发表于: 2017-09-05 23:23:43
1 1061
今天完成的事情:先看了一下 关于网络请求时间的整体概念
第一部分前端的响应,一般包括解析和渲染,这部分的性能跟前端的代码,前端硬件有关系。 第二部分就是网络延迟,这部分的代码正常来讲是在8~16MS左右,是的,Http请求就是差不多这个性能,如果是WebSocket几乎可以做到零延迟,第三部分就是服务器端的响应,我们说的是网站慢,一般而言,也就是主要在这里,要做性能优化的地方,基本上也是看这里。这个第三部分也就是我们后端的处理。 出自老大的文章
第三部分也分为两个层面
一个是nginx时间 请求时间和响应时间 可以通过日志来查看
另一个就是容器花费的时间
这里比如我们用tomcat Tomcat响应的时间又可以分为: 1.Controller的处理时间 2.Service的调用时间 3.返回结果的处理时间
controller本身的处理事情,一般都会是在开始和结束各打一条毫秒数,这是所有的业务逻辑处理的总时间。
调用各Service的时间包含网络传输和Service的响应时间。返回结果的时间一般都是解析成Json的时间。
这部分就是我们后端来进行优化的地方
这里我们昨天从nginx日志里面 取出了nginx的请求时间 响应时间
今天取出数据库的时间 也就是上面说的原理一样 在service层调用 开始 结束 各打一条毫秒 然后相减
这里一般是用到了aop 以前从来没用过 又补了一下aop的基础知识
AOP核心概念
1、横切关注点 对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点
2、切面(aspect) 类是对物体特征的抽象,切面就是对横切关注点的抽象
3、连接点(joinpoint)
被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器
4、切入点(pointcut) 对连接点进行拦截的定义
5、通知(advice)
所谓通知指的就是指拦截到连接点之后要执行的代码,通知分为前置、后置、异常、最终、环绕通知五类
6、目标对象 代理的目标对象
7、织入(weave) 将切面应用到目标对象并导致代理对象创建的过程
8、引入(introduction) 在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段
Spring对aop有很好的支持 学习使用简单的Spring aop
首先添加依赖 写个工具类 统计调用方法花费的时间
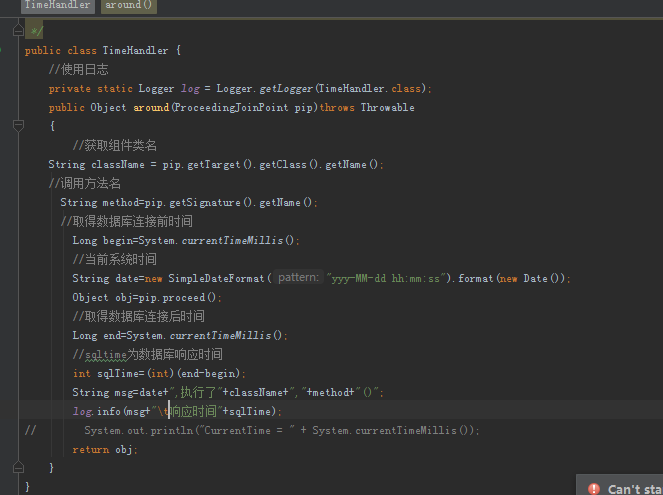
然后写它的配置文件 都是参考各位大佬的日报配置的
最后把它引入到总配置文件里

这里成功跑出了
明天计划的事情:开始任务四的学习
遇到的问题:aop学习的不是很好 只是参照了大佬们的写法 结果自己开始死活跑不出来 也没有报错
最后请教曾添师兄 曾添使用断点debug 一点点调试 检测像方法能不能调用
等等来验证那里没问题哪里可能有问题 这种思想方法必须得学习 虽然会用debug调试
但从未用过 用起来也没有思路 最终发现是没能调用service层 controller倒是可以
有研究了一下 发现时加载时候 加载写错了地方导致的
收获:没 改正昨天谈到的几点错误 以及没有说清楚的问题
首先 环境变量设置昨天那个$PATH 我以为删了没问题 今天一上Xshell 疯狂报错 所有命令都不识别了 无语
在命令行中输入:export PATH=/usr/bin:/usr/sbin:/bin:/sbin
这个昨天没写很清楚 linux下命令一般默认在这四个文件夹下 所以运行它暂时可以跑命令了
这个错误很明显环境变量有问题 vim /etc/profile 把昨天删的补回去 source一下 居然还没好 重连 好了
java获取当前系统时间System.currentTimeMillis
top命令
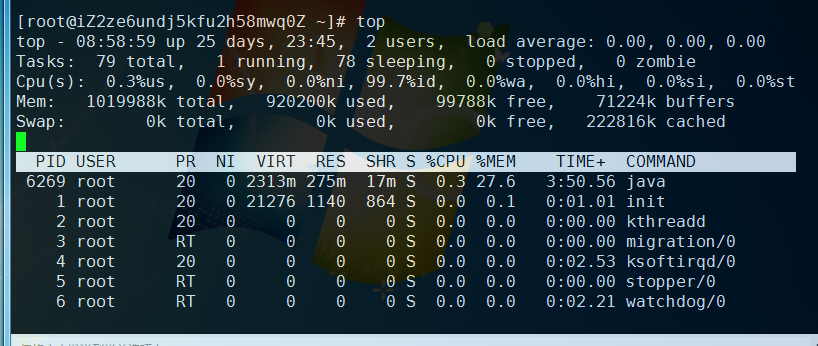
第一行:top 08:58:59 当前系统时间 25days23:45 系统已经运行25天23小时45分钟 (这期间没有重启过)
2users 当前有两个用户登录系统
load average:0.00 。。。— load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
第二行
Tasks — 任务(进程),系统现在共有79进程,其中处于运行中的有1个,78个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态
0.3% us — 用户空间占用CPU的百分比。
0.0% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
99.7% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
第四行:内存状态
1019988k total — 物理内存总量(1.1GB) 我认为是1.1g
920200k used — 使用中的内存总量(920M)
99788k free — 空闲内存总量(99M) 看上去很可怜 其实这里与windows不同
71224k buffers — 缓存的内存量 (72M)
第五行:swap交换分区
0k total — 交换区总量(GB)
0 used — 使用的交换区总量
0 free — 空闲交换区总量(0GB)
222816k cached — 缓冲的交换区总量(23M)
这里要说明的是不能用windows的内存概念理解这些数据,Linux的内存管理有其特殊性,复杂点需要一本书来说明,这里只是简单说点和我们传统概念(windows)的不同。
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存 190多M 好吧 他总共只有1.1G
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第七行以下:各进程(任务)的状态监控
PID — 进程id USER — 进程所有人 PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)




评论