发表于: 2017-09-29 23:17:45
2 616
今日完成的事情:
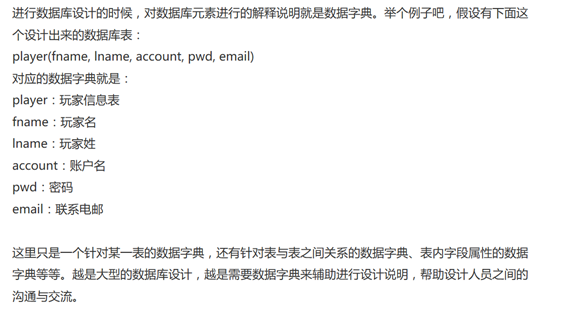
1,数据库需要知道等于什么 = 查数据字典(进行数据库设计的时候,对数据库元素进行的解释说明),这在分析阶段就会增大开销。
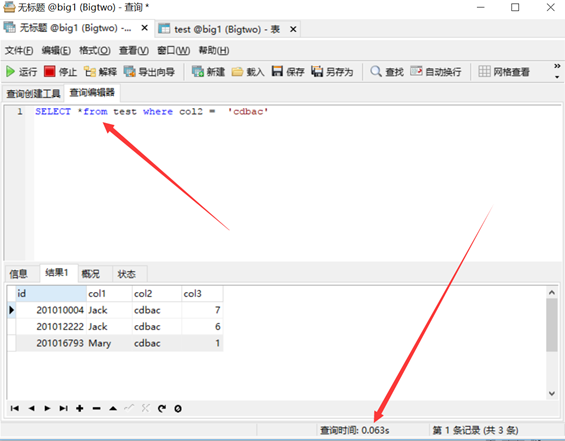
2,select *最大的问题是可能会多出一些不用的列,这就杜绝了索引覆盖的可能性,导致查询的成本几何级增高(索引覆盖:就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。)
Select <字段A,B....> from <数据表 T> where <条件字段C>
在SQL SERVER 2000中我们建立覆盖索引采用以下方式
Create index idx on T(C,A,B)
3,网络开销,不需要的字段会增加数据传输的时间,在本地客户端连的是本地mysql服务器,TCP协议传输数据会增加额外的时间;数据量越大这种这种劣势就会越明显;如果db和客户端不在同一台机器,比如链接到阿里云,那这种开销就更加明显
4,从另外一个相似的角度来看;就是查询进行的时候,多取了不必要的列,数据字段比较多,mysql并不是把所有结果全部得到后再进行一次性保存,而是每次分配一块大小的内存空间保存结果集,使用完后,接着再分配一个这样的块,如果还不不够,接着再分配一个块,依此类推,也就是说,有可能在一次查询中mysqI要进行多次内存分配的操作,频繁操作内存都是要耗费时间的。
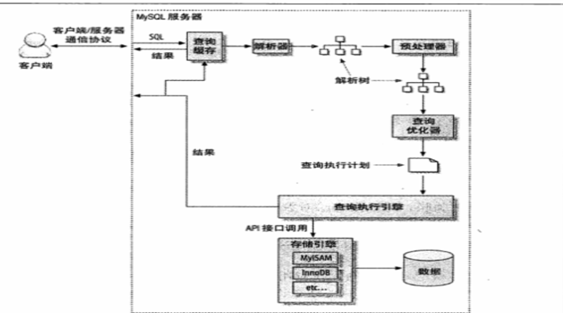
5,mysql拿到一条命令,会去解析命令、优化查询,然后去存储引擎执行查找,Select*数据库会解析更多的 对象,字段,权限,属性相关,在 SQL 语句复杂,会对数据库造成沉重的负担。
6,原则上讲作为有着良好编程习惯的程序员,也不应该获取自己不需要的东西,若是执行select*,以后表结构修改了,如增加了一列或删除了一列,对你的代码影响也很大,如果只是恰好只获取自己需要的那几列,表结构的修改对你的代码影响就会比较小。
7,获取数据&传输结果
明日计划的事情:
准备小课堂任务,完成后熟悉流程以及github相关内容
遇到的问题及解决方法:
新知识新概念,百度走
收获:
对于数据库的sql流程有了进一步的认识




评论