发表于: 2017-12-03 01:04:30
1 828
较真起来才发现自己差的还是真的多。
今天的主要内容为数据库的索引。
一下内容只是我今天学习后的一些理解,不一定正确,以后肯定会有修正,做一些记录帮助自己缕清思路,同时回忆学习内容。
首先,数据库建立建立索引的目的主要用于提高查询效率,索引是建立在表格的某一列上面的,所以一个表格可以有多个索引。
索引的本质其实是对对应列中的每个值建立一种全新的数据结构,对于多数的数据库,多采用B-/+树的数据结构,使得查询的复杂程度由O(N)下降到O(logdN)。
这短短的一句话,就是非科班生和科班生学习效率的差距啊~
数据结构:数据与数据之间存在着一些相互的关联或关系,这些数据与关系加起来成为一个整体,可以理解为数据结构。
之前在java学习中其实已经接触到了一些数据结构,比如数组就是一种线性表的顺序储存结构,长度固定,顺序固定;栈也是一种数据结构,他的特点是后进先出等等等等。
索引涉及到的数据结构叫做树,通过学习了二叉树,二叉平衡树,能大致理解索引的工作原理。
以如下表格为例:
| 姓名 | 年龄 |
| M | 23 |
| G | 26 |
| H | 56 |
| C | 14 |
| S | 62 |
| I | 86 |
这个表格的数据记录有n=6条,没有索引查找某条姓名记录,数据库会用查询的关键字与数据库中的数据进行对比,理论上的最大对比次数为n,也就是前面所说的复杂度为O(n)。
(关于时间复杂度O(n)的概念则是另外一个问题了,可以理解为他是一个衡量算法或者操作的时间长短,复杂程度的标准,这个值越小,表明效率越高。有一个比较公式,也很好理解O(1) < O(logdN)<O(n)<O(n*n)<O(n*n*n);)
如果我们为姓名建立了索引,就能通过索引提高查找的效率。
首先有第一个姓名M创立根节点,判断下面的第二个G,若小与M则往左侧建立子节点,若大于则向右建立子节点,由此循环下去,最终建立一个树状结构如下:
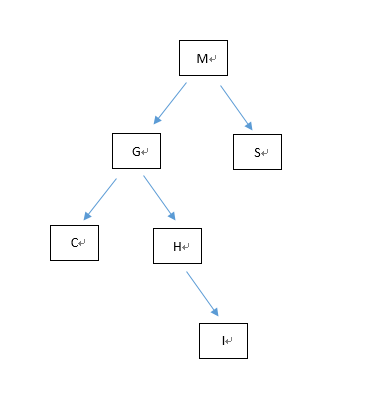
每个数据都由上面的方法尽心循环,上表中的数据叫变成了一个四层的树状结构,这个就可以理解为一个二叉树的数据结构。当再有查询任务的时候,最多只需要在每层进行一次查询判断,就可以准确定位。
显然上面的这种树状结构并不是最完美的,进过重新的排序,完全可以将结构由四层缩小到三层,如下图:
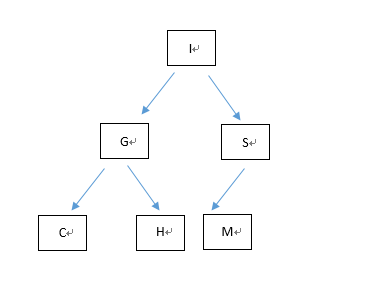
如此一来,如果每一个节点的分支为二,那么最优化的二叉树的层数就是log2N层,再进行查询操作的时候,查询操作为log2N次,时间复杂度就变成了O(log2N),也因此提高了查询效率。
当然实际的索引比这个要复杂的多,需要用专门的空间存储索引,实际的索引中存放的数据的指针,指向数据的存储物理地址,索引能告诉你去哪找到你需要的数据。
进一步,关于索引的几条注意事项也变得容易理解起来:
1、索引并非越多越好,因为维护索引本身就需要占用空间和资源。
2.索引应该建立在那些需要经常查询而变化不大的列上,应为对数据的增删改都会导致索引的重构,频繁的索引操作也会降低效率。
3、索引列并不支持模糊查询。
关于索引我相信未来还会遇到更多问题,到时候遇到了再说吧。
非科班伤不起啊,啥都要补课。




评论