发表于: 2017-10-25 18:55:59
1 925
今日完成:
win7下使用nginx就很简单了
http://blog.csdn.net/jacson_bai/article/details/46388775
开启后测试

这里使用2个web容器,jetty和tomcat.
先配置负载均衡
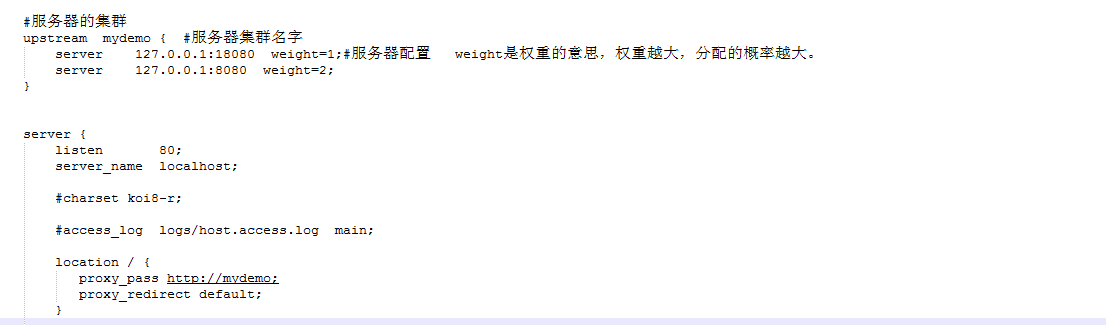
配置好后重启nginx,但是我发现死活不起作用!我TM明明重启了啊!
坑来了!
nginx -s reload 改变配置文件的时候,重启nginx工作进程,来使配置文件生效
等会儿我将jetty端口设置成18080,tomcat保持不变,为了区分在欢迎页面将jetty中的页面加点标识符,方便区分.
先启动tomcat测试OK
修改jetty端口
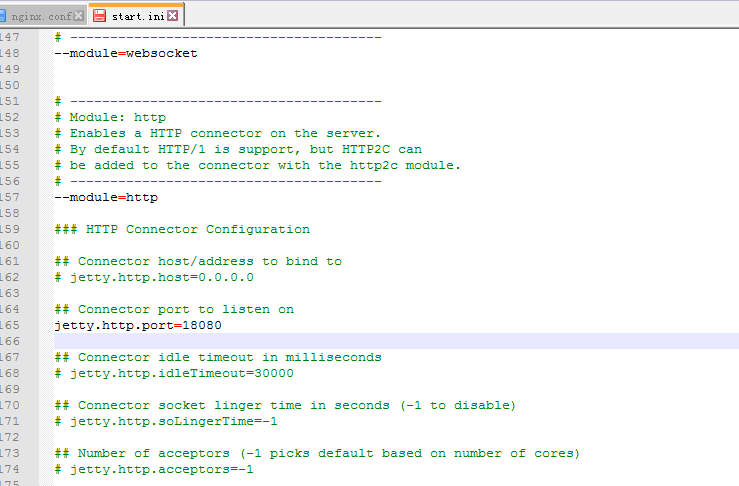
启动测试!

反复刷新测试效果,满足条件开始压测
条件依旧并发量40,手动测试1分钟

使用nginx负载均衡,不使用memcached缓存,压测JSP

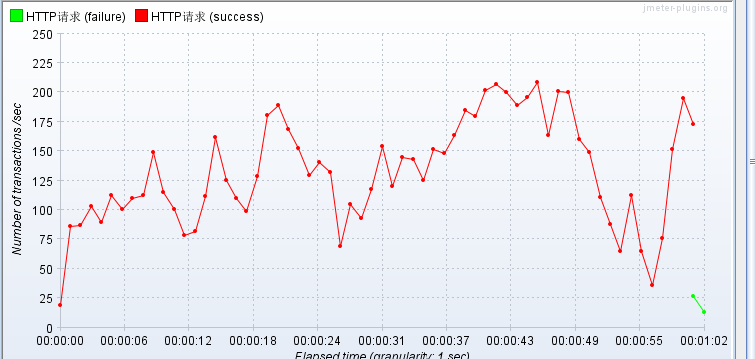
不使用nginx负载均衡,不使用memcached缓存,压测JSP

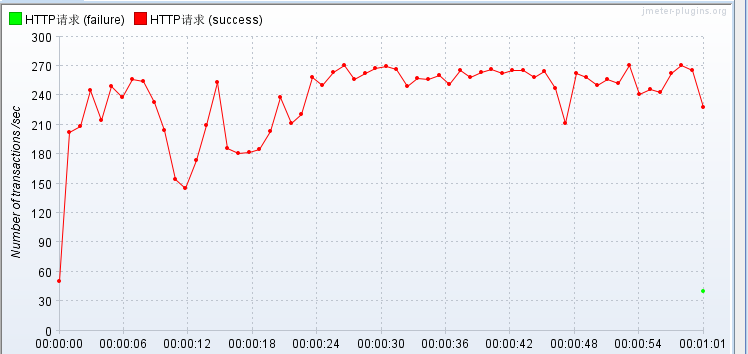
这里测试效果并不理想....猜测原因两台都部署在本地有关..电脑吃不消了.换一台到远程测试
权重比如下,本地的优先级较高,远程访问速度相对较慢,这里起到一个备胎的作用!

使用nginx负载均衡(1台本地1台远程),不使用memcached缓存,压测JSP

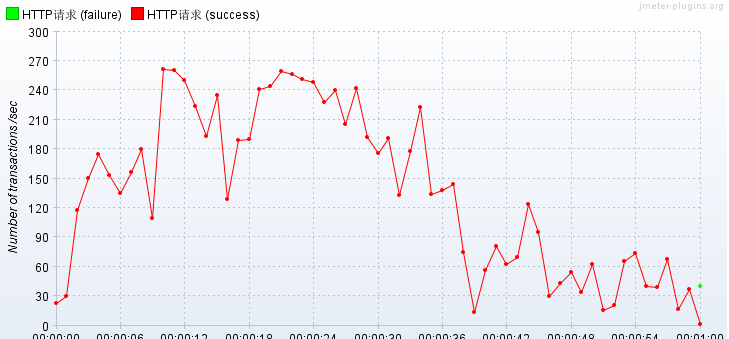
马马虎虎..比之前好了很多很多,但是曲线很诡异..
开始学习Redis,因为这里是替换Memcache猜想两者作用大概相同,而我们对其进行操作也是需要
①安装Redis服务端
②使用java程序对其缓存空间进行操作!
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
windows 安装简单使用教程
http://blog.csdn.net/matiantian666/article/details/55048282
在使用redis-server.exe redis.conf命令运行后出现如下画面 redis启动

强调3次,不能关!不能关!不能关!
一旦关闭窗口程序也就停止运行了!
再启动一个cmd命令窗,输入redis-cli.exe -h 127.0.0.1 -p 6379 -a 123456 ,其中 127.0.0.1是本地ip,6379是redis服务端的默认端口,123456是redis密码,出现下图就说明redis搭建成功了,这里做了一个简单的拿值取值的测试
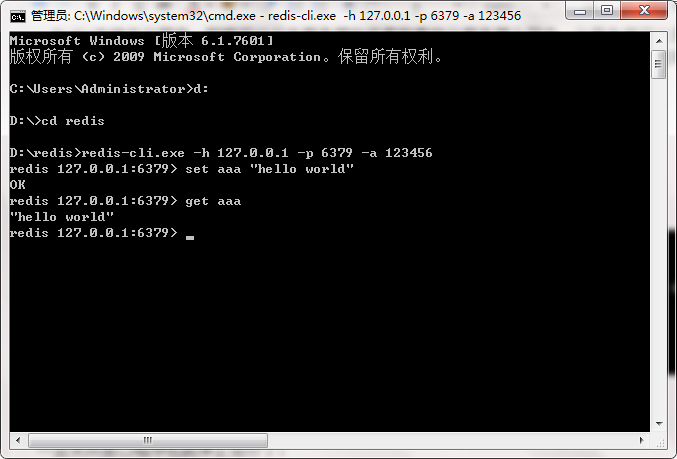
http://database.51cto.com/art/201505/477692.htm
推荐了几款可视化的redis管理工具,这里我测试了一个Redis Desktop Manager
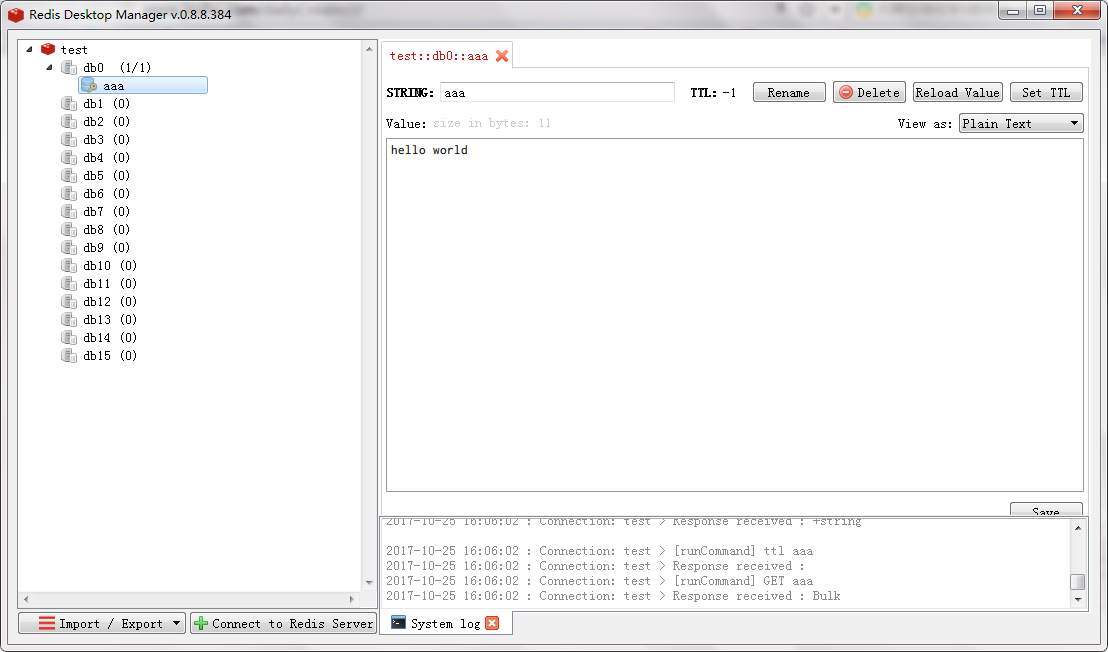
刚才保存的值还在!
那怎么用JAVA去操作redis实现数据的增删改查呢?这两篇博客写都非常棒!
http://www.cnblogs.com/edisonfeng/p/3571870.html
http://www.cnblogs.com/liuling/p/2014-4-19-04.html
首先添加依赖jar包,这里我们操作redis的核心对象为Jedis!
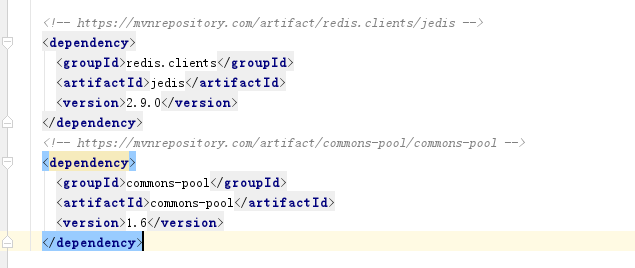
因为一个个连接很麻烦,这里手动设置一个连接池,功能好比C3P0
package cn.ssm.test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public final class RedisClient {
//Redis服务器IP
private static String ADDR = "127.0.0.1";
//Redis的端口号
private static int PORT = 6379;
//访问密码
private static String AUTH = "123456";
//控制一个pool最多有多少个状态为idle(空闲的)的jedis实例,默认值也是8。
private static int MAX_IDLE = 200;
//等待可用连接的最大时间,单位毫秒,默认值为-1,表示永不超时。如果超过等待时间,则直接抛出JedisConnectionException;
private static int MAX_WAIT = 10000;
private static int TIMEOUT = 10000;
//在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的;
private static boolean TEST_ON_BORROW = true;
private static JedisPool jedisPool = null;
/**
* 初始化Redis连接池
*/
static {
try {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxIdle(MAX_IDLE);
config.setMaxWaitMillis(MAX_WAIT);
config.setTestOnBorrow(TEST_ON_BORROW);
jedisPool = new JedisPool(config, ADDR, PORT, TIMEOUT, AUTH);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取Jedis实例
* @return
*/
public synchronized static Jedis getJedis() {
try {
if (jedisPool != null) {
Jedis resource = jedisPool.getResource();
return resource;
} else {
return null;
}
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 释放jedis资源
* @param jedis
*/
public static void returnResource(final Jedis jedis) {
if (jedis != null) {
jedisPool.returnResource(jedis);
}
}
}
测试失败

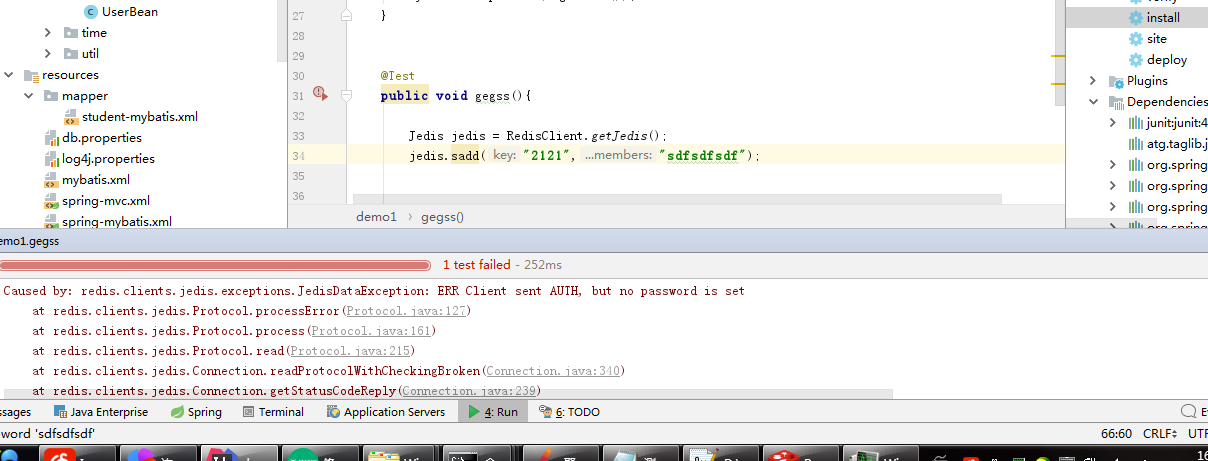
这里提示我认证用户没有设置密码,我们进去手动设置一下
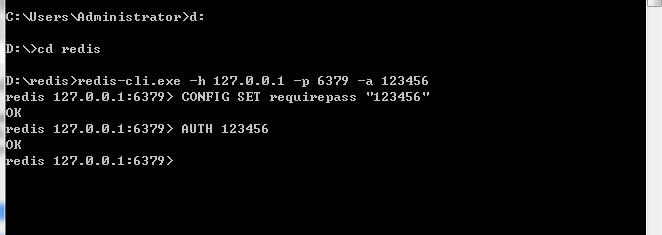
再测试OK!
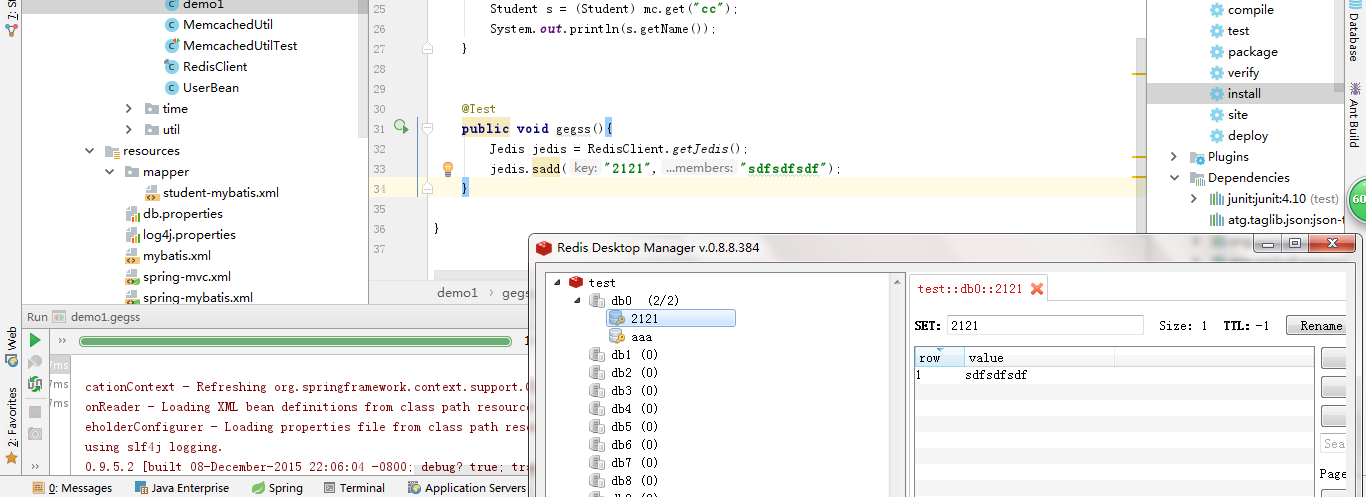
但是这里我想要存放的还是学生对象,而不是普通数据类型,尝试一后 直接报红
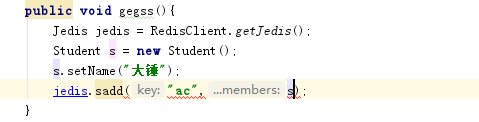
这里就需要自己创建一个序列化和反序列化工具,在我们存储时,将对象进行序列化存储,当取出时自然而然也要进行反序列化!当然了,我们自己的JAVA对象和之前memcached一样实现序列化接口
简单一点的说
把对象转换为字节序列的过程称为对象的序列化;把字节序列恢复为对象的过程称为对象的反序列化
创建序列化和反序列化工具
package cn.ssm.test;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class SerializeUtil {
public static byte[] serialize(Object object) {
ObjectOutputStream oos = null;
ByteArrayOutputStream baos = null;
try {
//序列化
baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(object);
byte[] bytes = baos.toByteArray();
return bytes;
} catch (Exception e) {
}
return null;
}
public static Object unserialize(byte[] bytes) {
ByteArrayInputStream bais = null;
try {
//反序列化
bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
} catch (Exception e) {
}
return null;
}
}
注意这里的构造方法,存放时我们的键也要是byte字节类型哦!
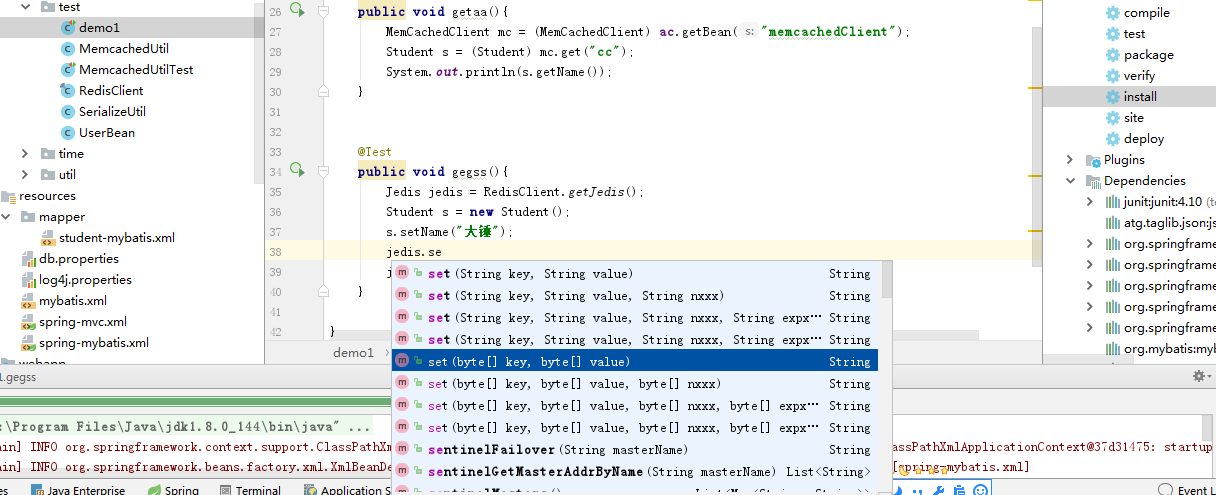
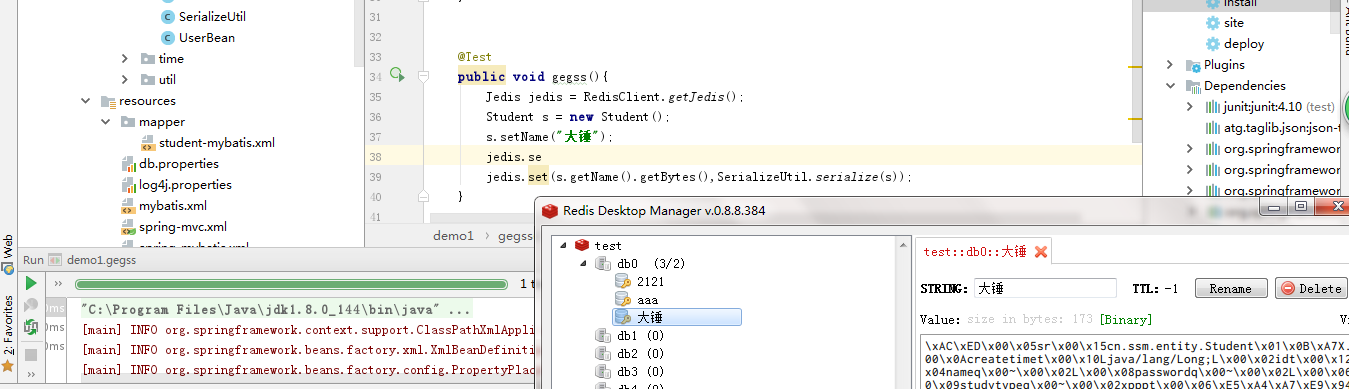
测试存放和取出
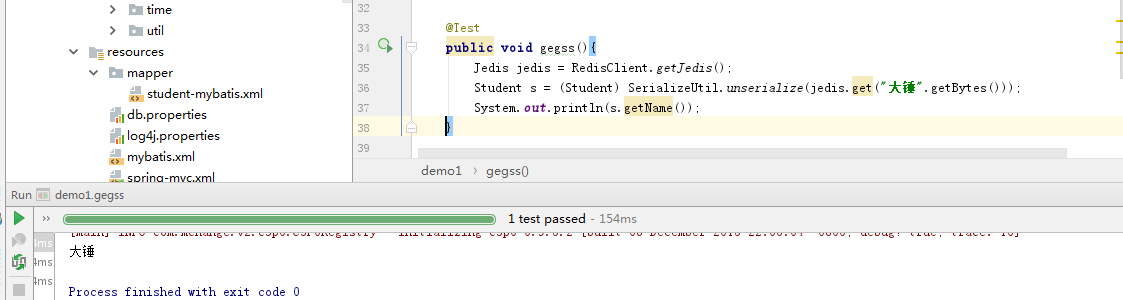
但是春天这么好的一个框架放在这为何不注入呢?
当然了这里并没有使用spring-data-redis进行集成整合
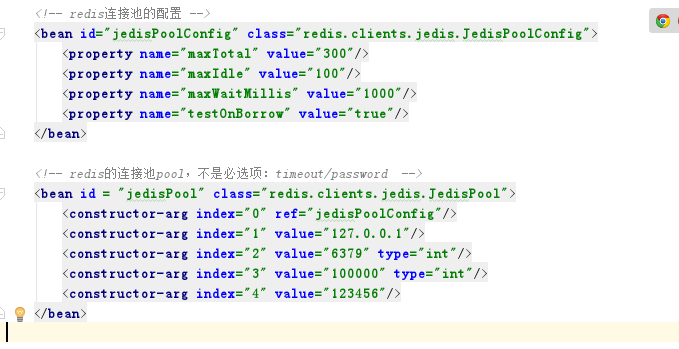
service层判定条件和memcached一样
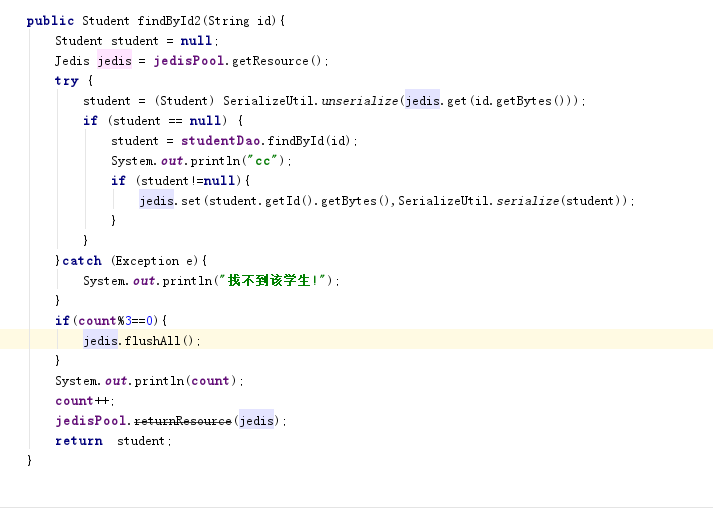
测试结果符合!

准备压测了!!!!
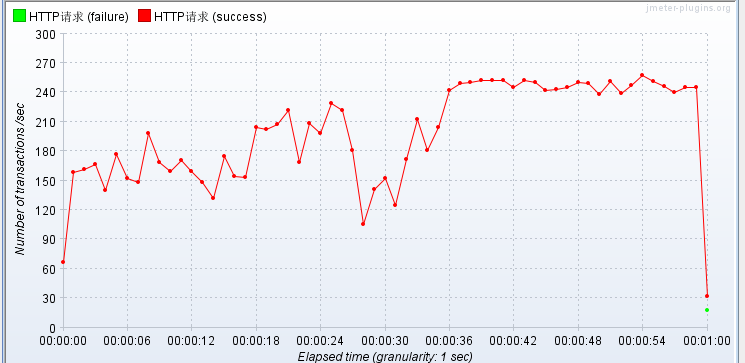
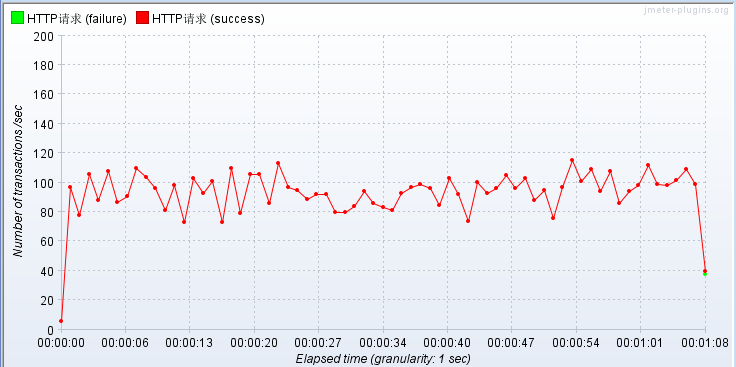
条件依旧并发量40,手动测试1分钟
使用Redis缓存 压测JSP!

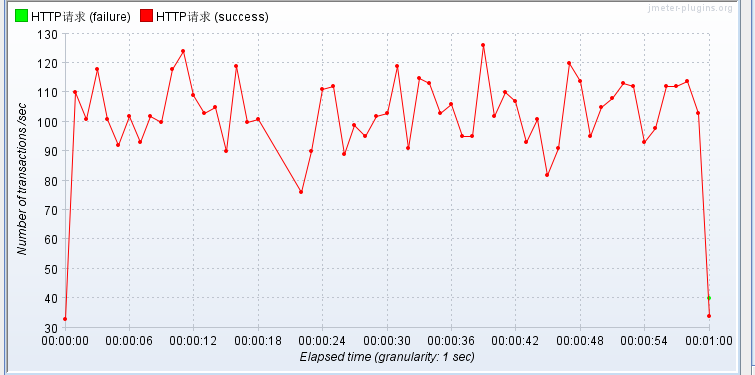
不使用Redis缓存 压测JSP!

不怎么滴...
先完成一下模拟缓存穿透.什么是缓存穿透呢?
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库中查询,如果大量空值高并发一起访问那么就会对后端系统造成很大的压力。这就叫做缓存穿透.
也就是每次提交都用空值去提交,压测试一下

如何避免呢?
http://www.cnblogs.com/moonandstar08/p/5365507.html
很多博客都提到了一个简单的方法.在无效访问值不多的情况下,当数据库查询值为空时返回过程中,将该访问名称标记存入缓存中,那么当他下一次访问时会查到缓存内直接返回,不会对数据库操作,从而避免了缓存穿透.
但是要注意
第一是空值做了缓存,意味着缓存系统中存了更多的key-value,也就是需要更多空间(有人说空值没多少,但是架不住多啊),解决方法是我们可以设置一个较短的过期时间。
第二是数据会有一段时间窗口的不一致,假如,Cache设置了5分钟过期,此时Storage确实有了这个数据的值,那此段时间就会出现数据不一致,解决方法是我们可以利用消息或者其他方式,清除掉Cache中的数据.
明日计划:把之前的报告整理下准备交task6了,后天要小课堂了,第一次讲准备准备
问题:nginx的负载均衡优化还得研究研究
收获:redis的使用




评论