发表于: 2017-09-11 22:29:15
2 803
今天完成任务
【1】
鉴于上一次日报对JDBC的粗略了解,导致后来mybatis困难重重,所以今天起来第一件事重新又写了一遍JDBC
貌似JDBC对数据库的操作就是多态的一种啊。
import org.junit.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class hello {
@Test
public void F1(){
System.out.print ("hello,此程序用来测试JDBC");
}
@Test
public void F2() throws Exception{
//注册驱动
Class.forName("com.mysql.jdbc.Driver");
//获取链接
Connection c= DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/mysql","root","123");
//编写sql
String sql="select * from student3";
//创建语句执行者
PreparedStatement st= c.prepareStatement(sql);
//设置参数
//执行sql
ResultSet rs=st.executeQuery();
while(rs.next()){
System.out.print(rs.getString("id")+"::"+rs.getString("user_name"));
}
rs.close();
st.close();
c.close();
}}
这一次边理解边编写这个JDBC,感觉这次比上次直接誊写代码懂了更多。
【2】又开始尝试创建mybatis链接
百度了一下了mybatis框架
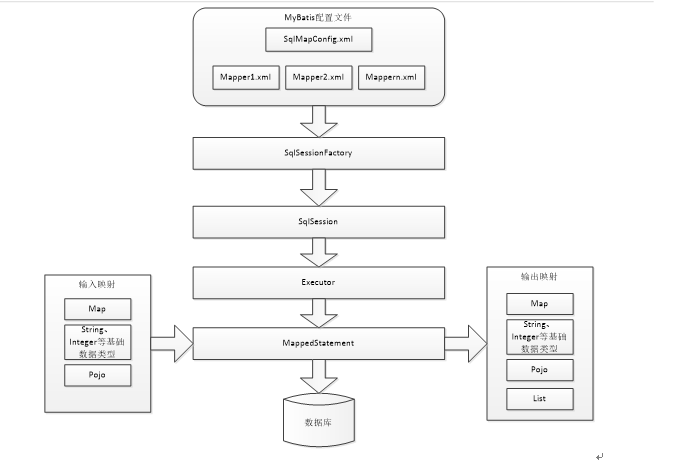
1、 mybatis配置
SqlMapConfig.xml,此文件作为mybatis的全局配置文件,配置了mybatis的运行环境等信息。
mapper.xml文件即sql映射文件,文件中配置了操作数据库的sql语句。此文件需要在SqlMapConfig.xml 中加载。
2、 通过mybatis环境等配置信息构造SqlSessionFactory即会话工厂
3、 由会话工厂创建sqlSession即会话,操作数据库需要通过sqlSession进行。
4、 mybatis底层自定义了Executor执行器接口操作数据库,Executor接口有两个实现,一个是基本执行器、一个是缓存执行器。
5、 Mapped Statement也是mybatis一个底层封装对象,它包装了mybatis配置信息及sql映射信息等。mapper.xml文件中一个sql对应一个Mapped Statement对象,sql的id即是Mapped statement的id。
6、 Mapped Statement对sql执行输入参数进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql前将输入的java对象映射至sql中,输入参数映射就是jdbc编程中对preparedStatement设置参数。
7、 Mapped Statement对sql执行输出结果进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql后将输出结果映射至java对象中,输出结果映射过程相当于jdbc编程中对结果的解析处理过程。
按着别人的博客学着开始配置文件。
SqlMapConfig.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 和spring整合后 environments配置将废除-->
<environments default="development">
<environment id="development">
<!-- 使用jdbc事务管理-->
<transactionManager type="JDBC" />
<!-- 数据库连接池-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mysql" />
<property name="username" value="root" />
<property name="password" value="123" />
</dataSource>
</environment>
</environments>
</configuration>
log4j.properties文件
# Global logging configuration
log4j.rootLogger=DEBUG, stdout
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
目前的进度就到这里,很慢,还是告诉自己放松心态,每一部走的扎实一点。
遇到的问题
【1】编写JDBC的时候背诵那些语句太痛苦了,就去试着理解加百度了一下。
每一步的作用大概是下面这样如下。
PreparedStatement的用处就是所有sql语句运行前,必然有个解析过程,就好象java代码的编译一样。如果同样的语句运行多次,当然希望它是一次编译多次运行的。这样可以减少编译的过程。 PrepareStatement就是干这事的。 它其实返回一个编译后的标识。用这个标识系统就可以直接找到编译过的sql来运行。不必要把每次的sql都编译一遍。
此外有些sql只是部分值不同,其他都一样。那么就把不同的部分变成 参数,sql编译后,每次使用不同的参数来实行。
executeQuery的作用是执行数据库查询语句 这个方法的参数是一个sql语句。
class.name则是加载一个类的程序。
executeQuery(String sql)
执行select语句,它返回的是查询后得到记录集(resultset)。
executeUpdate(String sql)
执行update,insert,delete语句,它返回的是语句执行后说影响到的记录条数(int)。对于 CREATE TABLE 或 DROP TABLE 等不操作行的DDL语句,executeUpdate 的返回值总为零。
execute(String sql)
执行任何sql语句,也就是前两者之一。返回值是第一个结果的表现形式。当第一个执行结果是查询语句时,返回true,可以通过getResultSet方法获取结果;当第一个执行结果是更新语句或DDL语句时,返回false,可以通过getUpdateCount方法获取更新的记录数量。
JDBC的大部分语句就这样从新理解了一下。。
【2】想知道log4j.properties文件和SqlMapConfig.xml文件这种配置文件是要自己写的么?还是说从官方文档里面都能找到,往师兄指条明路,因为真的背不下了,也理解不太好,只会改一些配置开始适应自己的本地数据库,这样就达到要求了么?师兄帮忙回答一下!高亮!
明天要做的事
【1】继续死磕mybatis,争取数据库配置成功。
【2】在看一点JAVA语法,多态那里重温一下,感觉最近要经常用到。




评论