发表于: 2017-10-13 21:03:46
2 690
今天完成的事情:
今天只干了一件事情,尝试使用Xmemcached实现memcached的分布式
memcached本身是不支持分布式的,只能通过算法实现
总结一句话:没我想象的复杂,没我想象的简单
配置,很简单:
工厂类:
<!--XMemcached配置-->
<bean id="memcachedClientBuilder" class="net.rubyeye.xmemcached.XMemcachedClientBuilder">
<constructor-arg>
<list>
<bean class="java.net.InetSocketAddress">
<constructor-arg value="39.108.78.2" />
<constructor-arg value="11211" />
</bean>
<bean class="java.net.InetSocketAddress">
<constructor-arg value="123.207.18.213" />
<constructor-arg value="11211" />
</bean>
</list>
</constructor-arg>
<constructor-arg>
<list>
<value>1</value>
<value>1</value>
</list>
</constructor-arg>
<property name="connectionPoolSize" value="50" />
<property name="commandFactory">
<bean class="net.rubyeye.xmemcached.command.BinaryCommandFactory" />
</property>
<property name="sessionLocator">
<bean class="net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator"/>
</property>
<property name="transcoder">
<bean class="net.rubyeye.xmemcached.transcoders.SerializingTranscoder" />
</property>
</bean>
客户端:
<!-- Use factory bean to build memcached client -->
<bean
id="memcachedClient"
factory-bean="memcachedClientBuilder"
factory-method="build"
destroy-method="shutdown">
</bean>
端口的设置很简单,一目了然,这个就不说了,重要的是算法的实现
<property name="sessionLocator">
<bean class="net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator"/>
</property>
就是这个东西,分布式的核心,上面使用的是一致性哈希算法,怎么实现的就不说了,看了教程都知道
余数哈希:ArrayMemcachedSessionLocator
以及剩下的算法为:
AbstractMemcachedSessionLocator
ElectionMemcachedSessionLocator
LibmemcachedMemcachedSessionLocator
PHPMemcacheSessionLocator
RandomMemcachedSessionLocaltor
RoundRobinMemcachedSessionLocator
按不同的场景可选择上面的算法
然后犯了一个错误:不明白一分布式算法会怎么样将数据分布到服务器
使用Jmeter测试数据库后我发现只有一个数据库的缓存中有内容,我以为应该每个服务器中都会有缓存
询问过韦杰师兄后才发现自己的错误,总结一下:
1.相同的key值只会存在于一个服务器的缓存中!无论压测多少次,都只在一个服务器中
2.使用不同的分布算法只会影响缓存存在哪个服务器
3.因为相同的key只存在一个服务器,所以在修改数据时清空缓存,那么就可以避免缓存与数据库不同步的发生
接下来是算法,并不严谨,从数据库中取出数据时随机的,所以缓存和数据库取出的数据时不一样的,仅做效果展示,demo时更正
studentDao.selectAllStudent();
SELECT * FROM student ORDER BY RAND() LIMIT 5;service
public List<Student> selectAllStudent() {
List<Student> students1 = (List<Student>) xMemcachedUtil.getCache("students1");
List<Student> students2 = (List<Student>) xMemcachedUtil.getCache("students2");
List<Student> students3 = (List<Student>) xMemcachedUtil.getCache("students3");
List<Student> students4 = (List<Student>) xMemcachedUtil.getCache("students4");
List<Student> students5 = (List<Student>) xMemcachedUtil.getCache("students5");
if (students1 != null && students2 != null && students3 != null && students4 != null && students5 != null) {
List<Student> students = students1;
students.addAll(students2);
students.addAll(students3);
students.addAll(students4);
students.addAll(students5);
logger.error("使用缓存");
return students;
}
logger.error("使用数据库");
List<Student> studentsFromDB1 = studentDao.selectAllStudent();
List<Student> studentsFromDB2 = studentDao.selectAllStudent();
List<Student> studentsFromDB3 = studentDao.selectAllStudent();
List<Student> studentsFromDB4 = studentDao.selectAllStudent();
List<Student> studentsFromDB5 = studentDao.selectAllStudent();
xMemcachedUtil.addCache("students1",3600,studentsFromDB1);
xMemcachedUtil.addCache("students2",3600,studentsFromDB2);
xMemcachedUtil.addCache("students3",3600,studentsFromDB3);
xMemcachedUtil.addCache("students4",3600,studentsFromDB4);
xMemcachedUtil.addCache("students5",3600,studentsFromDB5);
List<Student> studentsFromDB = studentsFromDB1;
studentsFromDB.addAll(studentsFromDB1);
studentsFromDB.addAll(studentsFromDB2);
studentsFromDB.addAll(studentsFromDB3);
studentsFromDB.addAll(studentsFromDB4);
studentsFromDB.addAll(studentsFromDB5);
return studentsFromDB;
}
清空缓存
使用nginx负载均衡同时访问两个服务器
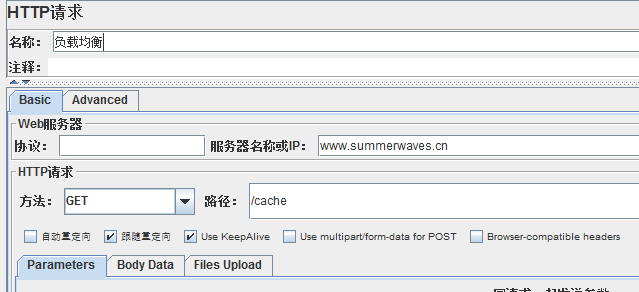
600个样本

查看两个服务器的缓存:
新服务器:
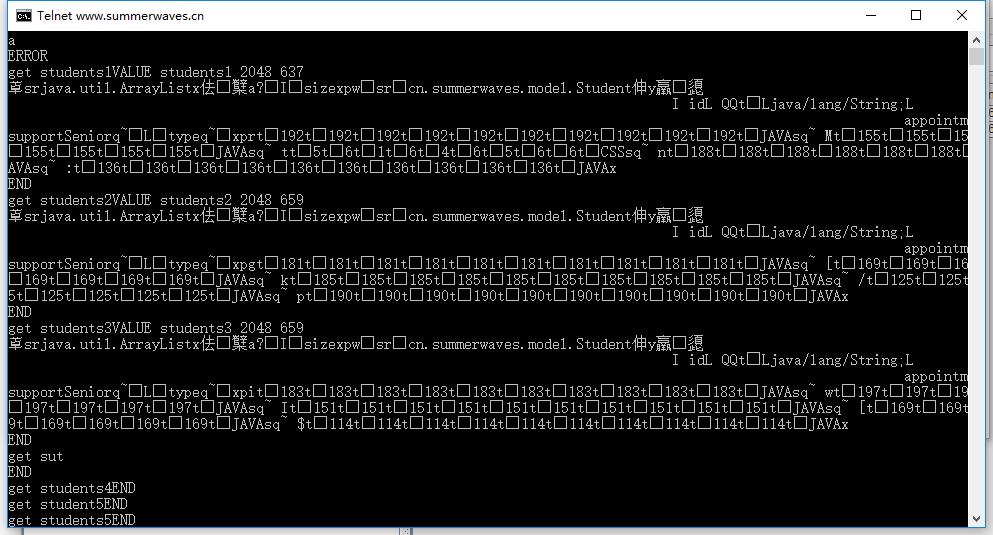
描述:students1、students2、students3中有缓存student4、students5中缓存为空
旧服务器:
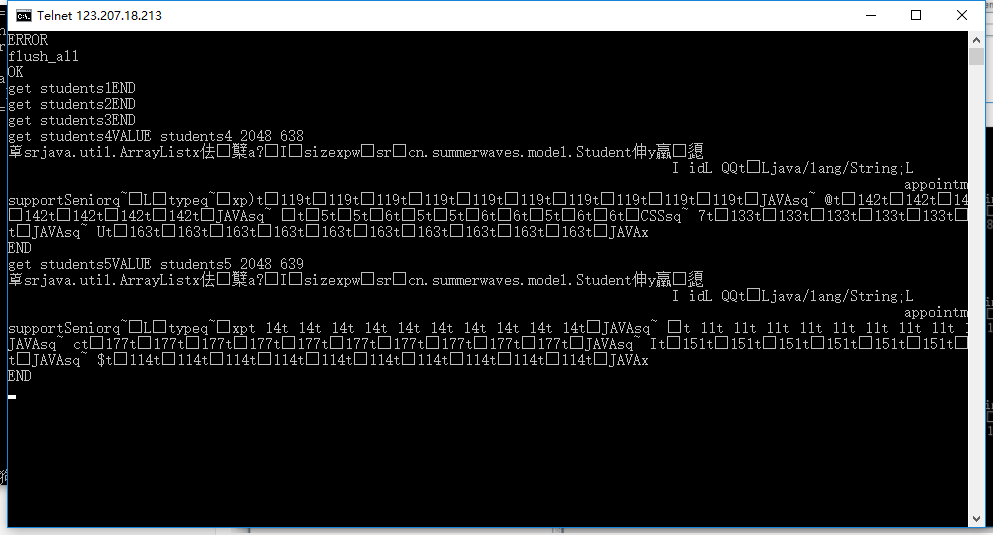
描述:students1、students2、students3缓存为空,student4、students5中有缓存
踩了个坑,不过明白了很多东西
明天计划的事情:
1.压测有无缓存的情况,以及防止缓存穿透、缓存雪崩
2.完成redis的学习
遇到的问题:
1.对分布式缓存理解不到位,白白浪费了很长时间,还好韦杰师兄对缓存熟悉
2.新服务器的tomcat无法关闭,按照异常搜了一下,尝试了两页的方法,都没用,花了很长时间也没有解决,最后花了半个小时重装系统,心累,但是想了想,若是在无法重装系统的情况下,那该怎么办呢?
收获:
.主要是对缓存、以及分布式缓存的配置、以及怎么起作用有了一个基本的理解,上面说过了,但还是copy过来吧
1.相同的key值只会存在于一个服务器的缓存中!无论压测多少次,都只在一个服务器中
2.使用不同的分布算法只会影响缓存存在哪个服务器
3.因为相同的key只存在一个服务器,所以在修改数据时清空缓存,那么就可以避免缓存与数据库不同步的发生
进度:
任务6开始时间:2017.10.08
预计demo时间:2017.10.16
延期风险:无
禅道
http://task.ptteng.com/zentao/project-task-350.html




评论