发表于: 2017-10-10 18:12:46
1 769
今天完成的事
1,赶路到线下。
2,开始从任务1,按日报进度温习一遍。
知识点一【mysql】
1,mysql数据库就是一个文件系统,需要通过标准SQL语句才能访问数据库就是一个文件系统,需要通过标准SQL语句(结构 化查询语句)才能访问。
2,sql分为4类语句
(1)DDL:数据定义语言
创建数据库名格式
create database 数据库名 character set 字符集 collate 校对规则;

查看数据库服务器中的所有的数据库show databases;
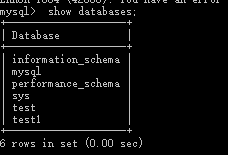
查看某个数据库的定义的信息:show create database 数据库名;

删除数据库 drop database 数据库名称;

修改数据库*alter database 数据库名 character set 字符集 collate 校对规则;

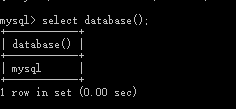
查看正在使用的数据库:select database();
创建表 create table 表名(字段名 类型(长度) 约束,字段名 类型(长度) 约束);

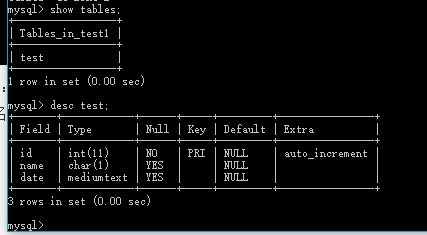
查看数据库中的所有表:show tables;
查看表结构:desc 表名;
alter table 表名 add column 列名 类型(长度) 约束; --修改表添加列.

alter table 表名 modify 列名 类型(长度) 约束; --修改表修改列的类型长度及约束.

alter table 表名 change 旧列名 新列名 类型(长度) 约束; --修改表修改列名.

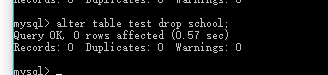
alter table 表名 drop 列名; --修改表删除列.
rename table 表名 to 新表名; --修改表名

alter table 表名 character set 字符集; --修改表的字符集

(2)DML:数据操纵语言
insert into 表 (列名1,列名2,列名3..) values (值1,值2,值3..); -- 向表中插入某些列
insert into 表 values (值1,值2,值3..); --向表中插入所有列


UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值

查找
DQL:数据查询语言.
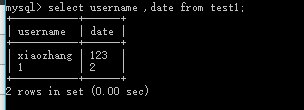
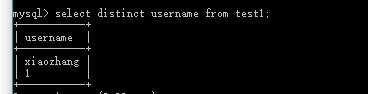
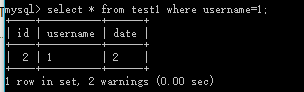
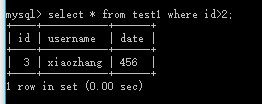
SELECT 列名称 FROM 表名称
(4)DCL:数据控制语言
if,grant这个就暂时不做了解了。
知识点【2】关于mysql的深度思考。
为什么DB的设计中要使用Long来替换掉Date类型。
翻阅了之前师兄的文档。http://www.jianshu.com/p/6e235da87853
DB中的两个类型:
①:bigint从 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) 的整型数据(所有数字)。
②:DATE 用于表示 年月日,取值范围:1000-01-01~9999-12-31。
之所以用long代替Date是因为
1. 因为DATE有固定的格式,不同的地区有不同的时间表示方法,而且外国有夏令时与冬令时之分,非常麻烦
2. 其实使用BigInt也能较为清晰的表示时间
3. 大多数时候我们并不关心某一个时间点,而是发生一个动作后,需要的时间,BigInt非常方便做减法而不用转化
自增ID有什么坏处?什么样的场景下不使用自增ID?
1,自增ID的坏处,不存在连续性。
2,数据自增了不会处理和提示。
3,在面向对象时,不能保证完整性。
有一条数据要调用这个对象时,显示的数据不完整,因为不知道ID,id被mysql系统处理了。自增ID就无法控制ID。
4,分库的时候ID就不唯一了。(解决方法采用UUid。)
什么情况下不适用自增ID。
1,自增ID的作用是唯一地表示表中某一条记录。如果有其他能标识该行数据的列,就不用了。
2,在做分布式数据库时。
收获
1,索引
重新理解了一下索引,发现之前只是运用,并没有理解,或者发现理解的都是错误的。
先理解一下平衡树。一种数据结构,和二叉树是不同的。
我们的表的数据结构如果没有主键,那就是“有序”的在磁盘上排列,而我们使用了二叉树,那数据就会承平衡树的方式排列在表中。
整个表就变成了一个索引,也就是聚集索引。主键的作用就是把表的数据格式转换成索引(平衡树)的格式放置。
非聚集索引就是我们所说的常规索引,非聚集索引也是一个平衡树结构。每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据。
受益匪浅~
2,数据库删除操作
sql删除语句有两种,第一种是delete from 第二种是truncate table 表明
网上查了一下两个的区别
truncate 与delete 比较:
1,truncate table 在功能上与不带 WHERE 子句的 delete语句相同:二者均删除表中的全部行。
2,truncate 比 delete速度快,且使用的系统和事务日志资源少。
3,truncate 操作后的表比Delete操作后的表要快得多。
4,当表被清空后表和表的索引将重新设置成初始大小,而delete则不能。
5,删除方式:delete 一条一条删除. 而truncate 直接将表删除,重新建表。
6,事务控制DML,而delete属于DML,如果在一个事务中,delete数据,这些数据可以找回。truncate删除的数据找不回来。
*我自己的理解就是delet自增ID会保留,再次添加会变成+1,但truncate不会,会按次序自增。
遇到的问题
换了IP之后,网打不开,数据库也炸了。。不能访问。
解决方法,重置了网络环境,没等全部重置完呢,好像就好了。
玄学。浪费了小半天时间
明天要做的事
1,按着今天的进度往下进行,争取赶到任务17左右。
2,把之前遗忘的或者不熟悉的知识点,再重温一遍。




评论