发表于: 2017-10-06 22:46:48
1 798
今天完成的事情:
1、log4j与System.out.println的比较
通常,我们写代码的过程中,免不了要输出各种调试信息。在没有使用任何工具之前,都会使用System.out.println来做到。这么做直观有效,但是有一系列的缺点:首先不知道这句话是在哪类,哪个线程里出来的,其次是不知道什么时候前后两句话输出间隔了多少时间,另外也无法关闭调试信息,一旦System.out.println多了之后,到处都是输出,增加定位自己需要信息的速度...这样光秃秃的说解决不了问题,还是随便找一个例子说明问题吧!
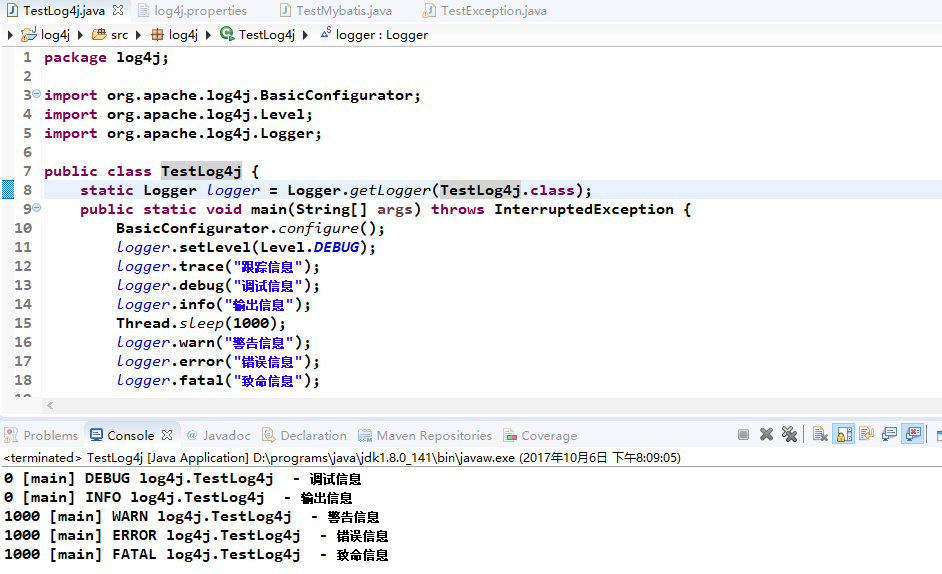
从上图可以看出使用log4j来进行日志输出,可以看到输出结果有了很好的改观:输出的结果知道是log4j.TestLog4j这个类里的日志,而且是在[main]线程里的日志,日志的级别可观察,一共有6个级别TRACE DEBUG INFO WARN ERROR FATAL,日志输出级别范围可控制,如代码所示,只输出高于DEBUG级别的,那么TRACE级别的日志自动不输出,每句话、日志消耗的毫秒数可以观察,这样就可以进行性能计算。
2、用了师兄的案列,插入100万条数据,传统插入方法:通过Connection获得Statement,再调用Statement对象的execute函数执行sql语句,插入一行,这样循环理论也是可以插入大数据,但是时间复杂度太高,效率低,所以根据Mysql数据库的操作时,一个sql插入语句中可以插入多行数据的原理,通过StringBuffer构造一个比较大的sql语句,每个语句可以插入1万行的数据,这样循环100次即可完成插入100w条数据。
这里的一个sql语句可以插入多条数据,我也简单测试了一下,可行;查看建立索引与不建立索引的时间差别
首先不建立索引
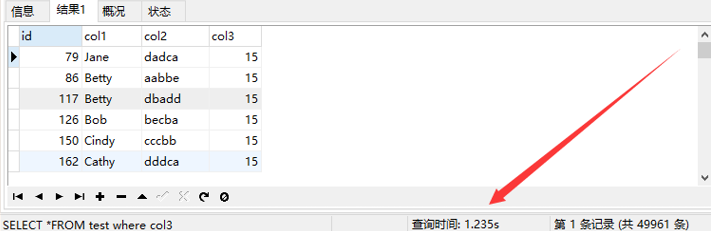
然后是建立索引的,建立索引的时候要选择普通索引,唯一索引不能选择,因为数据不能重复
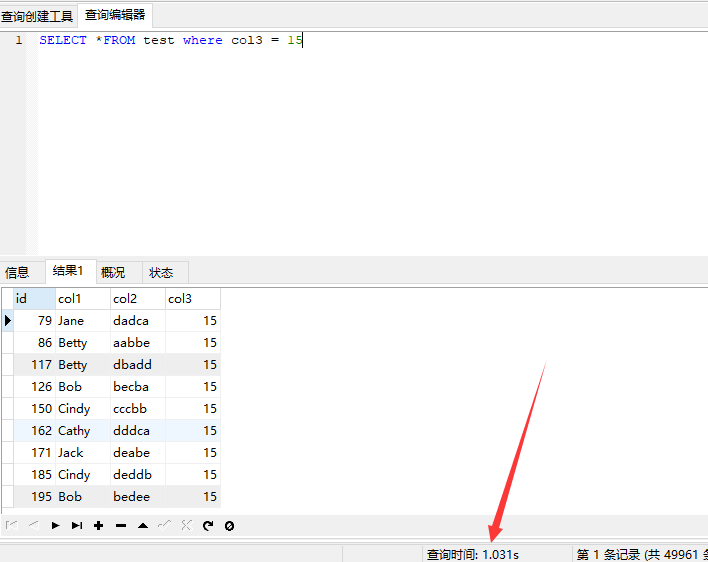
能够看出来有明显的时间差别,说明建立索引有助于数据库中数据的查询
明天计划的事情
将任务一学的只是做一下总结,然后提交任务一
遇到的问题:
暂无
收获
1、明白了用log4j的目的,它能够让我们一眼就能看出来这些输出是从哪个类哪个线程来的,遇到问题就能随时可以解决。
2、插入100万条数据,1000万条,1亿条数据在建立索引与不建立索引的时间差别,当然是建立索引有助于数据信息的查询。




评论