今天完成的事情
1.尝试在spring+mybatis框架下进行插入100万条数据的操作。
参考了同学的代码,使用了sql语句的foreach语句:
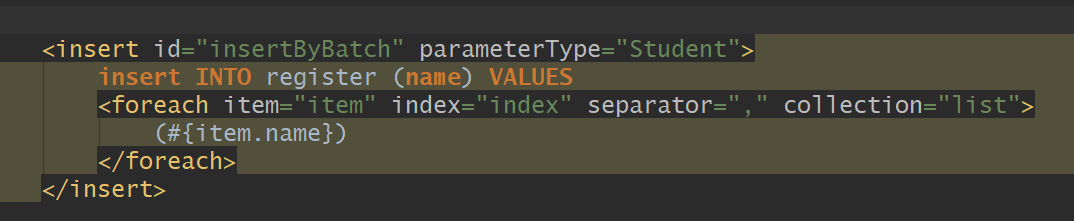
利用foreach来写一个超长的sql语句,一个sql语句带一万行记录,执行一次就向数据库中插入一万条,分100次执行,利用java的嵌套循环来实现。执行结果:

总共耗时32秒,比采用纯JDBC方式要慢,不清楚原因。
2.查阅了相关资料,了解了深度思考中的部分问题
1.maven是什么,和Ant有什么区别?
maven
maven是一个项目管理工具,是apache的一个项目。
maven的主要功能是:项目构建,项目依赖管理,软件项目持续集成,版本管理,项目的站点描述信息管理。
maven提供了一种思想,可以让团队更科学的管理,构建项目,用配置文件的方式对项目的描述,名称,版本号,项目依赖等信息进行描述,使之项目结构清晰,降低任何人接手的成本。
一个项目可能依赖于其他项目和第三方的组件,而maven提供了仓库的概念,让这些依赖项放进仓库,开发时直接去仓库中去取,不必每个人去开源项目的站点苦苦搜寻。这样,软件维护,沟通等的成本就都降下来了。
maven和ant都是项目构建管理工具,不同点在于maven有几项特点而ant没有:
1.maven约定了目录结构
2.maven有生命周期
3.maven内置依赖管理和Repository来实现依赖的管理和同意存储
4.maven配置比较简单,有很多的约定,规范,标准,代码量较少。ant配置比较麻烦,需要配置整个构建的过程,但也因此而较为灵活。
对于个人开发者,可能从开发到测试到最后打包都是一个人做的,并且用一个开发工具就解决这些了,因为大多数开发工具IDE是自带打包功能的。
但是在实际的公司工作中,开发人员与测试人员、部署人员是分开的,部署人员是不会向开发人员要源代码,他们也不会打包,那么怎么部署呢? 开发人员开发后,确认没问题,将源代码放到版本控制服务器中,并且写一个脚本,这个脚本运行就可以自动打包,然后部署人员运行这个文件打包后部署。 那么这个脚本里面需要关系到目录与加载的文件等,这时候如果每个项目用的文件都不同,目录名字千奇百怪,那么就不容易统一管理。
于是构建工具出现了,它规定你的目录必须要如何定制,这样方便统一管理。 Ant是比较好的构建工具,但是脚本目录要由自己写,命令中存在依赖关系,编译,打包。 编译目录还要自己指定,maven则指定好了目录,帮你打包,同时maven有一个中央仓库,可以帮你下载需要的工具包,只需要在pom.xml添加依赖即可,打包时自带进去,而不用平时跟着项目跑。
2.clean,install,package,deploy分别代表什么含义?
maven有三套相互独立的生命周期:
1.Clean 在进行真正的构建之前进行一些清理工作
2.Default 构建的核心部分,编译测试,打包,部署等
3.Site 生成项目报告,站点,发布站点。
这三个周期是相互独立的,可以仅调用clean来清理项目,或者是调用site来发布站点,而不会触发其他生命周期的运行。
每套生命周期都由一组阶段组成,平时输入的maven命令就对应于一个特定的阶段。在一套生命周期中,运行特定的阶段,它之前的所有阶段都将会被运行。
在Clean生命周期中,有三个阶段:
1.pre-clean 执行一些需要在clean之前额完成的工作。
2.clean 移除所有上次构建生成的文件。(这里的clea是Clean生命周期之中的clean阶段,两者具有不同的含义。)
3.post-clean 执行一些需要在clean 之后立刻完成的操作。
在开发中,绝大部分的工作都发生在Default这个生命周期,install,package,deploy这三个阶段就在这套周期中,依先后顺序,其意义分别是:
package:接受编译好的代码,打包成可发布的格式,比如JAR
install:将打包好的jar包安装至本地仓库,以让其他项目依赖。
deploy:将最终的包复制到远程的仓库,与其他开发人员共享项目。
3.怎么样能让Maven跳过JUnit?
在进行package操作时,在package 之前的阶段都会被执行,而其中就有test-compile(编译测试源代码),和test( 使用合适的单元测试框架运行测试)两个阶段。而这些代码最终是不会被打包或部署的。在遇到一些很大的项目时,单元测试需要耗费很多时间,对于最终的jar包却没有影响。有时候在一个项目中,主体代码本身没有问题,却有一系列失败的单元测试,开发人员则是仅仅想生成一个jar包而不想再去修复所有的单元测试,这是就需要进行在打包时跳过测试的操作。
1.可以在pom文件中添加插件:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</build>
2.输入命令:
mvn install -DskipTests
或者是:
mvn install -Dmaven.test.skip=ture
4.为什么要用Log4j来替代System.out.println?
log4j是帮助开发人员进行日志输出管理的API类库,其特点是可以用配置文件灵活的设置日志信息的优先级,日志信息的输出地,以及日志信息的输出格式,此外还可以显示调试信息。
使用System.out.println语句来输出某个变量值的方式,从而实现对代码的调试,会增加代码中的垃圾语句,而且要手动添加到代码中,log4j则是直接在配置文件中进行设置,比较灵活方便,而且可以生成日志文件用于记录。
5.为什么DB的设计中要使用Long来替换掉Date类型?
data类型有固定的格式,但是在不同的地区有不同的时间表示方法,会出现歧义。long类型可以采用运算的方式方便地进行转换。
6.自增ID有什么坏处?什么样的场景下不使用自增ID?
自增ID的意思应该是采用自增列来作为表的主键,这样的好处是,对于每一条添加的记录,都有唯一的一个ID来与之对应,至于自增主键不具有连续性的特点,并不能算是缺点,因为这样才能保证每一条数据的唯一性,譬如在共有5条数据的表中,删除了ID为3的数据,再添加一条数据,则这条数据的ID为6,而不会先再次为其添加ID为3。即使添加的数据是完全相同的,也能从ID区分出,两条数据是在不同的时间点添加的。
自增主键的缺点主要是:
1.由于采用了自增模式,且不会填充之前由于删除操作所空出来的ID,所以随着数据量的增加,ID会越来越大,当达到最大值后,会超出int的取值范围。不过这个问题一般情况下是不会发生的,因为定义为int的自增列,其最大值约为21亿,大多数情况下,数据量是达不到这个级别的,项目中需要操作大量的数据,还可以将自增列定义为bigint,其最大值是9222亿亿,一般情况下,数据量是达不到这么多的。所以这个问题并不显著,缺点应该是以下两点。
2.如果有合并表的操作,可能会出现主键重复的情况。
3.很难处理分布式存储的数据表。
对于2,3点还不是很理解,是从网上查的。
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
索引是存储表中的一个特定列的值的数据结构。
在数据库中常用于索引的数据结构主要有:
1.B-Tree ,是最常用的用于索引的数据结构
2.哈希表是另外一种可能用作索引的数据结构-这些索引通常被称为哈希索引。
使用索引的全部意义就是通过缩小一张表中需要查询的记录/行的数目来加快搜索的速度。就像一本书的索引包含页码一样,数据库的索引包含了指针,指向你在SQL中想要查询的值所在的行。
缺点:
1.索引会占用空间 ,表越大,索引占用的空间越大。
2.性能损失(主要是更新操作),当你在表中添加、删除或者更新行数据的时候, 在索引中也会有相同的操作。
对于在多大的数据量下建索引会体现出性能差异,在网上并没有查到定论,可能要就具体情况而论。
建立索引的基本原则是,如果表中某列在查询过程中使用得非常频繁,那就在该列上创建索引。
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
区别是:
1.在唯一索引中,索引列得所有值都是只能出现一次的,即必须唯一。
2.对于获取数据而言,唯一索引扫描取回一行数据即可。
当需要建立索引的列的值是要求不会重复的时候(如身份证号),可以建立唯一索引。
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要。若是建立了唯一索引,当在此列插入了相同的信息时,数据库会报错。
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
CreateAt是在一条记录被创建时赋值的,UpdateAt是在当前记录被修改是赋值的。都是在数据录入数据库时赋值,应该是在DAL中编写相应的语句来实现的。这两项不应该开放给外部调用的接口,因为这两者表示的是记录最终录入数据库的时间,不需要外部来进行修改。
11.修真类型应该是直接存储Varchar,还是应该存储int?
可以选择存储为varchar,这样能够很直观地表示。也可以存储为int,如开发中,可以与前端约定好,1表示java,2表示web等。从数据传输的角度来说,可能第二种方法效率高一点。
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
varchar可以保存可变长度的字符串,所占空间为字符串实际长度加1。对于不同的列,varchar可定义不同的长度来保存,如对于姓名,很少有超过4个字的,再考虑到一些特殊情况,可以定义长度为varchar(10)。
varchar在定义的时候需要指定长度,text不用指定长度,如果写了的话,不会报错,但指定的长度也不会其作用。varchar是受存储限制的,而text不受存储限制,在超过varchar最大长度的时候,就用text。longtext和text类似,只是容量更大。
14.为什么不可以用Select * from table?
select * 语句会取出表中的所有字段,这样会造成资源的浪费。
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:把行为和对象分离到不同的对象中,那个只有状态的对象就是贫血模型,而只有行为的对象则是logic等层,是面向过程编程。
充血模型则体现了面向对象的本质,既拥有行为也拥有状态。
采用Spring 框架时,通常就暗示已经使用了贫血模型。
之所以使用贫血模型,可能是因为贫血模型适合使用的场景是承载和传递数据,而且相比于充血模型,贫血模型的难度更低一些。
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
Ioc—Inversion of Control,即控制反转,是一种设计思想。
在传统的java程序设计中,人们是直接通过new来创建对象,而在IOC中则是有一个容器来控制对象的创建,传统程序中,由开发人员主动控制对象直接获取依赖对象, 反转就是由IOC容器查找及注入依赖对象。
IOC的好处是:可以直接隐藏具体的创建实例的细节,在一个复杂的项目中,如果要手动创建一个对象,需要了解一系列的类的构造方法,十分繁琐,采用IOC,可以简化代码,直接取用所需的对象。
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Impl这种方式的好处是什么?
对于一个人开发的项目,接口与实现的分离收益并不大。但是对于多人协同开发项目,先定义了接口,就可以各自去编写实现类,达到同时开发的效果,这样可以降低各种成本。采用这种方式,可以使代码规范化,便于维护管理,可以方便后期修改某项功能,也实现了向使用者隐藏具体实现方法而只开放接口的效果。
明天的计划
尝试完成任务一
遇到的问题
对之前的相关知识还有很多不理解的地方,需要了解的知识太多了
收获
大致了解了到现在为止,所做的的只是一个简单的DAL,实现了对数据库的简单操作。




评论