发表于: 2017-09-09 23:23:51
3 863
【今日完成】
今天准备提交任务六了。下面是任务六的通关总结:
一、缓存的作用:
一个正常的网站,同时几百上千人访问是非常正常的,而通常一个网页的信息,都是动态的,会从数据库中调用,那么问题来了,数据库本身的并发能力并不强,几百个并发就能让数据库崩溃。这显然极大的限制了网站的功能。那么怎么样才能让几百人乃至几万人同时访问网页呢?
答案就是缓存。让缓存在客户端与数据库中做一个隔断,替数据库挡刀。让绝大多数客户端都是从缓存中得到数据而不是从数据库中得到数据。
二、缓存的主要工具:
①Memcached工具:
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
②Redis工具:
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
两者的相同点:
Memcached与Redis都属于内存内、键值数据存储方案。它们都从属于数据管理解决方案中的NoSQL家族,而且都基于同样的键值数据模型。双方都选择将全部数据保存在内存当中,这自然也就让它们成为非常理想的缓冲层实现方案。从性能表现的角度来看,两类数据存储机制也具备诸多共通性,包括拥有几乎相同的特征(与指标)表现、而且高度关注工作负载的数据吞吐量与延迟状况。
Memcached与Redis为什么如此受人拥戴?除了二者卓越的实际效果之外,双方各自极为简便的上手难度也是又一大加分项。无论是Memcached还是Redis,其使用便捷性在开发人员当中都可谓广为人知。只需要几分钟我们就能完成安装工作,并让它们开始与应用程序顺畅协作。
两者的不同点:
相对Memcached而言,Redis的面世时间更晚且具备更多功能,因此开发人员通常将其视为默认性首选方案。不过有两类特殊场景仍然是Memcached的一家天下。首先就是对小型静态数据进行缓存处理,最具代表性的例子就是HTML代码片段。Memcached的内部内存管理机制虽然不像Redis的那样复杂,但却更具实际效率——这是因为Memcached在处理元数据时所消耗的内存资源相对更少。作为Memcached所支持的惟一一种数据类型,字符串非常适合用于保存那些只需要进行读取操作的数据,因为字符串本身无需进行进一步处理。
Redis几乎在缓存管理工作中的每一个侧面都表现出显而易见的优越性。这套缓存方案采用所谓数据回收机制,能够将陈旧数据从内存中删除以提供新数据所必需的缓存空间。Memcached的数据回收机制使用的是LRU(即最低近期使用量)算法,而且往往会比较武断地直接删除掉与新数据体系相近的原有内容。相比之下,Redis允许用户更为精准地进行细化控制,利用六种不同回收策略确切提高缓存资源的实际利用率。Redis还采用更为复杂的内存管理与回收对象备选方案。
不过在练习中,两者的差别并不是很大。
原因有两个方面:
1:毕竟才开始接触,很多高级的东西都没用到,两者在基础功能方面都是差不多的。
2:没有什么极端情况来暴露性能
三、两类工具的具体应用:
两者都属于轻量级,所以配置比较方便:
1、Memcached:
首先是引Jar包,配置环境属性(端口,IP地址等等),最后创建一个工具类即可通过工具类来使用。
下面仅仅显示核心,工具类的代码:
/**
* Created by gongjianfei on 2017/09/03.
*/
public class MemcachedUtil {
//创建全局的唯一实例
protected static MemCachedClient mcc = new MemCachedClient();
protected static MemcachedUtil memCached = new MemcachedUtil();
//设置与缓存服务器的连接池
static {
//服务器列表和其权重,个人memcached地址和端口号
String[] servers = {"192.168.31.139:11211"};
Integer[] weights = {3};
//获取socke连接池的实例对象
SockIOPool pool = SockIOPool.getInstance();
// 设置服务器信息
pool.setServers( servers );
pool.setWeights( weights );
//设置初始连接数、最小和最大连接数以及最大处理时间
pool.setInitConn(5);
pool.setMinConn(5);
pool.setMaxConn(250);
pool.setMaxIdle(100*60*60*6);
//设置主线程的睡眠时间
pool.setMaintSleep(60);
//设置TCP的参数,连接超时等
pool.setNagle(false);
pool.setSocketTO(60);
pool.setSocketConnectTO(0);
//初始化连接池
pool.initialize();
//压缩设置,超过指定大小的都压缩
// cachedClient.setCompressEnable(true);
// cachedClient.setCompressThreshold(1024*1024);
}
/**
* 保护型构造方法,不允许实例化!
*
*/
protected MemcachedUtil()
{
}
/**
* 获取唯一实例.
* @return
*/
public static MemcachedUtil getInstance()
{
return memCached;
}
/**
* 添加一个指定的值到缓存中.
* @param key
* @param value
* @return
*/
public static boolean add(String key,Object value){
return mcc.add(key,value);
}
public static boolean add(String key, Object value, Integer expity){
return mcc.add(key, value, expity);
}
/**
* 新建?一个指定的值到缓存中.
* @param key
* @param value
* @return
*/
public static boolean put(String key,Object value){return mcc.set(key, value);}
public static boolean put(String key,Object value,Integer expity){return mcc.set(key, value, expity);}
/**
* 替换一个指定的值到缓存中.
* @param key
* @param value
* @return
*/
public static boolean replace(String key,Object value){
return mcc.replace(key, value);
}
public static boolean replace(String key,Object value,Integer expity){
return mcc.replace(key, value, expity);
}
/**
* 删除一个指定的值到缓存中.
* @param key
* @return
*/
public static boolean delete(String key){
return mcc.delete(key);
}
/**
* 根据指定的关键字获取对象.
* @param key
* @return
*/
public static Object get(String key){
return mcc.get(key);
}
Redis:
Redis就比较厉害了,我一共找到三种配置方法。
第一种是Spring-data-redis。这是属于Spring框架中对Redis的支持,封装了一些方法,利用RedisTemplate来操作。
第二种是在Spring中直接配置Jedis。更难,但比第一种更灵活。
第三种是最简单的,使用Redis的JAVA客户端——RedisClient。
我在任务中就使用的客户端RedisClient,比较简单。
不过这种方法的最大弊端就是连传入的数据类型都没有封装好,只能使用String或者Byte数组。
好在我们可以创建一个序列化工具类,把任何类型都可以序列化成String,再通过反序列化来取出想要的类型。
/**
* Created by gjf on 2017/09/04.
*/
public final class RedisUtil {
//Redis服务器IP
private static String ADDR = "localhost";
//Redis端口号
private static int PORT = 6379;
//可用连接实例的最大数目,默认值为8;
//如果赋值为-1,则表示不限制;如果pool已经分配了maxActive个jedis实例,则此时pool的状态为exhausted(耗尽)。
//没用上,尴尬,config没这个set方法
private static int MAX_ACTIVE = 1024;
//控制一个pool最多有多少个状态为idle(空闲的)的jedis实例,默认值也是8。
private static int MAX_IDLE = 200;
//等待可用连接的最大时间,单位毫秒,默认值为-1,表示永不超时。如果超过等待时间,则直接抛出JedisConnectionException;
private static int MAX_WAIT = 10000;
private static int TIMEOUT = 10000;
//在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的;
private static boolean TEST_ON_BORROW = true;
private static JedisPool jedisPool = null;
/**
* 初始化Redis连接池
*/
static {
try {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxIdle(MAX_IDLE);
config.setMaxWaitMillis(MAX_WAIT);
config.setTestOnBorrow(TEST_ON_BORROW);
jedisPool = new JedisPool(config,ADDR,PORT,TIMEOUT);
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 获取Jedis实例
* @return
*/
public synchronized static Jedis getJedis(){
try{
if(jedisPool != null){
Jedis resource =jedisPool.getResource();
return resource;
}else {
return null;
}
}catch (Exception e){
e.printStackTrace();
return null;
}
}
/**
* 释放Jedis资源
* @param jedis
*/
public static void close(final Jedis jedis){
if(jedis != null){
jedis.close();
}
}
}
序列化的工具类就不贴出来了。
四、缓存的成果:
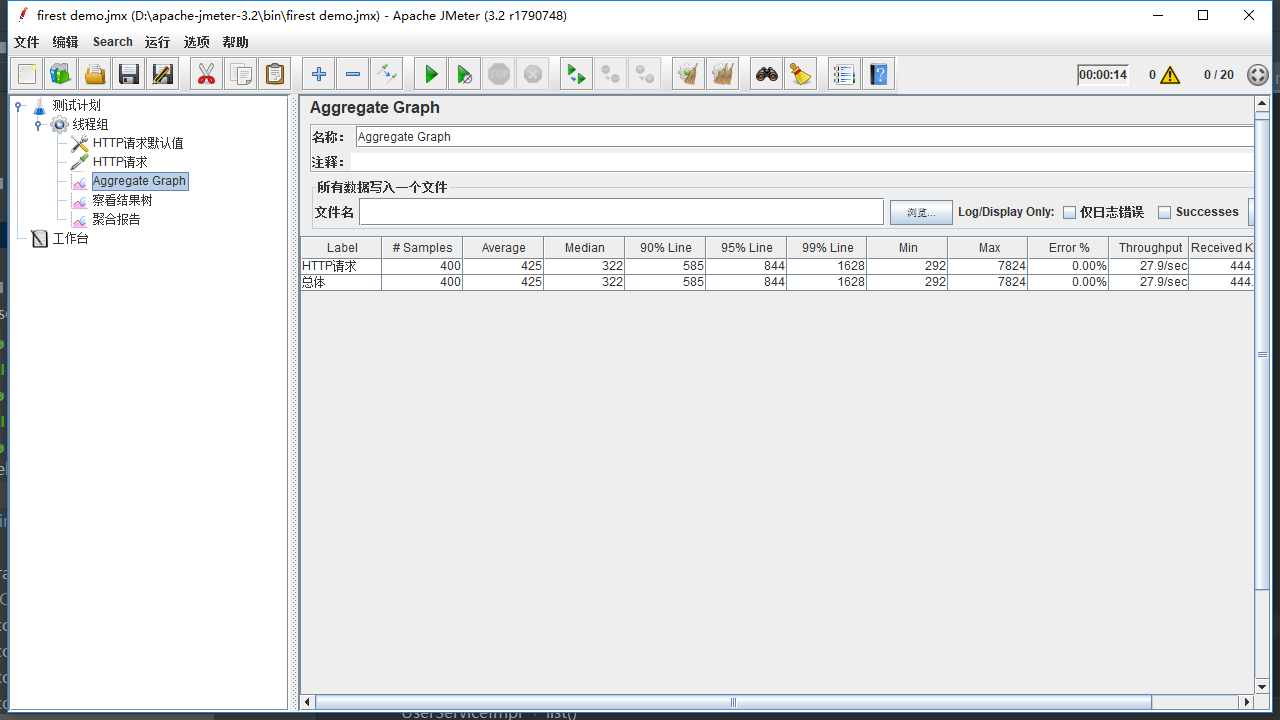
如图,这是没有使用缓存的情况。可以看到99%的line响应在1628ms
如图,这是使用了缓存,99%line在718ms
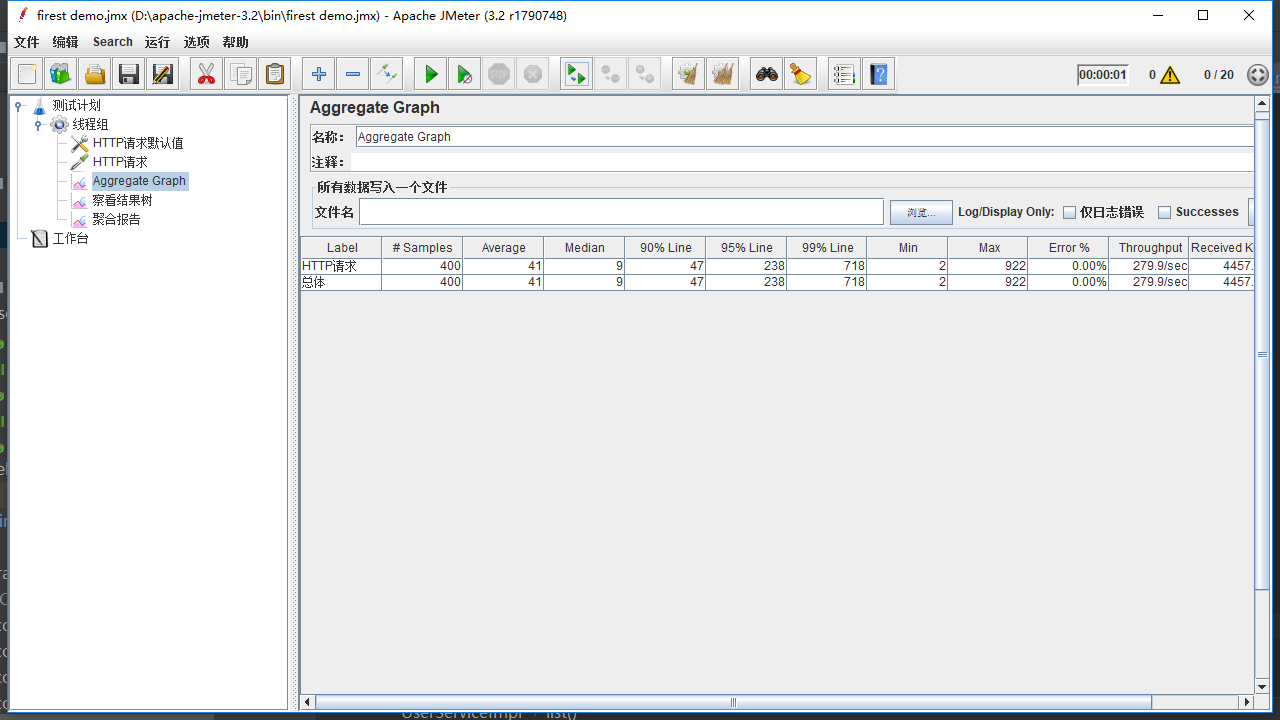
证明缓存真的蛮有用,一是可以增加最大并发数量,二是可以提高访问速度,毕竟在内存中取数据可比连接到数据库中取数据快了不止一点点。
五、任务总结:
缓存真的是挺有用的一个知识,以前从来没有考虑过网站可以承受多少访问。通过任务六,直观的认识了这一问题。这个任务完成进度比较慢,主要原因有2个,一是做任务一开始生病了,状态不好,脑袋特别昏;二是我在做任务六的同时,也在复习以前的Spring知识,与学习洗骨换髓营的知识,并没有一心求快。现在发现自己不知道的东西太多了,以前明明看过Spring的书,但现在看,发现可以理解很多以前不能理解的东西,第一次体会了什么叫温故而知新。这次任务做的不算理想,不过相信或许会在将来几周,回过头来看缓存,会有新的理解。学编程就是这样的,一开始是只会用,再往前走几步,再回头,就会发现从会用变成了理解,再往前走几步,再回头,就更清楚了。




评论