发表于: 2017-11-20 23:45:05
1 761
今天做的事情:
第一个错误: 在controller中写缓存代码。有疑惑怎么将缓存数据转到jsp,姚远师兄点醒我,因为做的项目比较简单,一直忽略了有业务或者别的操作在service处理,在service缓存数据,再将数据返回Controller,发送到 jsp页面 。
CacheServiceImpl层代码:
public List weblist() {
List weblist = daoI.weblist();
if(weblist!=null){
memCachedClient.set("weblist", weblist);
System.out.println(memCachedClient.get("weblist")+"service 中的 缓存数据 ------------");
Object weblist1 = memCachedClient.get("weblist");
}
return null;
写了一点代码测试一下有没有加入缓存。

异常在于没有在实体类上实现Serializable。
更新的CacheServiceImpl 中的代码:
public List javalist() {
List javalist1 =null;
if(MemcachedUtil.get("javalist")!=null){
List javalist = (List) MemcachedUtil.get("javalist");
System.out.println("直接返回缓存中的javalist");
return javalist;
}else {
List javalist = daoI.javalist();
if (javalist != null) {
MemcachedUtil.put("javalist", javalist, 60);
javalist1 = (List) MemcachedUtil.get("javalist");
System.out.println("返回从数据库查询到得javalist,然后放入缓存");
}
return javalist1;
}
}
public List anzhuolist() {
List anzhuolist1 =null;
if(MemcachedUtil.get("anzhuolist")!=null){
List anzhuolist = (List) MemcachedUtil.get("anzhuolist");
System.out.println("直接返回缓存中的anzhuolist");
return anzhuolist;
}else {
List anzhuolist = daoI.anzhuolist();
if (anzhuolist != null) {
MemcachedUtil.put("anzhuolist", anzhuolist, 60);
anzhuolist1 = (List) MemcachedUtil.get("anzhuolist");
System.out.println("返回从数据库查询到得anzhuolist,然后放入缓存");
}
return anzhuolist1;
}
}
controller 层的代码 :
List javalist = cacheServiceI.javalist();
logger.info("javalist 的数据:"+javalist);
model.addAttribute("javalist",javalist);
List anzhuolist = cacheServiceI.anzhuolist();
logger.info("anzhuolist 的数据:"+anzhuolist);
model.addAttribute("anzhuolist",anzhuolist);
控制台信息:

仔细看上面代码就可以发现,先从缓存查询,没有的话,从数据库查出来,放到缓存。weblist和javalist,是之前测试过的,所以信息显示从缓存中拿。而anzhuolist,是第一次查询,所以显示从数据库中查询,放入缓存。
下午和韬哥聊增加,了解清楚目的是为了在数据库新增数据测试缓存是否能返回所有数据,在数据库增加几条数据,发现确实缓存返回的数据没有这几条。于是又将代码进行修改。
public List anzhuolist() {
List anzhuolist = daoI.anzhuolist();
List anzhuolist1 =null;
if(MemcachedUtil.get("anzhuolist")!=null &&MemcachedUtil.get("anzhuolist").equals(anzhuolist)){
List anzhuolist2 = (List) MemcachedUtil.get("anzhuolist");
System.out.println("直接返回缓存中的anzhuolist");
return anzhuolist2;
}else {
if (anzhuolist != null) {
MemcachedUtil.replace("anzhuolist", anzhuolist, 60);
anzhuolist1 = (List) MemcachedUtil.get("anzhuolist");
System.out.println("返回从数据库查询到得anzhuolist,然后放入缓存");
}
return anzhuolist1;
}
}
多加一个判断缓存里面和从数据库查询结果是否一致,不一致的话,进行一个替换操作,replace,相当于修改,这样做增加操作,就能实时得更新缓存里的数据。
介绍生产环境中memcached的使用场景,主要是memcached存储关系型数据库mysql的查询结果,比如网站的下载排名等,这种查询每次从关系型数据库中查询,会增加磁盘的I/O开销,而这个排名不需要实时的更新,所以我们把这个结果存在memcached中,memcached是把数据序列化存放在内存中,我们可以设置超时时间,然后周期性的从关系型数据库查询新的结果更新到memcached中。
其中的过程是这样的:
(1)检查用户请求的数据是缓存中是否有存在,如果有存在的话,只需要直接把请求的数据返回,无需查询数据库。
(2)如果请求的数据在缓存中找不到,这时候再去查询数据库。返回请求数据的同时,把数据存储到缓存中一份。
(3)保持缓存的“新鲜性”,每当数据发生变化的时候(比如,数据有被修改,或被删除的情况下),要同步的更新缓存信息,确保用户不会在缓存取到旧的数据。
接下来做nginx的负载均衡,使用tomcat和resin这两个web容器,首先修改resin中的conf的resin.properties文件。将端口号修改为8090.而tomcat默认的就是8080,不需要修改。
部署两台WEB,使用Nginx的Upstream来做负载。重新压测。
之前都在服务器配置了resin和tomcat,所以就很方便了,修改端口号仍然不能访问的原因,是没有在阿里云服务器上开放8090端口。
nginx的nginx.conf文件:
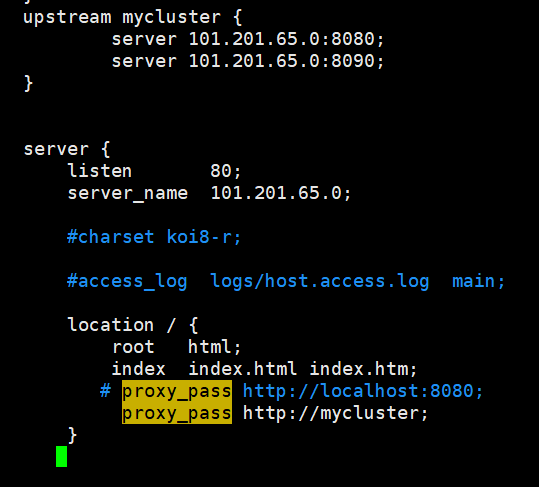
有一点需要注意,要把upstream配置在http{}里面,而我之前不小心放在server中。所以重启时会提示错误。然后将项目修改index页面,再分别打包放在tomcat和resin下面。
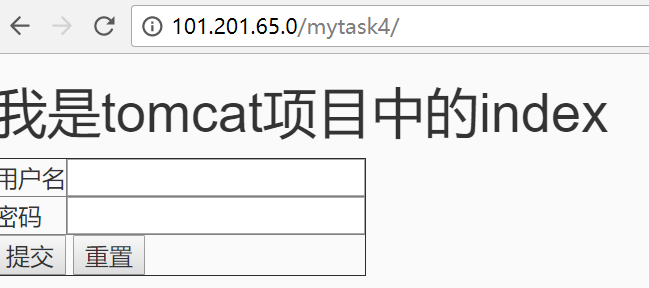
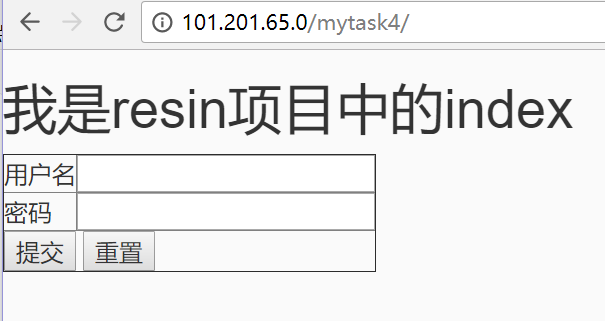
nginx的负载均衡已经实现,可以参考一下这个博客:https://yq.aliyun.com/ziliao/1623
再来了解一下nginx 的 upstream目前支持 4 种方式的分配
upstream 每个设备的状态:
down 表示单前的server暂时不参与负载
weight
max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误
fail_timeout:max_fails 次失败后,暂停的时间。
backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
了解一下redis: Redis作为一个高性能的key-value数据库具有以下特征:
多样的数据模型
持久化
主从同步
Redis支持丰富的数据类型,最为常用的数据类型主要由五种:String、Hash、List、Set和Sorted
Set。Redis通常将数据存储于内存中,或被配置为使用虚拟内存。Redis有一个很重要的特点就是它可以实现持久化数据,通过两种方式可以实现数据持久化:使用RDB快照的方式,将内存中的数据不断写入磁盘;或使用类似MySQL的AOF日志方式,记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反。
Redis支持将数据同步到多台从数据库上,这种特性对提高读取性能非常有益。
安装步骤,
下载文件.,解压并进入目录。
make, cd src make install -prefix=/usr/local/redis
要将redis.comf 移到这个redis下的etc里面、
启动服务的话: /usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf
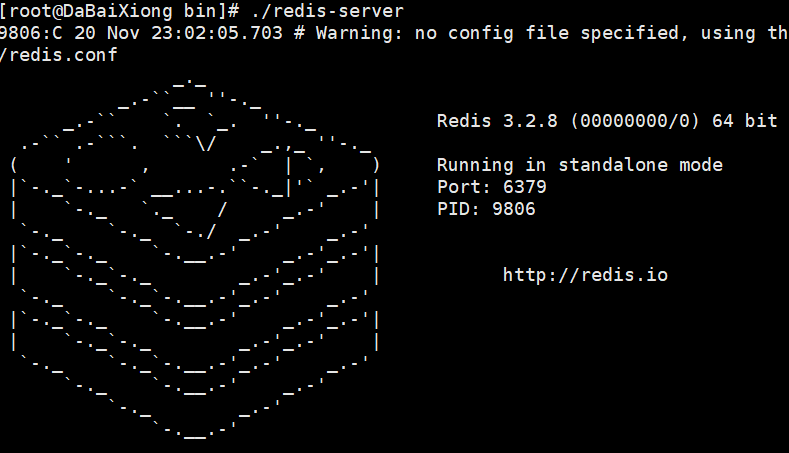
在进入redis下的bin, redis-cli 就可以进入


redis-benchmark:redis性能测试工具
redis-check-aof:检查aof日志的工具
redis-check-dump:检查rdb日志的工具
redis-cli:连接用的客户端
redis-server:redis服务进程
还有redis的配置:
daemonize:如需要在后台运行,把该项的值改为yes
pdifile:把pid文件放在/var/run/redis.pid,可以配置到其他地址
bind:指定redis只接收来自该IP的请求,如果不设置,那么将处理所有请求,在生产环节中最好设置该项
port:监听端口,默认为6379
timeout:设置客户端连接时的超时时间,单位为秒
loglevel:等级分为4级,debug,revbose,notice和warning。生产环境下一般开启notice
logfile:配置log文件地址,默认使用标准输出,即打印在命令行终端的端口上
database:设置数据库的个数,默认使用的数据库是0
save:设置redis进行数据库镜像的频率
rdbcompression:在进行镜像备份时,是否进行压缩
dbfilename:镜像备份文件的文件名
dir:数据库镜像备份的文件放置的路径
slaveof:设置该数据库为其他数据库的从数据库
masterauth:当主数据库连接需要密码验证时,在这里设定
requirepass:设置客户端连接后进行任何其他指定前需要使用的密码
maxclients:限制同时连接的客户端数量
maxmemory:设置redis能够使用的最大内存
appendonly:开启appendonly模式后,redis会把每一次所接收到的写操作都追加到appendonly.aof文件中,当redis重新启动时,会从该文件恢复出之前的状态
appendfsync:设置appendonly.aof文件进行同步的频率
vm_enabled:是否开启虚拟内存支持
vm_swap_file:设置虚拟内存的交换文件的路径
vm_max_momery:设置开启虚拟内存后,redis将使用的最大物理内存的大小,默认为0
vm_page_size:设置虚拟内存页的大小
vm_pages:设置交换文件的总的page数量
vm_max_thrrads:设置vm IO同时使用的线程数量
遇到的问题:
已经说明并解决了。
收获:
已经使用memcached进行缓存,明天替换成redis,成功之后,压测页面。就可以收尾。




评论