发表于: 2017-11-23 23:15:49
1 551
今天做的事情:
将项目增加一个增加学生的功能,放入缓存。
service处理代码
public int addStudent(Student student) {
System.out.println("service 中的 student:"+student);
Jedis resource = jedis.getResource();
resource.set("student".getBytes(), SerializeUtil.serialize(student));
System.out.println("redis缓存的数据:"+resource.get("student".getBytes()));
return daoI.addStudent(student);
}
控制台信息
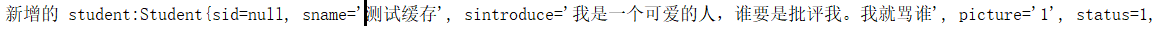
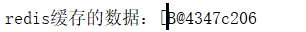
linux下的数据,存储的是二进制文件
准备了小课堂的内容,nginx的负载均衡。以下是主要点。
nginx 的 upstream目前支持 4 种方式的分配
1)、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
2)、weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
2)、ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
3)、fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
4)、url_hash(第三方)

upstream 每个设备的状态:
down 表示单前的server暂时不参与负载
weight 默认为1.weight越大,负载的权重就越大。
max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误
fail_timeout:max_fails 次失败后,暂停的时间。
backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
http://blog.csdn.net/xingchao416/article/details/53188729
对于压测这块,再做一点补充。
吞吐量如何计算?
我们在压测工具制作中,一直存在一个争议——吞吐量的计算。
在性能测试中,吞吐量的计算有两种常见的公式:
公式1: 吞吐量=并发数/平均响应时间
公式2: 吞吐量=请求总数/总时长
结论
1、 在单接口压测时,我们用“请求总数/总时长”得到吞吐量;然后再用“吞吐量*平均响应时间”得到实际并发,此举可用来观察系统实际承受的并发;
2、 在多接口压测时,由于短板效应,同一个流程中的所有接口获得的请求总数和总时长都一样,显然“请求总数/总时长”计算各个子接口的吞吐量不合适,所以改用“并发/平均响应时间”,其中的并发数应在压测工具中埋点统计,不可简单使用工具线程数。
结语
在性能测试平台的开发中,为了测试结果更接近现实,我们在吞吐量计算上改过三个版本,小伙伴们也有过几次激烈的讨论,正是对这种小细节的不断纠缠,我们对性能测试的认识也在不断刷新,原本以为正确的地方被颠覆,不理解的环节逐渐清晰,越琢磨越会发现性能测试的有趣。
如文中观点有理解不到位的地方,欢迎大家一起探讨指正。
收获:
使用缓存数据,Jmeter压测并发,看了一点第三方接口文档。




评论