发表于: 2017-08-30 23:13:28
1 1146
【今日完成】
今天看了一下Memcached的原理,弄明白了原来它是把数据存在内存中,而不是像数据库那样存储于硬盘中,所以速度会非常快,本质就是一张巨大的hash表,并且数据会自动过期。
下面是写的比较好的工作原理。
Memcached工作原理
与许多 cache 工具类似,Memcached 的原理并不复杂。它采用了C/S的模式,在 server 端启动服务进程,在启动时可以指定监听的 ip,自己的端口号,所使用的内存大小等几个关键参数。一旦启动,服务就一直处于可用状态。Memcached 的目前版本是通过C实现,采用了单进程,单线程,异步I/O,基于事件 (event_based) 的服务方式.使用 libevent 作为事件通知实现。多个 Server 可以协同工作,但这些 Server 之间是没有任何通讯联系的,每个 Server 只是对自己的数据进行管理。Client 端通过指定 Server 端的 ip 地址(通过域名应该也可以)。需要缓存的对象或数据是以 key->value 对的形式保存在Server端。key 的值通过 hash 进行转换,根据 hash 值把 value 传递到对应的具体的某个 Server 上。当需要获取对象数据时,也根据 key 进行。首先对 key 进行 hash,通过获得的值可以确定它被保存在了哪台 Server 上,然后再向该 Server 发出请求。Client 端只需要知道保存 hash(key) 的值在哪台服务器上就可以了。
其实说到底,memcache 的工作就是在专门的机器的内存里维护一张巨大的 hash 表,来存储经常被读写的一些数组与文件,从而极大的提高网站的运行效率。
关于JAVA客户端,现在来说一般有三种:
(1)较早推出的memcached Java客户端API,应用广泛,运行比较稳定。
(2)A simple, asynchronous, single-threaded memcached client written in java. 支持异步,单线程的memcached客户端,用到了java1.5版本的concurrent和nio,存取速度会高于前者,但是稳定性不好,测试中常 报timeOut等相关异常。
(3)XMemcached同样是基于Java nio的客户端,java nio相比于传统阻塞io模型来说,有效率高(特别在高并发下)和资源耗费相对较少的优点。传统阻塞IO为了提高效率,需要创建一定数量的连接形成连接 池,而nio仅需要一个连接即可(当然,nio也是可以做池化处理),相对来说减少了线程创建和切换的开销,这一点在高并发下特别明显。因此 XMemcached与Spymemcached在性能都非常优秀。
我还是用第一个,memcached client for java,比较简单。
首先是下载Memcached的Java客户端,下面这篇博文蛮不错的,可以参考一下
http://blog.csdn.net/dhdhdh0920/article/details/42242521
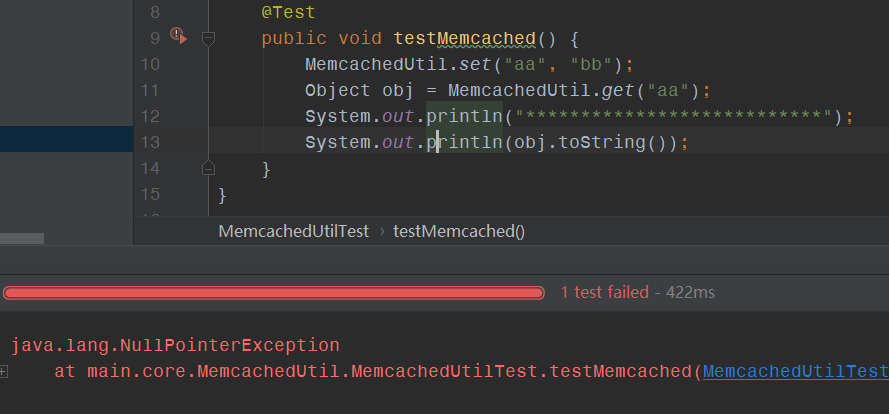
报了一个空指针异常,原来是obj对象为空,obj是get("aa")获取的对象,那么说明get方法返回了空值。
说明设置有问题。。。。这个我得研究一下,实在研究不出来结果,只有每天找博韬师兄要一份他的配置了,再对比一下我到底错在哪里。
【明日计划】
跑通Memcached测试,然后在自己的程序中加入memcached。
【遇到问题】
配置memcached JAVA端失败了,应该是哪里没弄对,还需要再检查一下。
【今日收获】
弄明白了memcached的工作原理及牛逼的地方。
【任务进度】
暂无延期风险吧。这周应该能完成。
http://task.ptteng.com/zentao/project-burn-268.html




评论