个ip地址开启访问权限,
但是查询mysql的访问权限结果如图,%表示对所有ip开放权限。
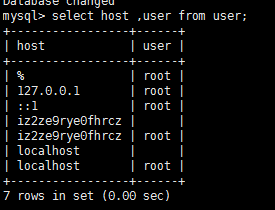
最后解决方案,将之前开放的权限删除,重新开放mysql的权限,成功。
迷。
明天计划:
提交任务1,开始任务2.
收获:
1、mysql 查看用户权限---select host,user from user; (数据库切换到mysql)
2、mysql开放远程权限---
GRANT ALL PRIVILEGES ON *.* TO 'username'@'192.168.1.9' IDENTIFIED BY 'userpassword' WITH GRANT OPTION;
flush privileges;
username表示远程访问的用户名,
192.168.1.9是自己要设置的允许访问的,%表示对所有ip开放,
userpassword表示自己设置远程连接的密码
3、重启msyql--- systemctl restart mysql
查看字符编码---show variables like 'character_set_%' ;
4、linux查找命令---whereis **
删除整行---dd
查看目录所有内容---ls(list的简写)
创建文件夹---mkdir (make directories)
删除文件---rm (remove) 需要管理员权限的话 -f (force强制) ,删除目录 -r (慎重)
查看文本文件的内容---cat
编辑文本文件---vim
centos7查看防火墙开放端口 firewall-cmd --list -ports
centos7开启端口 firewall-cmd --zone=public --add-port=80/tcp --permanent
12.11
1、maven是什么:
maven基于对象模型(POM),可以通过一小段描述配置项目的构建、文档、报告的软件管理工具。核心功能是叙述项目之间的依赖关系,就是通过pom.xml配置文件获取jar包,
antAnt 的项目管理工具(作为 make的替代工具)不能满足绝大多数开发人员的需要。通过检查 Ant 构建文件,很难发现项目的相关性信息和其它信息(如开发人员/拥有者、版本或站点主页)。由于 Maven 的缺省构建规则有较高的可重用性,所以常常用两三行 Maven 构建脚本就可以构建简单的项目,而使用 Ant 则需要十几行。
一句话,maven功能更强大,操作更简单,由于没有用过ant理解的不是很透彻。
<1>maven项目的id
groupId---表示项目组的名称,采用包名的写法,一般是公司域名的倒写,如com.ptteng.jndhu,
artifactId---表示项目名称;
version--表示项目的版本号;
这三个是一个项目的id,用来在中央仓库定位项目的。
<2>三个仓库
本地仓库:maven将项目构建时所需要的依赖(jar包)放在本机下的一个目录管理,在m2.repostory中,一般修改本地仓库位置,将一般项目需要的jar 包全都下载到本地仓库,需要时直接从本地仓库获取。
第三方仓库:又称内部中心仓库,也称私服,一般是公司内部创建,使用局域网访问,保证开放项目时所需要的jar包版本相同。
中央仓库: maven的远程公用仓库,包含所有的常用类库,http://repo1.maven.org/maven2。
获取jar包的优先顺序,本地仓库--第三方仓库--中央仓库
<3>maven常用命令
编译:mvn compile 将src/main/java中的源代码编译成class文件,放在target下
测试:mvn test 目录编译,框架的运行测试
清理:mvn clean 删除target文件及其内部编译好的class文件
打包:mvn package 生成压缩文件放在target下,java项目时jar包,web项目时war包
安装:mvn install 将压缩文件上传到本地仓库
部署/发布: mvn deploy 将压缩项目上传至远程仓库,所有开发人员共享
执行后面的命令时,前面的命令自动执行,如执行install时,自动执行编译测试清理打包的命令。
<4>maven跳过junit
需要 surefire插件,将属性skip-test设置为true
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
<5>log4j特点
1、设置日志信息的优先级、日志信息的输出目的地以及日志信息的输出格式
log4j的三个目的
监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作;
跟踪代码运行时轨迹 ,作为日后审计的依据;
担当集成开发环境中的调试器的作用,向文件或控制台打印代码的调试信息
<6>为什么DB的设计中要使用Long来替换掉Date类型
java.until.Date转换为java.sql.Date时日期的时分秒被去掉,数据精度发生变化。
1、有利于计算时间差
2、方便java与数据库之间的传输
<7>自增ID有什么坏处?什么样的场景下不使用自增ID?
1、id固定无法改变,
在id发生变化或者是涉及id增删的不用
<8>唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引允许查询字段中包含相同的值,可以提高查询效率。
第一、如果查询的字段值都是唯一的,唯一索引简化了mysql的索引管理工作,提高速率。
第二、唯一索引的字段值必须是唯一的,而且在插入新数据时会自动检索字段值是否已经存在,如果存在则插入失败。唯一索引主要是保证数据的唯一性。
<9>CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
<10>varchar
varchar的长度是指显示的字符数,如varchar(4)只能显示前四的字符,不是字节。
Text是指长文本0-65 535字节,LongText是指极大文本0-4 294 967 295字节。
<11>怎么进行分页数据的查询,如何判断是否有下一页?
select * from student limit a,b; a表示从第a+1条开始查询,b表示要查询的条数。需要扫描前a条数据,然后扔掉,从a+1开始显示,所以在大批量数据后面查询时效率很慢。
SELECT * FROM student WHERE name="李四i" ORDER BY id LIMIT 50, 10 ;
可以通过子查询和join分页方式提高查询效率,主要是越往后的分页,limit的偏移量越大。
SELECT * FROM student WHERE id>1020 ORDER BY id ASC LIMIT 20; asc升序排列,desc降序排列。分页查询,每次只查询20条,
SELECT * FROM student WHERE id <2500 ORDER BY auto_id desc LIMIT 20,20 ; 查询第20页数据,每页20条。
<12>为什么不可以用Select * from table
第一*表示查询所有字段,一般是需要哪个查哪个,全都查影响效率,第二是可读性差。
<13>贫血模型与充血模型
贫血模型是指model中只有状态(属性),不含有行为(方法),采用这种涉及需要分离DB层,专门用于数据库操作。优点是层次结构清楚,各层之间单向依赖。
充血模型是model中既有状态又有行为,符合面向对象的设计方式。优点是面向对象,缺点是比较复杂,要求较高。
<14>Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例
IoC,inversion of control ,控制反转,将传统上由代码直接操纵的对象的调用权交给容器,通过容器来实现对象的装配和管理。实现方式是依赖查找和依赖注入。
作用的降低代码的耦合度。
<15>Interface和Impl这种方式的好处是什么
1、简单规范,接口理清了要实现的业务逻辑,可以同时去实现接口
2、可拓展性高。
3、 安全、严密性,降低耦合度。
<16>
使用抛出异常的情景主要有:
1. 异常必须由容器来处理,异常时容器做出不同处理的依据和触发;
例如:有事务处理的方法中,事务相关的逻辑必须抛出异常,而不能捕获异常,否则会导致事务不回滚。
2. 本地方法不知道如何处理,只有调用方才可能知道如何处理异常;
例如:一些底层的方法,其可能出现多种异常,且调用方可能根据不同的异常做出不同的处理,只能抛出异常,而且必须是具体的异常类型,而不能是笼统的Exception类型。
使用try/catch捕获异常的情景主要有:
1. 程序块中语句可能的异常不能引起其他逻辑中断;
例如:缓存逻辑不能影响正常的逻辑运行,故缓存逻辑应该放在try/catch块中。
2. 必须对异常进行处理,否则会降低用户使用体验。
例如:异常到了Controller层,若不处理则会返回404或500错误页面,因此,必须使用try/catch处理各种异常。




评论