发表于: 2017-08-29 21:21:12
2 1099
一、 今天完成的事情。
1. 继续完成关于mysql的深度思考
Q7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
1) DB的索引是对数据库中列值进行排序的一种结构,使用优化的排序算法,能提高查询速度
2) 对于数据量所引起的性能差异,我做了如下测试:
首先,先建立两个数据量一样的表,一个为applicant,另一个为test
applicant有存在于字段name上的idx_name索引,而test仅有数据

关于如何快速增加表数据的方式,我采用了插入表语句:

接下来开始进行测试:
首先测试当数据量达1k+时:
有索引的表:

无索引的表:

数据量达1w+时:
有索引的表:

无索引的表:

数据量达10w+时:
有索引的表:

无索引的表:

综上,添加索引表在数据量达到10w+时查询速度明显优于无索引的表
结论:在数据量达10w+时可带来性能上的提升
3) 建立索引的字段应当满足:
需要频繁作为查询条件,唯一性强,不需要频繁更新等
Q8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
1)唯一索引要求其索引值必须唯一,不能重复。
2)如果确定某一列值不重复,在为其创建索引时就需要唯一索引
Q9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要。创建唯一索引后,插入新数据时,系统会自动检查是否存在该字段值,若已存在,mysql会拒绝本次插入。
因此创建唯一索引的目的往往是为了确保数据的唯一性。
Q10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
1) 在插入数据时需要给两个时间都赋值,在更新数据时只需要给update_at赋值
2) 个人认为不需要。这是给数据库管理员查看,提供接口降低了安全性。至于两个字段的赋值问题,可以给两个字段添加时间戳(触发器),由系统自行添加
Q11.修真类型应该是直接存储Varchar,还是应该存储int?
修真类型样例:JAVA工程师
明显属于字符串,故选择varchar类型
注:varchar存储字符串类型,int存储整数类型
Q12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
1) Mysql5.0以上版本,Varchar最大存储字节时65535,而确定varchar类型时varchar(length)中的length代表不是字节数,而是个数。例如:已知utf-8汉字占3个字节,对于varchar(20),不论是存储英文,或者汉字,都最多存储20个,只是在容量上大小不一致(存英文:20*1字节;存汉字:20*3字节)。
因此,varchar长度的确定取决于所要存储的字符串最大“个数”
2) 存储大小:Varchar最大65535字节;Text最大65535字节;Longtext最大4294967295字节
插入超过指定大小的数据时:Varchar无法插入,Text、Longtext截取符合大小的部分数据进行存储。
检索效率:varchar>text>longtext
Q13.怎么进行分页数据的查询,如何判断是否有下一页?
1) 使用关键字limit
Select * from table_name limit 第几条数据-1, 当前页数据数

注:第几条数据-1 = (页码-1)*当前页数据数
例如:此时第二页的sql查询语句即为
Select * from applicant limit (2-1)*5, 5;
2)查询前通过count(*)查询数据总条数
通过 第几条数据-1+当前页数据数 > 总数据数 可判断有下一页

Q14.为什么不可以用Select * from table?
这个问题百度了后感觉有些复杂,我重新组织一下。
Select * 对比select 列1,[列2, …],效率上没有太大差别,只是在程序设计时对于非编写者阅读性差;对于程序今后的拓展性方面,程序所需的列时确定的,但若数据库新增一个字段,又会造成不必要的查询;对于覆盖索引,select *在读完索引后还会去读数据,造成性能上的差别
2. JDK和JRE的区别
JDK,全称Java Development Kit,Java开发工具包,包含了开发Java程序所需要的工具像javac.exe和各种类库,并且包含了jre
JRE,全称Java Runtime Environment,Java运行环境,其核心是jvm和基础类库。
综上,两个最大区别是jdk是工具集合,jre是运行环境
3. 下载Maven3,并配置好环境变量。
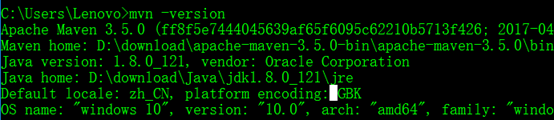
4. 下载Eclipse或者是IDEA,配置好Maven。
Ide选择了Eclipse,因为是Javaweb开发,我选择了EE版本:

下载安装后选择工作空间:
配置maven
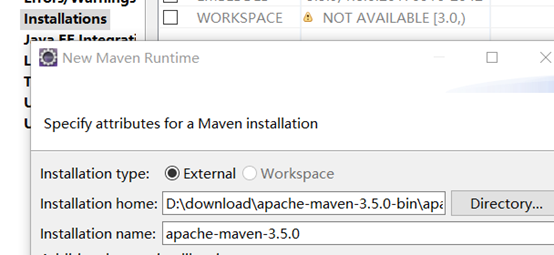
新建本地仓库repository后,修改maven/conf/settings.xml文件,添加语句<localRepository>本地仓库路径 </localRepository>
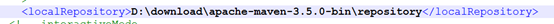
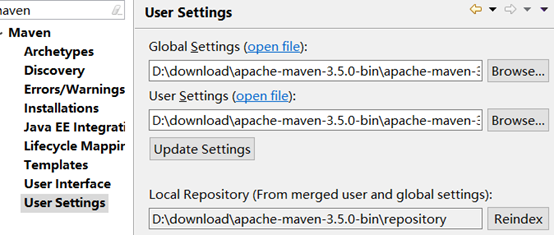
再次打开eclipse修改/preference/maven/user settings/
将settings指定到安装的maven/conf/settings.xml,并修改本地仓库路径
5. Q15-16、Q18
方法一:使用eclipse新建项目:
方法二:手动建maven项目
新建项目结构:
Src
-main
-java
-package
-test
-java
-package
resource
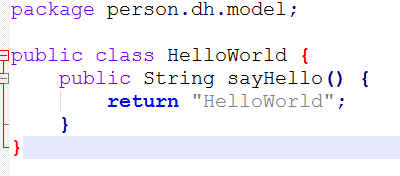
编写代码:
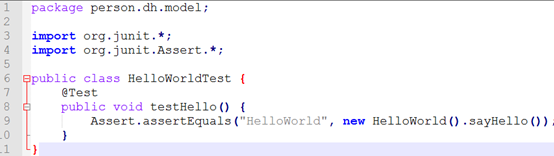
Junit测试模块:
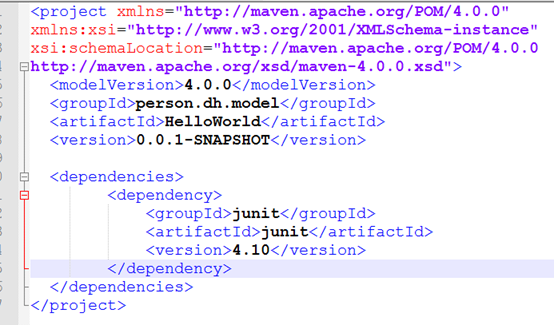
编写pom.xml文件管理项目并保存到项目目录下 maven01/
使用命令行进入项目编译项目:
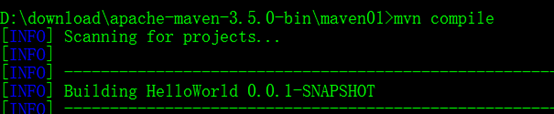
成功标志:

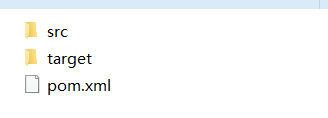
编译后发现项目下多了target的文件夹:
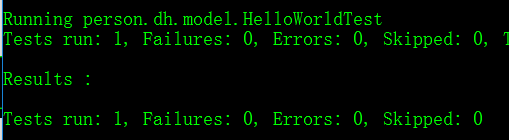
使用junit测试:

使用clean命令删除Target文件:

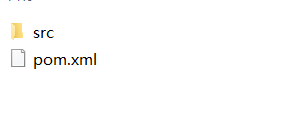
应用install命令:
新建maven02项目,导入maven01的类

编译maven02项目:
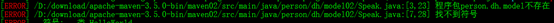
此时就需要通过install命令将maven01安装到本地仓库:

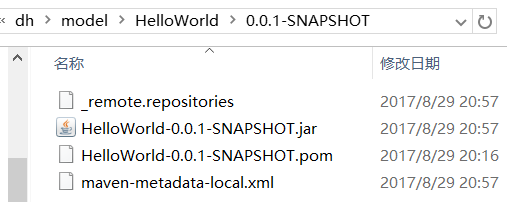
进入本地仓库可以看到多了个“person”文件夹,打开后:
然后在maven02的pom.xml文件中引入maven01项目的坐标
![]()
![]()

再次编译maven02则成功了
注:
GroupID 是项目组织唯一的标识符,实际对应Java的包的结构,是main目录里java的目录结构。
ArtifactID是项目的唯一的标识符,实际对应项目的名称,就是项目根目录的名称
Maven的命令:
Compile 编译
Package 打包
Test 测试
Clean 删除target
Install 安装jar包到本地仓库中
6.
二、 明天计划的事情
至少完成今天计划完成的,然后感觉今天maven学的不好,需要再次学习
三、 遇到的问题
1. 在列值唯一性差(较多重复)的列上创建索引是否会“浪费”?或者说没必要。具体是原因是什么?
2. 对于深度思考的q14为什么不可以用Select * from table?,请师兄指点一下
3. 为什么有java8不用而用java7呢?
四、 收获
1. 深度思考中mysql部分
2. Maven的使用
3. 最重要一点:学技术不可急!!!
今天本来打算做到Q20的,学习maven的时候一开始还打算直接使用ide建项目,建了后随便测试一下clean和install命令,然后就突然意识到这样毫无意义,只是为了应付任务。结果就是花了4个小时的时间折腾maven,emmmm…..感觉挺好,哈哈




评论