发表于: 2017-08-22 17:34:18
2 963
今天完成的:
测了自己写的缓存
收获:
1.给map本地缓存加了持久化,可保存到本地读取。
2.测了不用缓存和用缓存的接口响应时间。接口是查出DB中1000条数据。
单线程循环100次,未使用缓存

单线程循环100次,使用缓存

90line差了20ms,基本差不多。没用缓存的出了一些失败请求。用缓存的吞吐量提高了一些
5个线程循环100次,未使用缓存。

5个线程循环100次,使用缓存

不停运行了三次,直到90line稳定。这个加缓存的快了不到200ms,还是比较明显的,另外错误率为0%。
可以继续优化,map加锁的过程拖慢了缓存,代码太冗余也是一个原因,不然可以更快
3.在持久化过程中考虑使用多线程加速。发现写文件的过程不能并行,同一时间内只能允许一个线程写入数据。所以必须要加锁,浪费性能。而且写文件的瓶颈在磁盘IO,而不在CPU。并行越多寻址次数越多,性能反而成指数级下降。多线程写入数据反而不如单线程顺序写入快。但读文件可以用多线程减少耗时。
4.工作流程
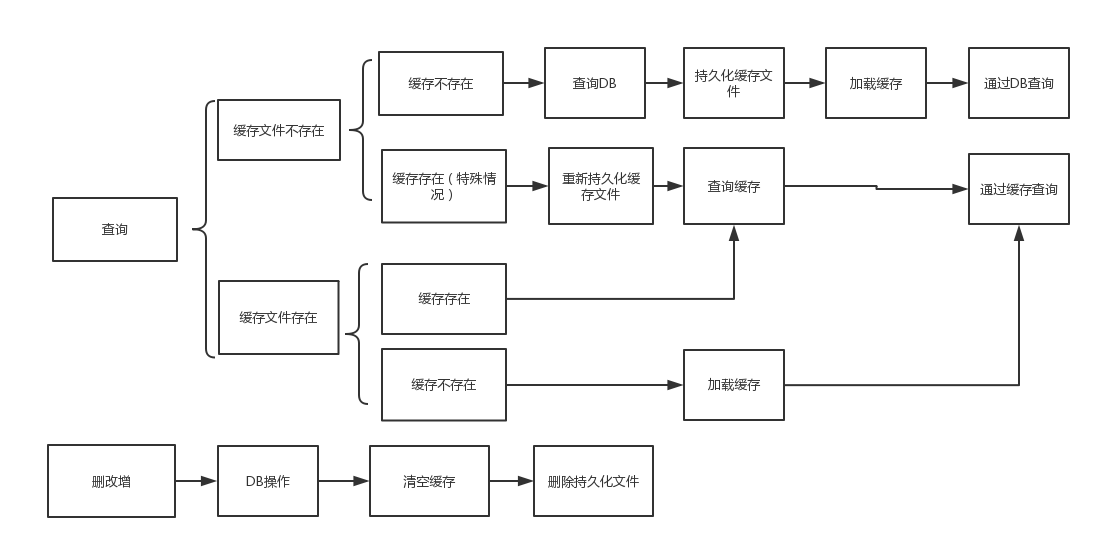
5.线程安全的Map的几种实现
synchronized加锁
lock锁
Collection.synchronizedMap()方法
并发包下的ConcurrentHashMap类
按网上的说法,ConcurrentHashMap效率最高,sync加锁是最慢的,未做测试
6.找到一个LinkedHashMap,它的迭代顺序就是最后访问其条目的顺序,从近期访问最少到近期访问最多的顺序。类似缓存中的LRU算法,好像就是LRU的实现。他有一个removeEldestEntry方法,通过这个控制记录数量,淘汰旧的数据。有时间实现一下。
问题:
1.一直在考虑如何用自定义注解实现,这么写缓存会和service层有一些耦合。
2.理论上内存多大,map就能放多少,更新策略是先删除,再生成缓存文件,在数据较大的情况下会浪费性能,可以改为append。
3.可以设置一个开关,当缓存文件过大的时候使用多线程读取并加载缓存。
计划:
明天本地测下前台页面接口
进度:
延期
预计月底demo
http://task.ptteng.com/zentao/project-task-277.html




评论