今天完成的事情:
1:看完老大的讲解dal视频
2:看大话数据类型
明天计划的事情:
1:把产品前端的功能都要看一遍,对着产品原型看
2:定时任务,来返还到期的利息金额使它自动转账给客户账户
3:每天去计算自动转账,到一个时间点给用户转账
4;画资金流向图,搞一个资金池,了解什么叫第三方资金托管
遇到的问题:
停电到下午五点,能干的事情不多
收获:
要执行的sql语句,要去数据库查,在查数据库的时候第一步先去缓存里去查,缓存查需要拼key
拼key的规则:根据名字+值,获取到一个key,比如list name和keyProperty,然后通过key去缓存里取值.
如果值没有,再去数据库执行语句,然后把结果拿出来重新拼成写到cache里去.这就是dal
group.xml指的是数据库连接池,指定数据库连接是哪一个
daoConfig.xml里面写清楚里面加载哪些配置文件,]才能提前解析
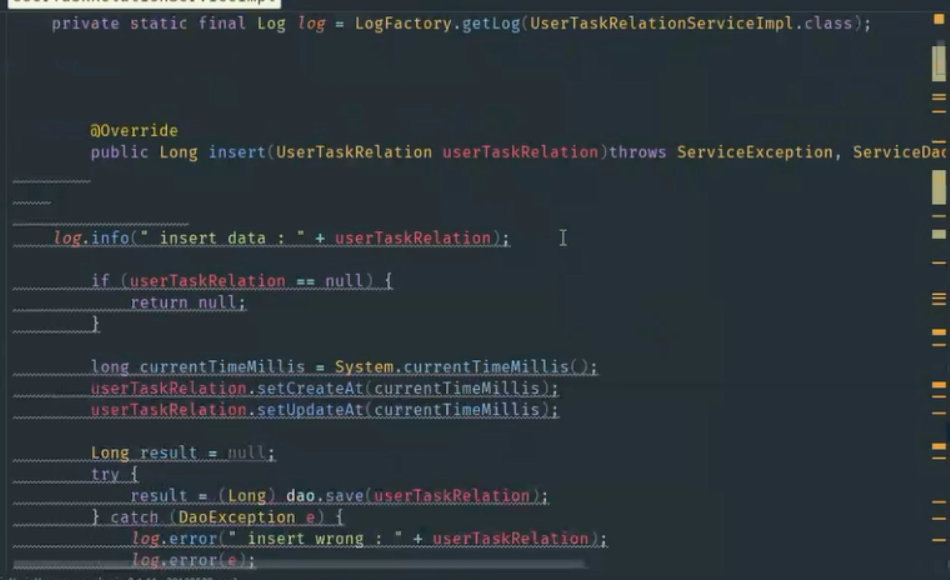
然后首先打日志,告知插入什么数据,如果空返回空是必须要做的.入参必打输出日志
然后每条记录都有创建时间和更新时间,记住这两个时间点.
再然后dao那里就是dal封装的,相当于一个util,save就是一个方法,把这个对象存进去.然后返回一个result,就是一个id.
这个dao里做了什么?如果没有缓存,直接插入数据即可,如果有缓存,需要怎么做?
因为有缓存,所以要遍历配置的缓存,看哪些条件用到这条数据的内容,然后增量到缓存.
save不仅仅是把代码插进去,还会进行维护,怎么维护暂时不知道
dao.mapping与dao.getIdList
如果一对一就用mapping,一对多就用list
根据业务逻辑选择
select count(*)与id的区别
select count(*) from daily where uid=?
select id from daily where uid=?
前者当然比后者好,因为这是一个人对应写了多少篇日报,后者会返回一个充满id值的数组,假如写了一百万篇日报,就会返回一个有一百万个id的数组,这样就很不方便,前者好处在于会返回一个数字告诉你有多少篇日报.count*就是在本地计算,把结果返回,是数据库提供的功能
数据元素是组成数据的,有一定意义的基本单位。
比如畜类,数据元素就是猪,狗,牛
数据项是数据不可分割的最小单位,比如人元素,有眼,耳,鼻等数据项。
不同数据元素之间不是独立的,而是存在特定的关系,我们把这种关系成为结构
数据结构则是相互之间存在一种或多种特定关系的数据元素的集合
逻辑结构和物理结构:
按照视点的不同,我们把数据结构分为逻辑结构和物理结构
逻辑结构:
是指数据对象中数元素之间的相互关系.
逻辑结构分为四种
1:集合结构
集合结构中的数据元素除了同属于一个集合外,它们之间没有其他关系.
各个数据元素是平等的.
它们的共同属性是同属于一个集合
2:线性结构
线性结构中的数据元素之间是一对一的关系
3:树型结构
树型结构中的数据元素存在一种一对多的层次关系
4:图形结构
图形结构的数据元素是多对多的关系
物理结构:
物理结构又叫存储结构,是指数据的逻辑结构在计算机中的存储形式
数据结构的存储结构形式有两种:顺序存储和链式存储
顺序存储结构:
是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的
说白了就是排队占位,比如说数组就是这样的存储结构,告诉计算机要建立一个有9个整型数据的数组时,计算机就在内存找片空地,按照整型所占位置的大小乘以9.开辟一段连续的空间.于是第一个数组数据就放在第一个,然后第二个,依次摆放
链式存储结构:
并不是所有的数据结构都这么简单又有序,实际上会有人插队,会有人退出,所以这个队伍可能会添加新成员,也有可能会去掉老成员,整个结构时刻处于变化之中.
显然,像上文中的顺序存储结构不适用于此项规则
链式存储结构就是把数据元素存放在任意的存储单元里,这组存储单元可以杀连续的,也可以是不连续的.
因此需要用一个指针存放数据元素的地址,这样通过地址就可以找到相关联数据元素的位置.
对比顺序存储结构,链式存储结构就灵活了很多,数据存在哪并不重要,只要有一个指针存放了相应的地址就能找到它了




评论