发表于: 2017-10-24 16:02:13
3 836
今日完成:
学习Memcache缓存的概念.
简单一点讲,实际执行效果就是当我们需要去操作数据库时,
if(在缓存空间中找不到该数据,那么就去数据库中找){
if(在数据库中也找不到){
直接返回并提示没有该值
}else{
在数据中找到了数据!;
在返回结果时,一并把数据放入缓存
}
}else{
直接在缓存中找到数据,直接返回.避免了对数据的操作从而缩短响应时间!
}
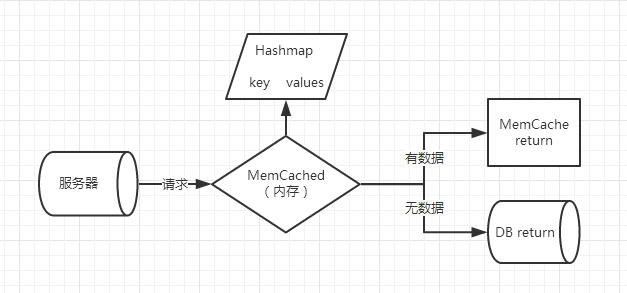
但是关于具体操作流程,需要安装软件引进jar包都是一头雾水,一步步来先!
安装memcached for Windows
操作流程如下
http://blog.csdn.net/zhaotengfei36520/article/details/41315329
http://blog.csdn.net/l1028386804/article/details/61417166
启动成功
参数介绍
-p 监听的端口
-l 连接的IP地址, 默认是本机
-d start 启动memcached服务
-d restart 重起memcached服务
-d stop|shutdown 关闭正在运行的memcached服务
-d install 安装memcached服务
-d uninstall 卸载memcached服务
-u 以的身份运行 (仅在以root运行的时候有效)
-m 最大内存使用,单位MB。默认64MB
-M 内存耗尽时返回错误,而不是删除项
-c 最大同时连接数,默认是1024
-f 块大小增长因子,默认是1.25
-n 最小分配空间,key+value+flags默认是48
-h 显示帮助
这里就改了一下端口,重启服务


使用Telnet可以很直观的使用Memcache,本地启动telnet方法.
https://jingyan.baidu.com/article/ae97a646b22fb6bbfd461d19.html
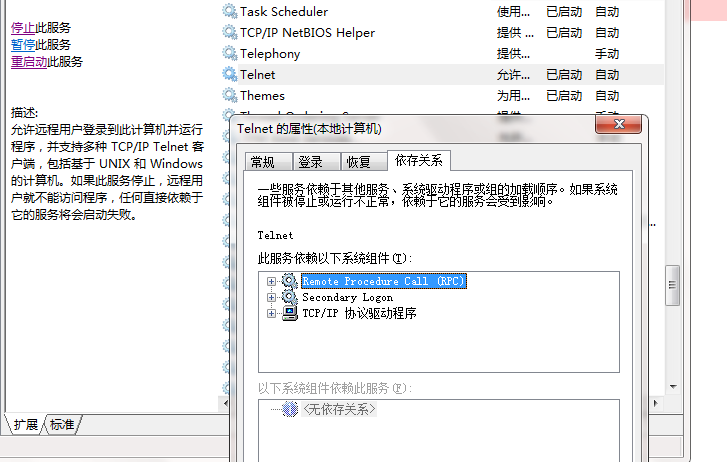
这边在启动telnet时可能报错,打开telnet属性的依赖关系页面,看看哪些服务没开手动开一下
启动后使用在CMD界面输入Telnet "你本地的IP地址,当然也可以输入远程的IP地址" 11210(memcached端口号,上面我手动设置成了11210)
回车后进入空白页面按下ctrl+],再按一次回车,就可以看见memcached缓存的内容了,当然我这里是空的...
使用命令对缓存空间进行操作
https://jingyan.baidu.com/article/f79b7cb310b6079144023e8f.html
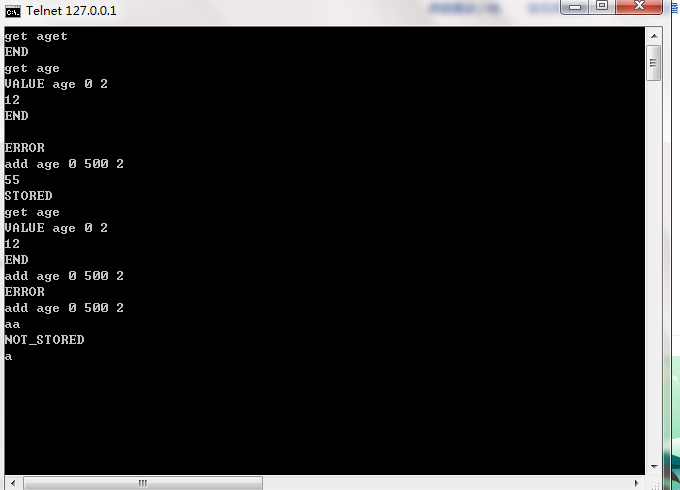
做了个简单的测试!
在这里我们可以把memcached当作当初学习数据库一样,数据库的存储内容是在我们的硬盘内,而memcached存储的内容就在我们当前的内存中!
在cmd命令进入程序使用telnet操作之后,就好比当初使用mysql指令进入数据库操作一样,但当时怎么通过JAVA程序去操作数据库的呢?JDBC?
OK!没错!那么相似的使用JAVA程序操作memcahed就得使用类似于JDBC的工具了!
JAVA使用MemcacheUtil工具 ! 像当初一样memcached要依赖jar包,手动下载后手动添加maven库,教程如下
http://www.cnblogs.com/mycifeng/p/5882509.html

创建核心工具类,现成的轮子,操作核心对象MemCachedClient,配置核心对象SockIOPool!
package cn.ssm.test;
import com.danga.MemCached.MemCachedClient;
import com.danga.MemCached.SockIOPool;
public class MemcachedUtil {
/**
* memcached客户端单例
*/
private static MemCachedClient cachedClient = new MemCachedClient();
/**
* 初始化连接池
*/
static {
//获取连接池的实例
SockIOPool pool = SockIOPool.getInstance();
//服务器列表及其权重
String[] servers = {"127.0.0.1:11210"};
Integer[] weights = {3};
//设置服务器信息
pool.setServers(servers);
pool.setWeights(weights);
//设置初始连接数、最小连接数、最大连接数、最大处理时间
pool.setInitConn(10);
pool.setMinConn(10);
pool.setMaxConn(1000);
pool.setMaxIdle(1000*60*60);
//设置连接池守护线程的睡眠时间
pool.setMaintSleep(60);
//设置TCP参数,连接超时
pool.setNagle(false);
pool.setSocketTO(60);
pool.setSocketConnectTO(0);
//初始化并启动连接池
pool.initialize();
//压缩设置,超过指定大小的都压缩
// cachedClient.setCompressEnable(true);
// cachedClient.setCompressThreshold(1024*1024);
}
private MemcachedUtil(){
}
public static boolean add(String key, Object value) {
return cachedClient.add(key, value);
}
public static boolean add(String key, Object value, Integer expire) {
return cachedClient.add(key, value, expire);
}
public static boolean put(String key, Object value) {
return cachedClient.set(key, value);
}
public static boolean put(String key, Object value, Integer expire) {
return cachedClient.set(key, value, expire);
}
public static boolean replace(String key, Object value) {
return cachedClient.replace(key, value);
}
public static boolean replace(String key, Object value, Integer expire) {
return cachedClient.replace(key, value, expire);
}
public static Object get(String key) {
return cachedClient.get(key);
}
}
一个简单测试!
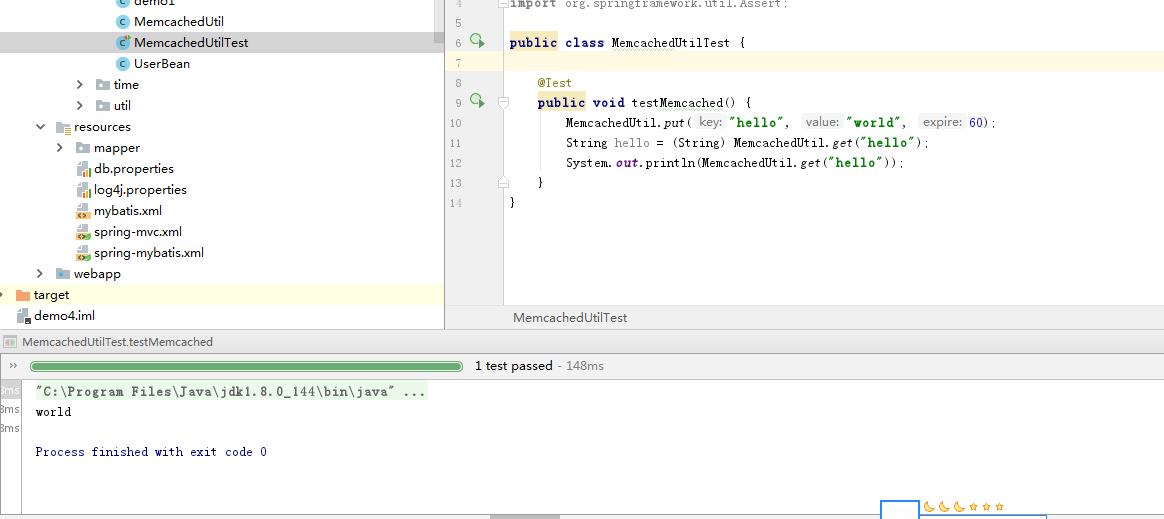
再用telnet测试
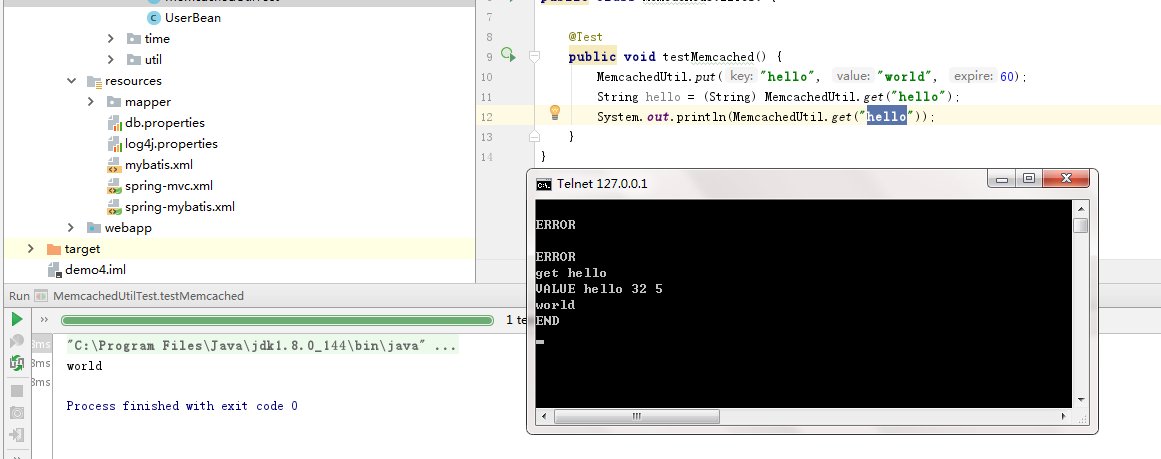
OK,但是这里仅仅能存放普通对象类型,而我需要的对student类进行存取,且我们还有令人愉快的春天框架,怎么把工具和spring整合呢?
首先!想要将实体类对象进行存放进缓存或拿取,就得对我们的实体类进行序列化!

测试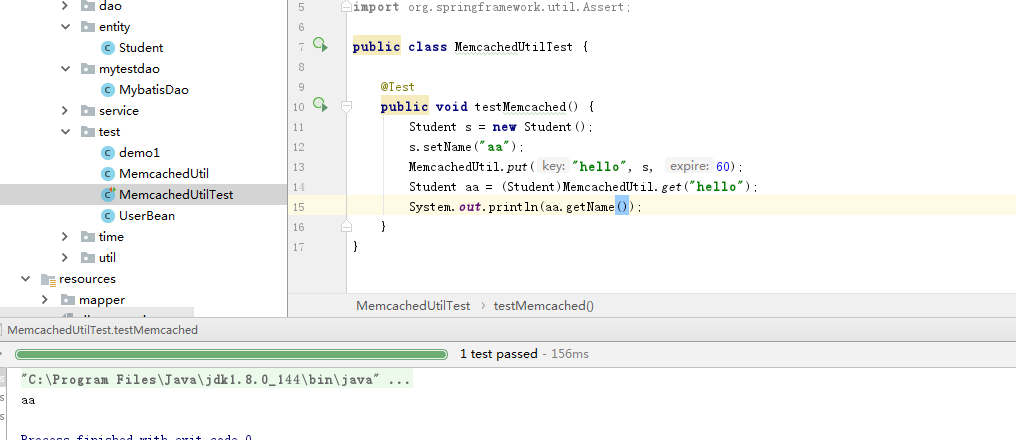
但是什么是序列化,为什么一般要在实现序列化的同时重写 hashcode、equals 方法.
http://blog.csdn.net/tengdazhang770960436/article/details/53436334 纯干货文章!
1.序列化是干什么的?
简单的来说就是为了保存各个对象在内存中的状态(也就是实例的变量,不是方法),并且可以把保存的对象状态读出来。虽然你可以用你自己的各种各样的方法来保存 object states,但是java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
2.什么情况下需要序列化
1. 当你想把内存中的对象状态保存到一个文件或者是数据中的时候;
2. 当你想用 socket 在网络中传输对象的时候;
3. 当你想通过 RMI 传输对象的时候;
3.为什么序列化对象通常要重写 hashCode 和 equals方法
2个内容完全一样的对象,在我们“人”看来就是一样的对象,但是计算机不这么认为,为了保证对象在进行比较时候符合人们的思维习惯,所以我们需要重写这2个方法。
在向 set 这种集合中添加对象的时候,set 要求对象都是不重复的,这个检查重复的过程,首先是检查对象的 hashCode() 值,如果这个值一致的话再去通过 equals 方法进行比较,如果 equals方法返回true,那么这个对象就不会被加入到 set 当中。
Spring 大法好! 将我们的memcached注入!
- <?xml version="1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://www.springframework.org/schema/beans
- http://www.springframework.org/schema/beans/spring-beans.xsd">
- <bean id="memcachedPool" class="com.danga.MemCached.SockIOPool"
- factory-method="getInstance" init-method="initialize">
- <constructor-arg>
- <value>neeaMemcachedPool</value>
- </constructor-arg>
- <property name="servers">
- <list>
- <value>127.0.0.1:11210</value>
- </list>
- </property>
- <property name="initConn">
- <value>20</value>
- </property>
- <property name="minConn">
- <value>10</value>
- </property>
- <property name="maxConn">
- <value>50</value>
- </property>
- <property name="nagle">
- <value>false</value>
- </property>
- <property name="socketTO">
- <value>3000</value>
- </property>
- </bean>
- <bean id="memcachedClient" class="com.danga.MemCached.MemCachedClient">
- <constructor-arg>
- <value>neeaMemcachedPool</value>
- </constructor-arg>
- </bean>
- </beans>
测试
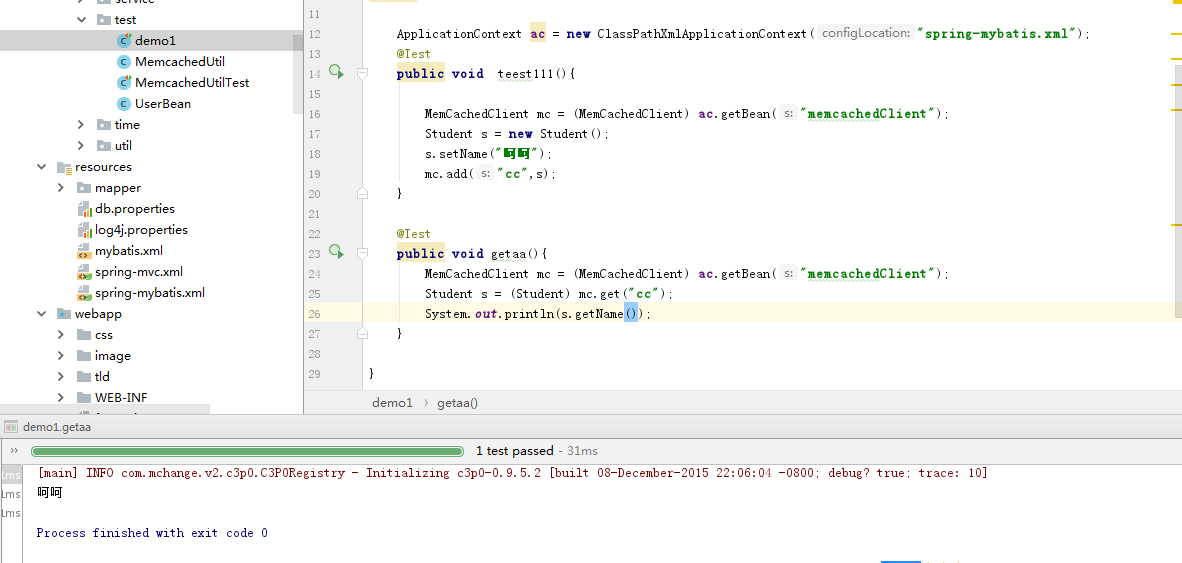
OK基本已经可以操作了!
可以开始步骤2,这里因为我们在压测的时候使用jmeter访问的请求方式和数据是固定的,不是动态的.那么第一访问后,后续的请求方式全部一样就会导致后续拿值全是从缓存空间里去拿,并不能实现更加真实有效的使用memcacahe的效果
为了实现这种效果,采用志荣师兄给的测试方式!我们在service层 手动去定义一个计数值count,每访问一次自增1,每当该值达到能被3整除的时候,手动对缓存空间进行清空,这样来达到一个模拟的效果!
service层代码修改如下
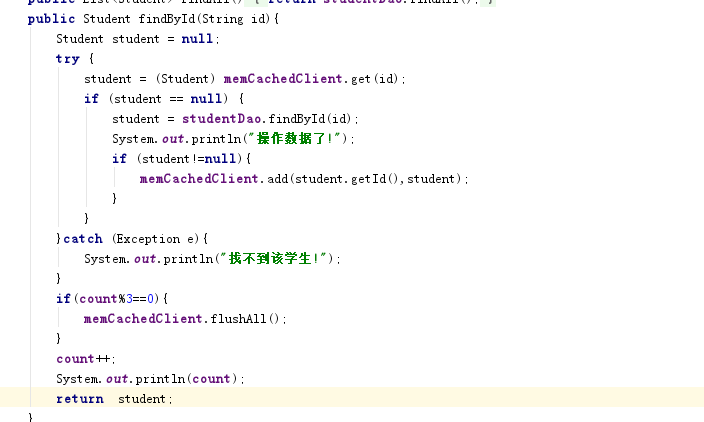
手动测试结果
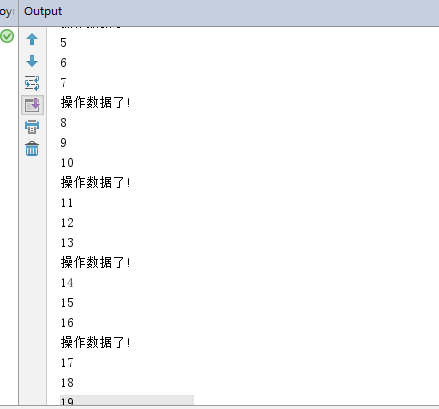
符合之前定下的逻辑标准,删除控制台打印开始压测! 线程属性如下:并发量40,手动测试1分钟访问效果!

报告如下: 使用memcached缓存,压测JSP!

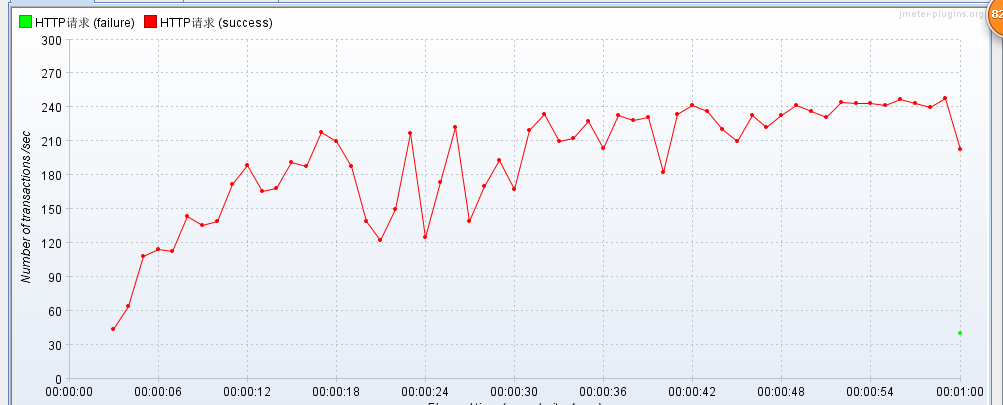
报告如下: 不使用memcached缓存,压测JSP!

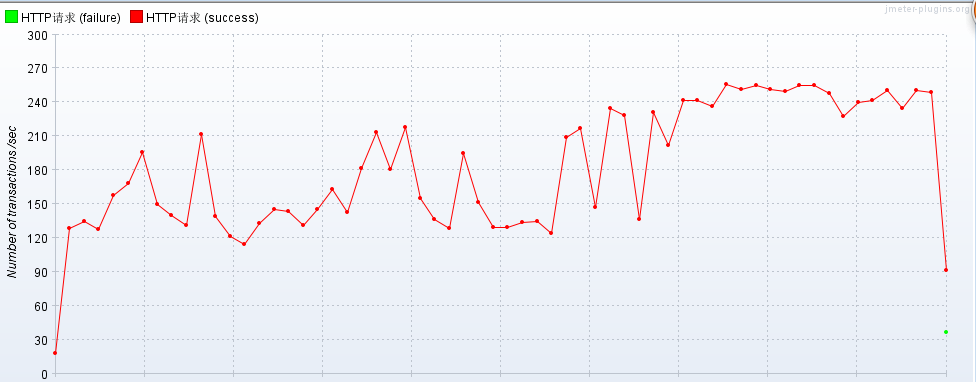
在service层添加大量判断的情况下使用缓存 90%line 比不使用缓存还快了近100毫秒!!!
开始压测JSNO接口,这里就要涉及到通过spring mvc返回json数据的知识点了!
这里使用简单的注解方式!
①将返回的值使用 @ResponseBody 注解标识

②引入相关jar依赖
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-core-asl</artifactId>
<version>1.9.13</version>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>1.9.13</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.0</version>
</dependency>
③在spring mvc配置中开启<mvc:annotation-driven /> 会自动注册
DefaultAnnotationHandlerMapping
AnnotationMethodHandlerAdapter
两个bean,这两个bean是spring MVC为@Controllers分发请求所必须的。并提供了数据绑定支持,@NumberFormatannotation支持,@DateTimeFormat支持,@Valid支持,读写XML的支持(JAXB),读写JSON的支持(Jackson)。

测试结果
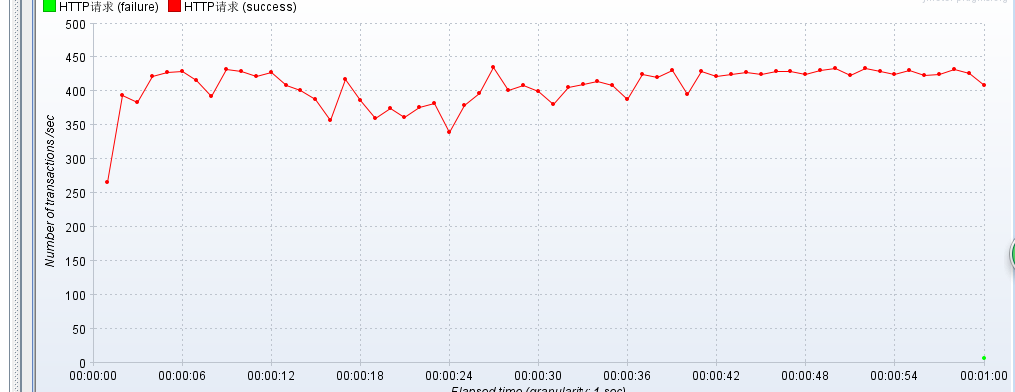
开始压测,线程属性如下:并发量40,手动测试1分钟访问效果!
报告如下: 使用memcached缓存,压测JSON!

报告如下: 不使用memcached缓存,压测JSON!

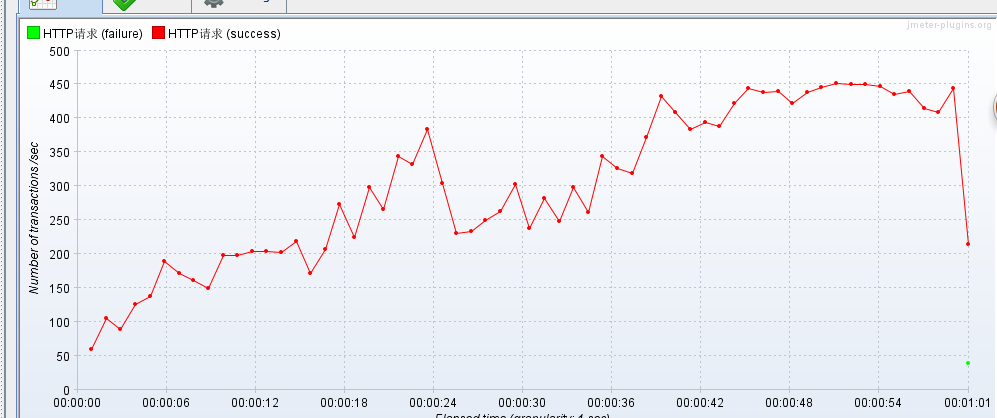
这里的说下权重这个概念,这里memcached和接下来的nginx都有这个属性weights,看过前面的师兄日报,谈到配置多个memcached服务器时如分配{4,6}表示40%缓存放第一台,60%缓存放第二台.
这里我持保留态度,我认为memcached权重和nginx的权重概念基本一致,即在访问memcached服务器时优先选择权重较高的服务器,从里面查询如查询不到结果,在访问数据后把内容放到该服务器.随着时间增加,权重较高memcached服务器因访问优先,其缓存里的内容肯定多于权重较低的memcached服务器,根据被访问的次数来看,两者缓存内容大小的比例会无限接近于两者所分配的权重比例!
这里开始用nginx.因为之前在Linux已经使用过了,这里一个是因为待会儿要压测服务器估计扛不住,二是也试下在win7里配置nginx使用多个服务器实现负载均衡!
..................实在搞不动了....休息了
明日计划: 瞄了眼验收标准,要理解的概念还很多.
问题:很多,坑踩了不少了今天
收获: 对memcache有了初步的了解..




评论