发表于: 2017-09-04 13:26:13
2 1076
今天做的事:
记一次对于java泛型的讨论
我:话说,想问一下你java泛型,我java基础不好
大佬:是直接让我说一下泛型,还是说你有什么例子不理解
我:不不,你听我说一下,有什么不对给我点一下
大佬:请开始你的表演
我:我理解的是<>,这个符号加上后,就是个泛型了,然后在这个<>中,我们可以加上任意类型的对象(存疑),之后我们就必须使用该类型,否则编译不通过,目前是这个理解
大佬:没毛病 ,不过后面不仅是该类型 比如Integer 也可以放int,然后子类也可以
我:哦,那我定义int的时候,放Integer是不是会报错?
大佬:不可以放基本类型,必须是引用类型,子类也可以


我:就是定义Integer,但是可以使用int子类
大佬:是的,这个是最基本的,还有吗?
我:然后还可以使用?这种做替代符,可以使用K,T这种做替代符,它们有什么区别
大佬:要使用KT这种,必须要在定义类的时候就添加上泛型,像这样
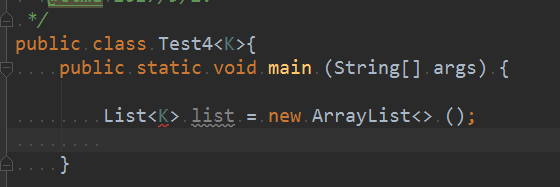
不然直接写一个K会被认为是无法识别的类型。
?可以直接使用代表任何类型
我:可以在定义类时不写泛型吗?
大佬:可以啊,那就用已经存在的类型,比如你有K类,那你就可以用K但是没有就不行,但是?有一个问题是如果

按照刚才截图那么写,那个list不能添加任何元素,因为?代表任何类型 1是一种具体的类型而不是任何类型,所以?不能用于在方法内部,?的作用在于传递参数的时候,或者返回值类型的时候
我:类似这种?

这个?的意思就是我懒得管你返回什么了,我也懒得写了,可以这么理解么?
大佬:是,这样写,就跟没写差不多,但是你肯定会问那要?干嘛
我:因为没有不行?
大佬:不是,没有也可以
我:那为什么?
大佬:
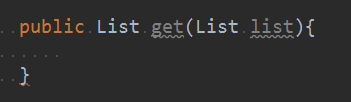
就在泛型中还有两个关键字,extends和super,这两个很好理解,一个是继承,一个是被继承,所以就有这种

这个代表什么我觉得你很容易就能明白
我:意思我加上这个就是为了继承
大佬:加上这个就代表返回的类型必须是Object的子类
我:那我为什么不直接写父类?一定要它的类型是子类,或者只写子类,这样也就不用写父类了啊,因为子类肯定继承父类
大佬:
比如你有一个鸭子类,鸭子接口,然后实现类有红鸭子 白鸭子等,然后你写了一个方法,这个方法既可以返回红鸭子 也可以返回白鸭子,那你返回值怎么写呢
我:哦,意思我不能返回父类,因为有些子类我不需要
大佬:而且最主要的是直接写父类就必须是父类了

这样就会报错
super也是同样de,只不过super代表的是下限
我:意思,我想返回父类的子类是不允许的,因为编译器认为我会少东西是吧
话说,问你一下super,当时学的时候理解的就一般,我只记得,使用super可以调用父类的东西,包括实例变量和方法
大佬:super就跟extends相反,x super A就代表,x必须是A的父类

这个就是用在泛型中,Integer是Number的子类,所以可以返回带Number的泛型,跟extends一样
我:那为什么还要加上这个super Integer
大佬:代表返回类型是Integer的父类啊,如果不加,就只能返回带Integer的泛型,其他的类型都会报错
我:Integer也有很多父类吗?
大佬:Object还实现了很多接口,这些主要是用于大的项目或者工程 比如jdk本身的开发,自己写的项目可能没有这么多继承体系,那么看起来就用不到,但是用不到并不代表我们就可以不知道嘛
我:哇,真的长见识,鼠目寸光,鼠目寸光,谢谢大佬,这么认真的回答我问题,还给我写了这么多例子
节选自2017年9月4日上午某次请教
接下来就是分析Spring和Redis整合
首先看一下
RedisTemplate<K,V>
经百度查询
- RedisTemplate是一种帮助类,可以简化Redis的访问数据的代码。在Redis数据仓库中,自动执行在给定对象与二进制数据之间的序列化和反序列化。默认情况下使用java的序列化方法(
JdkSerializationRedisSerializer)来序列化对象。对于字符串的加强操作,则使用StringRedisTemplate类。这是Redis中的核心类。
- 继承关系:
- java.lang.Object
- org.springframework.data.redis.core.RedisAccessor
- org.springframework.data.redis.core.RedisTemplate<K,V>
Type Parameters:
K- the Redis key type against which the template works (usually a String)V- the Redis value type against which the template works- All Implemented Interfaces:
- Aware, BeanClassLoaderAware, InitializingBean, RedisOperations<K,V>
- Direct Known Subclasses:
- StringRedisTemplate
这是官方文档(我看的是别人解读的):https://docs.spring.io/spring-data/redis/docs/current/api/org/springframework/data/redis/core/RedisTemplate.html#discard--
然后我们定义了这个帮助类后,开始定义我们的相关方法
/**
* 新增
*<br>------------------------------<br>
* @param user
* @return
*/
public boolean add(final User user) {
boolean result = redisTemplate.execute(new RedisCallback<Boolean>() {
public Boolean doInRedis(RedisConnection connection) throws DataAccessException {
RedisSerializer<String> serializer = getRedisSerializer();
byte[] key = serializer.serialize(user.getId());
byte[] name = serializer.serialize(user.getName());
return connection.setNX(key, name);
}
});
return result;
}
这个是参照例子写出来的,但是我们要弄清楚,其中的每一块
首先redisTemplate是帮助类的对象。
然后我们看到这里执行了一个execute方法,有点长,因为方法中的参数是一个new出来的带方法的类。
我们这个时候需要看一下源码
首先是execute方法
相关源码
public <T> T execute(RedisCallback<T> action) {
return this.execute(action, this.isExposeConnection());
}
public <T> T execute(RedisCallback<T> action, boolean exposeConnection) {
return this.execute(action, exposeConnection, false);
}
public <T> T execute(RedisCallback<T> action, boolean exposeConnection, boolean pipeline) {
Assert.isTrue(this.initialized, "template not initialized; call afterPropertiesSet() before using it");
Assert.notNull(action, "Callback object must not be null");
RedisConnectionFactory factory = this.getConnectionFactory();
RedisConnection conn = null;
Object var11;
try {
if(this.enableTransactionSupport) {
conn = RedisConnectionUtils.bindConnection(factory, this.enableTransactionSupport);
} else {
conn = RedisConnectionUtils.getConnection(factory);
}
boolean existingConnection = TransactionSynchronizationManager.hasResource(factory);
RedisConnection connToUse = this.preProcessConnection(conn, existingConnection);
boolean pipelineStatus = connToUse.isPipelined();
if(pipeline && !pipelineStatus) {
connToUse.openPipeline();
}
RedisConnection connToExpose = exposeConnection?connToUse:this.createRedisConnectionProxy(connToUse);
T result = action.doInRedis(connToExpose);
if(pipeline && !pipelineStatus) {
connToUse.closePipeline();
}
var11 = this.postProcessResult(result, connToUse, existingConnection);
} finally {
if(!this.enableTransactionSupport) {
RedisConnectionUtils.releaseConnection(conn, factory);
}
}
return var11;
}
可以看到其实这三个方法是同样作用的,就是最后起作用的就是第三个方法
由于源码很复杂,所以我们没必要细扣,只需要知道这个方法返回了一个对象var11
而这个值是通过
var11 = this.postProcessResult(result, connToUse, existingConnection);
返回的,好,到此为止,不去细究了
我们只需要知道,execute方法是执行方法,它返回了一个我们需要的对象。
回到我们的add方法中,方法中参数new出来的是
new RedisCallback<Boolean>()而且里面跟了一个方法
public Boolean doInRedis(RedisConnection connection) throws DataAccessException
通过查看源码,我们发现是有这么一个方法
public T doInRedis(RedisConnection connection) throws DataAccessException {
if(connection.exists(this.metadata.getCacheLockKey()).booleanValue()) {
return null;
} else {
Object var2;
try {
connection.set(this.metadata.getCacheLockKey(), this.metadata.getCacheLockKey());
var2 = this.doInLock(connection);
} finally {
connection.del(new byte[][]{this.metadata.getCacheLockKey()});
}
return var2;
}
}
但是显然,我们是将这个方法重写了
public Boolean doInRedis(RedisConnection connection) throws DataAccessException {
RedisSerializer<String> serializer = getRedisSerializer();
byte[] key = serializer.serialize(user.getId());
byte[] name = serializer.serialize(user.getName());
return connection.setNX(key, name);
}
这里进行了序列化的操作,以及Redis存值的操作。
最后,这个方法,分析完毕,通过类似的手段,我们逐一分析其他方法。
看了一下其他的方法,都大概逐一走了一下源码,发现Spring封装的真的是,一层套一层,看的不想看,所以放弃了,大概知道每个方法大概的实现就算了。
最最后,这篇解析源码的帖子不错,虽然看不懂但还是收获:http://yychao.iteye.com/blog/1751674
这里是讲解回调机制(Callback)的帖子(很不错):
http://blog.csdn.net/xiaanming/article/details/8703708/
在测试这个回调的时候,有一个有趣的现象,就是Junit不能测试多线程
这是相应的解答
通过Junit源码,在TestRunner中可以看出,如果是单线程,当测试主线程执行结束后,不管子线程是否结束,都会回调TestResult的wasSuccessful方法,然后当Junit的主线程结束后,就会判断结果是成功还是失败,最后调用相应的System.exit()方法。大家都知道这个方法是用来结束当前正在运行中的java虚拟机,jvm都自身难保了,所以子线程也就对不住你咧...
而使用main方法就可以成功使用多线程
main方法启动后本身线程会作为守护线程存在。当程序执行完成后,守护线程退出,守护线程永远是在程序执行完成之后再退出的。
所以不会存在Junit那种子线程还没运行完,整个程序就结束了的情况
另外,还学会了一招,使程序暂停然后继续运行。
//程序暂停5秒运行
try {
Thread.sleep(5000);
}catch (Exception e){
e.printStackTrace();
}
最后,目前在实现Spring+Redis整合的@Cacheable等注解实现Redis缓存。
两篇例子
链接如下:
http://blog.csdn.net/defonds/article/details/48137969
http://blog.csdn.net/defonds/article/details/48716161
明天计划:调试成功上面的例子,并且仔细学习一下
问题:都已解决
收获:java泛型;Callback机制;Spring整合Redis分析。




评论