发表于: 2017-09-05 16:00:49
1 843
完成的:
无
收获:
线性表
顺序表
顺序表中的数据元素存储是连续的,内存划分的区域也是连续的。
ArrayList即是顺序表数据结构的体现。
链表
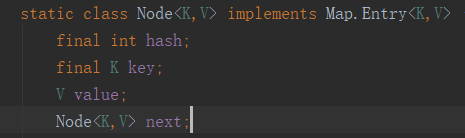
hashmap中的节点就是通过递归的方式构成一个单向链表
链表在物理存储上通常是非连续、非顺序的方式存储的,数据元素的逻辑顺序是通过链表中的引用来实现的。
包括单向链表(next)、循环链表(首尾连接)、双向链表(next/prev)、
栈和队列
栈和队列是两种受限制的线性表。
栈只允许从栈顶入栈出栈。队列只允许从队头出,队尾入。
transient
一个对象只要实现了Serilizable接口,这个对象就可以被序列化,java的这种序列化模式为开发者提供了很多便利,可以不必关系具体序列化的过程,只要这个类实现了Serilizable接口,这个的所有属性和方法都会自动序列化。但是有种情况是有些属性是不需要序列号的,所以就用到这个关键字。只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
Map接口
实现:hashmap、hashtable、concurrentHanshmap、treemap
不同点:
1.Hashtable线程安全。而hashmap是非线程安全的,
2.hashmap允许null
3.hashmap的迭代器是fail-fast的,迭代过程中其他线程修改hashmap的结构,hashmap会抛ConcurrentModificationException。hashtble不是,在迭代的时候会去底层集合做一个拷贝,所以你在修改上层集合的时候是不会受影响的,不会抛出ConcurrentModification异常。
HashMap初始化和put过程:
通过默认的构造方法在堆内存中开辟一块地址。并指定默认负载因子。
HashMap底层是一个数组+链表的结构。即一个线性数组结构,Map中有一个内部Entry接口,HashMap在自己的静态内部类Node中实现了它。有三个属性key/value/next。即键值和下一指向。
当调用map的put方法时,调用hashmap的getNode方法,它返回一个Node节点。

再往下看,如果key不为空,通过key算出散列值,并赋给h,h再与右移16位的h异或。这种操作是为了加大hashcode低位的随机性。散列值是一个int类型的16进制数,共32位。在底层需要通过该散列值算出所在数组下标,以确定存储位置。但Hashmap默认容量16,32位散列值太大,不能直接拿来计算,因此要先对数组长度取模,得到余数,再用于计算下标。取模还是通过一个indexFor函数实现的,它将散列值和数组长度做与。高位清空,保留低位,如果数组长度还是取16的话,那取模之后只保留4位了。但如果只取最后几位,哈希碰撞可能很严重,且如果散列本身做的不好,分布上成等差数列,会产生规律性。这是就通过下面的扰动函数解决问题。先右移16位,在与自身异或。混合原始哈希码的高位和低位,以此来加大低位的随机性。
而且这一步在jdk1.7是做了4次扰动,jdk1.8简化为1次,一次就够用了,毕竟边际递减效应。

这部分的返回值即扰动后的散列值。

外层putValue方法,当Node数组为空/长度为0时,调用resize函数,进行如下操作:
当放入第一个元素时,出发resize函数的newCap =DEFAULT_INITIAL_CAPACITY。即当数组为空时,以默认容量16构造一个数组。
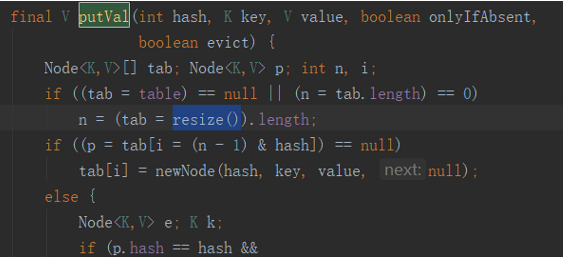
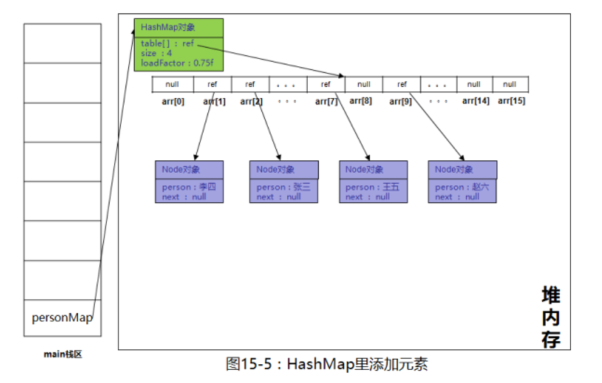
然后继续执行下面的语句,有个判断,即上面所说的,将散列值和数组长度做与,算出数组下标。这个算出来的一定在0到n-1之间。然后将其赋值,把Node放进该数组位置中。
最后放进去是这个样子,所谓的线性数组。
但也可能出现数组下标冲突的情况。紧接着上面putVal的代码。
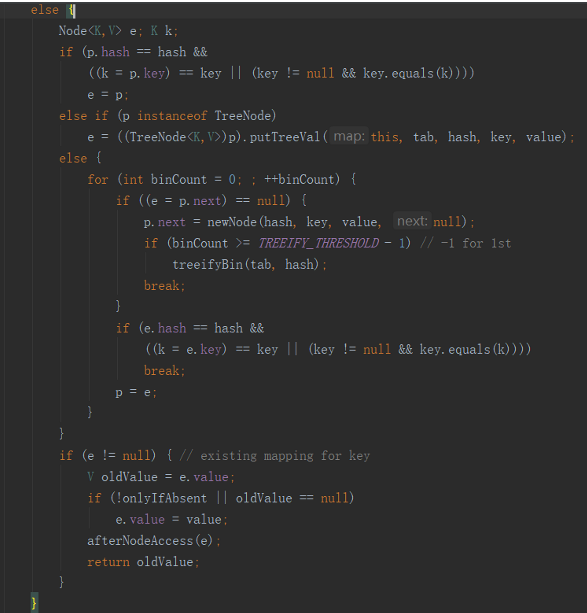
For循环里有一行p.next = newNode(hash, key, value, null);
也就是说new一个新的Node对象并把当前Node的next引用指向该对象,也就是说原来该位置上只有一个元素对象,现在转成了单向链表。
下面还有两行
if (binCount >= TREEIFY_THRESHOLD - 1) //当binCount>=TREEIFY_THRESHOLD-1
treeifyBin(tab, hash);
当链表长度到8时,将链表转化为红黑树来处理。果然追根溯源都到数据结构了。
在JDK1.7及以前的版本中,HashMap里是没有红黑树的实现的,在JDK1.8中加入了红黑树是为了防止哈希表碰撞攻击,当链表链长度为8时,及时转成红黑树,提高map的效率。
总结:
HashMap的最底层是数组来实现的,数组里的元素可能为null,也有可能是单个对象,还有可能是单向链表或是红黑树。
文中的resize在底层数组为null的时候会初始化一个数组,不为null的情况下会去扩容底层数组,并会重排底层数组里的元素。
知道hashmap的put实现,也就能针对性的做一些性能优化,比如用map做一个本地缓存,如果没指定出事容量,默认16,乘以负载因子后该map的临界容量为12,想要往这个map里放600个key,这个map就需要扩容六次,这个过程抛弃以前的线性数组,new一个新的线性数组,容量为其二倍,而且原有键值需要进行重hash,很浪费性能。反之,如果初始容量过大,散列程度过高,会减慢检索速度。所以要指定合适的初始容量。
计划:
准备面试题




评论