发表于: 2017-10-20 21:20:12
1 805
一.今日完成
1.学习JSP获取上下文路径的方法
在JSP中使用相对路径,多次转发或者跳转,相对路径会发生改变;在开发环境和应用部署环境中往往会发生URL请求地址不一致的问题,导致本地调试成功的项目发布到线上后发送请求出现404错误.解决方法:
(1)直接使用绝对路径
<%
String path = request.getContextPath(); //项目上下文路径
String basePath =
request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
//放入pageContext中
pageContext.setAttribute("basePath",basePath);
%>
(2)c标签设置动态参数
<form action="<c:url value = "/ loginCheck.html "/>" mehod = "post">
<c:url value = "/ loginCheck.html "/>的JSTL标签会在URL前自动加上应用部署根目录.假如应用部署在网站的bbt目录下,则<c:url>标签将输出/bbt/loginController.html.
2.Redis 和 Memcached 的区别
(1)网络IO模型
memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字pipe传递给worker线程,进行读写IO,网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如:memcached最常用的stats命令,实际memcached所有操作都要对这个全局变量加锁,进行技术等工作,带来了性能损耗。
redis使用单线程的IO复用模型,自己封装了一个简单的AeEvent事件处理框架,主要实现了epoll, kqueue和select,对于单存只有IO操作来说,单线程可以将速度优势发挥到最大,但是redis也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型施加会严重影响整体吞吐量,CPU计算过程中,整个IO调度都是被阻塞的。
(2)数据支持类型
memcached使用key-value形式存储和访问数据,在内存中维护一张巨大的HashTable,使得对数据查询的时间复杂度降低到O(1),保证了对数据的高性能访问。
redis与memcached相比,比仅支持简单的key-value数据类型,同时还提供list,set,zset,hash等数据结构的存储
(3)内存管理机制
Memcached使用预分配的内存池的方式,使用slab和大小不同的chunk来管理内存,Item根据大小选择合适的chunk存储,内存池的方式可以省去申请/释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除.
Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片,Redis跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上Redis更适合作为存储而不是cache。
(4)数据存储及持久化
memcached不支持内存数据的持久化操作,所有的数据都以in-memory的形式存储。
redis支持持久化操作。redis提供了两种不同的持久化方法来讲数据存储到硬盘里面,一种是快照(snapshotting),它可以将存在于某一时刻的所有数据都写入硬盘里面。另一种方法叫只追加文件(append-only file, AOF),它会在执行写命令时,将被执行的写命令复制到硬盘里面。
(5)数据一致性问题
Memcached提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 Redis没有提供cas 命令,并不能保证这点,不过Redis提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
(6)集群管理的不同
Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。当客户端向Memcached集群发送数据之前,首先会通过内置的分布式算法计算出该条数据的目标节点,然后数据会直接发送到该节点上存储。但客户端查询数据时,同样要计算出查询数据所在的节点,然后直接向该节点发送查询请求以获取数据。
Redis更偏向于在服务器端构建分布式存储。Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,它没有中心节点,具有线性可伸缩的功能。在数据的放置策略上,Redis Cluster将整个key的数值域分成4096个哈希槽,每个节点上可以存储一个或多个哈希槽,也就是说当前Redis Cluster支持的最大节点数就是4096。Redis Cluster使用的分布式算法也很简单:crc16( key ) % HASH_SLOTS_NUMBER。
3.新建一个基于Spring的 Web应用,复习Spring Web的开发流程
(1)做一个论坛的登录模块,在明确任务需求后,首先整理出一张时序图来清晰描述该模块的整体交互流程: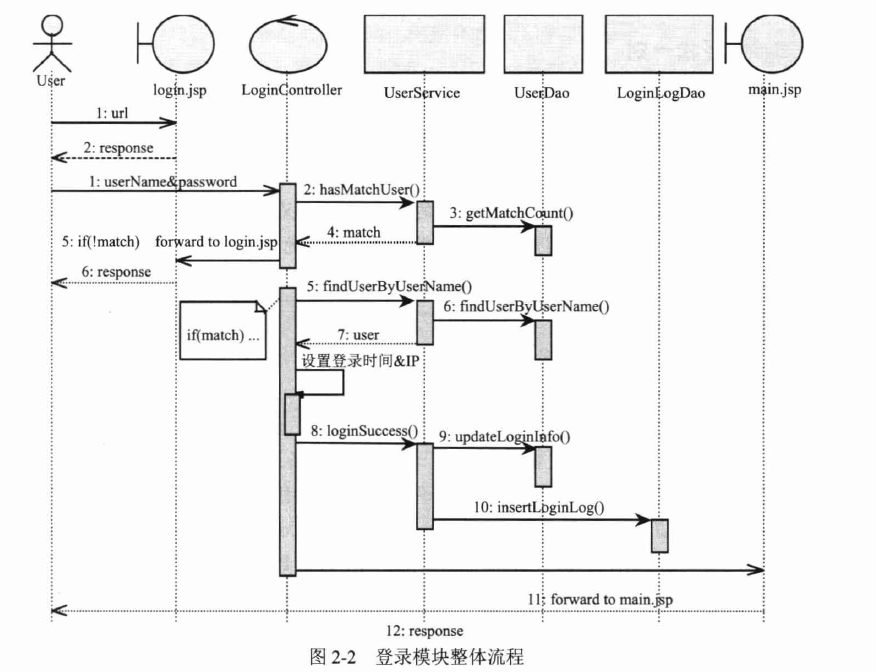
(2)类包规划
一般类包以分层的方式进行组织,分为dao,domain.service和web,但随着项目的增大,这种以分层思想规划的包结构显示出不足.一般,需要在业务模块包下进一步按分层模块划分子包,如user/dao,user/service,view/dao,view/service.
(3)在dao中写SQL语句
private final static String MATCH_COUNT_SQL = " SELECT count(*) FROM t_user WHERE user_name =? and password=? ";
private final static String UPDATE_LOGIN_INFO_SQL = " UPDATE t_user SET last_visit=?,last_ip=?,credits=? WHERE user_id =?";
在DAO中编写SQL语句时,通常把SQL语句写在类静态变量中,这样代码更具有可读性.如果编写的SQL语句较长,一般采用多行字符串的方式进行构造.在每行SQL语句的句前和句尾都加上一个空格,避免SQL语句组合后的错误.
(4)Spring MVC地址映射
<servlet>
<servlet-name>smart</servlet-name>
<servlet-class>
org.springframework.web.servlet.DispatcherServlet
</servlet-class>
<load-on-startup>2</load-on-startup>
</servlet>
<!--Spring MVC处理的URL-->
<servlet-mapping>
<servlet-name>smart</servlet-name>
<url-pattern>*.html</url-pattern>
</servlet-mapping>
此处声明了一个Servlet,Spring MVC也拥有一个Spring配置文件.该配置文件的文件名和此处定义的Servlet名关系:即采用<Servlet名>-servlet.xml的形式.
<servlet-mapping>元素对该Servlet的URL路径映射进行定义,实现所有以.html为后缀的URL都被该Servlet拦截,进而转由Spring MVC框架进行处理.框架本身和URL的模式没有任何关系.使用.html后缀,一方面用户不能通过URL直接知道后端采用了何种服务器技术;另一方面,.html时静态页面的后缀,可以骗过搜索引擎,增加页面被收录的概率,从而易于被检索.
二.明日计划
1.整理项目代码,实现任务要求的功能;
2.继续学习redis相关知识点,;
三.遇到问题
暂无.
四.收获
以上.
进度:计划周日提交任务6.




评论