发表于: 2017-11-22 23:39:41
1 698
今天完成的事情:
结尾任务六,可学习方面还有很多,在以后的任务中,多用用,,熟悉熟悉吧!
明天计划的事情:
开始任务七
遇到的问题:
1.memcached和redis都是非关系型数据库,同属键值存储系统。严格意义上来讲,Memcached并不能算作数据库系统,只能算作中间缓存系统,因为其并不能进行数据的持久化存储。
2.就称呼为memcached中缓存数据的生命周期,在不管存储时间的情况下,内存用完后,会先将里面最长时间没用的数据清除掉。
收获:
1.TPS
TPS(transaction per second)代表每秒执行的事务数量,可基于测试周期内完成的事务数量计算得出。
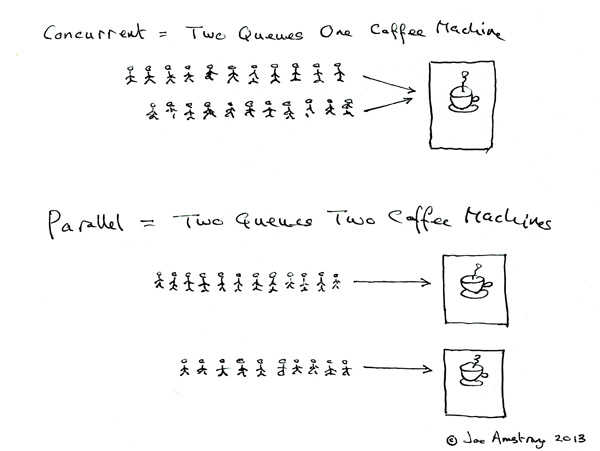
2.并发和并行的区别:
如果某个系统支持两个或者多个动作同时存在,那么这个系统就是一个并发系统。如果某个系统支持了两个或者多个动作同时执行,那么这个系统就是一个并行系统。并行系统和并发系统这两个定义之间的关键差异在于“存在”这个词。
在并发程序中可以同时拥有两个或者多个线程。这意味着,如果程序在单核处理器上运行,那么这两个线程将交替地换入或者换出内存。这些线程是同时“存在”的——每个线程都处于执行过程中的某个状态。如果程序能够并行执行,那么就一定是运行在多核处理器上。此时,程序中的每个线程都将分配到一个独立的处理器核上,因此可以同时运行。
总的来说,“并行”概念是“并发”概念的一个子集。也就是你编写一个拥有多个线程或者进程的并发程序,但如果没有多核处理器来执行这个程序,那么就不能以并行方式来运行代码。因此,凡是在求解单个问题时涉及多个执行流程的编程模式或者执行行为,都属于并发编程的范畴。
简单来说:
并发:交替做不同事的能力。或者是不同代码块交替执行的性能。
并行:同时做不同事的能力。或者是不同代码块同时执行的性能。
这个图就很简单的描述了并发和并行:
3.JMeter线程组中线程数,Ramp-Up Period,循环次数之间的设置概念
http://blog.csdn.net/hsd412237463/article/details/49929173
这篇博客里可以辅助我们刚学jmeter的理解理解。
4.非关系型数据库和关系型数据库区别,优势比较。
(1)非关系型数据库的优势:
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
(2)关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2)事务支持使得对于安全性能很高的数据访问要求得以实现。
5.memcached
(1)memcached的概念
缓存是一种常驻与内存的内存数据库,内存的读取速度远远快于程序在磁盘读取数据的速度。我们在设计程序的时候常常会考虑使用缓存,将经常访问的数据放到内存上面这样可以提高访问数据的速度,同时可以降低磁盘或数据库的压力。
memcached就是一款可以方便实现缓存的工具软件,memcached的优势在于以下几点:
1)实现分布式缓存(支持热部署),通过hashcode根据缓存服务器ip智能分配将数据缓存到的服务器上。
2)实现最近最少访问的数据优先被移除缓存。
3)快速找到适配的存储空间,避免内存的浪费。
4)使用键值对存储数据,方便读取修改等缓存的管理。
5)socket通信,缓存服务器和应用服务器分离。
等等。
(2)memcached的缓存机制
memcached为了提高数据的存储速度,在安装启动memcached服务的时候,他会自动将分配给memcached的内存分隔为大小不一致的很多块。每当任意一个大小的需要缓存的数据提交过来的时候memcached将会自动找到符合这个数据大小最适合的内存块,然后把数据放到这个块里面。这种方式不仅可以降低内存的浪费同时可以减少了内存分配的时间了。
如果memcached里面的内存已经被使用完了,还需要向里面添加数据的时候,memcached将会把存入缓存中最长时间没有用的数据清除掉。
每次向缓存中添加数据的时候都会带上该数据的有效时间,如果超过了这个有效时间那么缓存的数据自动失效了。
6.redis
(1)NoSQL
NoSQL是Not-Only-SQL的缩写,是被设计用来替换传统的关系型数据库在某些领域的用,特别针对web2.0站点以及大型的SNS网站,用来满足高并发、大数据的应用需求,常见的NoSQL数据库系统有HBase(Hadoop数据库,基于列存储)、MongoDB(文档型数据库,采用类型与JSON的BSON语法存储记录)、Redis/Memcached(键值存储数据库)等类型。
(2)redis的介绍
Redis是NoSQLogic系列数据库中,和Memcached最为相似的数据库系统,同属键值存储系统。严格意义上来讲,Memcached并不能算作数据库系统,只能算作中间缓存系统,因为其并不能进行数据的持久化存储。Redis的字面意思是:远程字典服务器(REmote DIctionary Server),和Memcached相比较,提供了更加丰富的数据类型,更被认为是一种数据结构服器。
7.redis和memcached比较
和Memcached相比,Redis的优势十分明显。
(1)数据类型:Redis支持更丰富的数据类型,包括字符串(string)、列表(list:可用作队列、堆栈)、集合(set:可以进行集合的运算)、有序集合(sorted set)、哈希表(hash)等,而Memcached仅支持字符串。
(2)对象大小:Redis支持的对象大小最大支持1GB,而Memcached仅为1MB,仅从这个角度来讲,就很有使用Redis替换Memcached的必要。
(3)分片(Sharding):可以将数据离散地存储在不同的物理机器上,以克服单台机器的内存大小限制。Memcached是在服务器实现实现分片的,而Redis需要借助于Jedis实现客户端分片,Jedis是Redis官方推荐的使用Java访问Redis的方式。
使用Jedis的分片机制,存储一批数据,在不同的Redis服务器上存储着这批数据的不同部分.而这对客户端来说,而完全透明的,看不到这种差别。另外需要注意,使用Spring Data Redis进行客户端操作时,不提供对分片支持。
(4)持久化:Redis能够将添加到内存中的数据持久化到磁盘,而Memcached则只能充当一个功能相对有限的缓存中间件角色。
8.nginx的五种负载算法模式
(1)轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
(2)weight (权重)
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
weight 默认为1。weight越大,负载的权重就越大。
(3)ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
(4)fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误
fail_timeout:max_fails次失败后,暂停的时间。
(5)url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。




评论