发表于: 2017-08-11 22:35:55
2 916
一、今天完成的事情:
面试了一波,记录一下那题目:\ \
100W条数据,从中选出值最大的100条数剧,怎么样查效率高?
堆排序是利用堆的性质进行的一种选择排序
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无须区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
这样我们的时间复杂度为O(log2n).因为堆是不稳t定的所以平均时间是接近于最坏时间复杂度的。,
如下是代码实现:
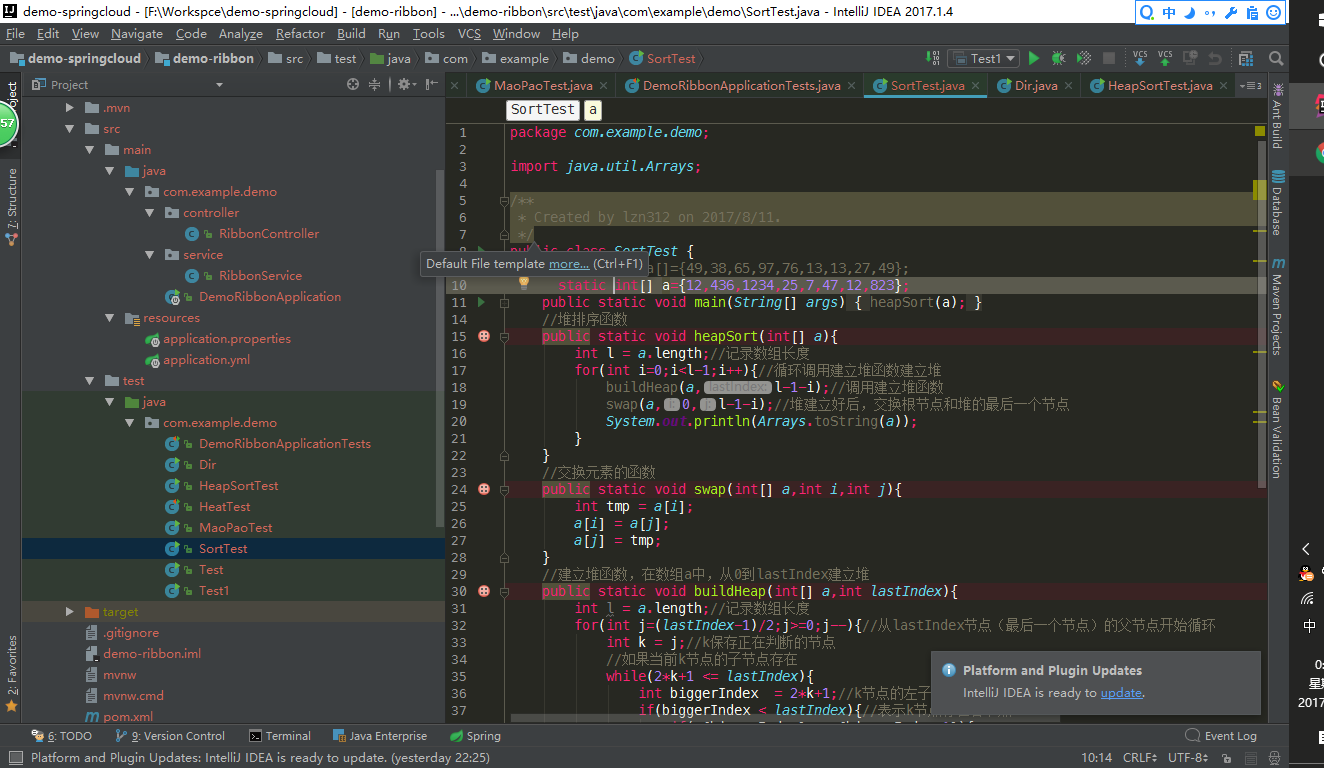
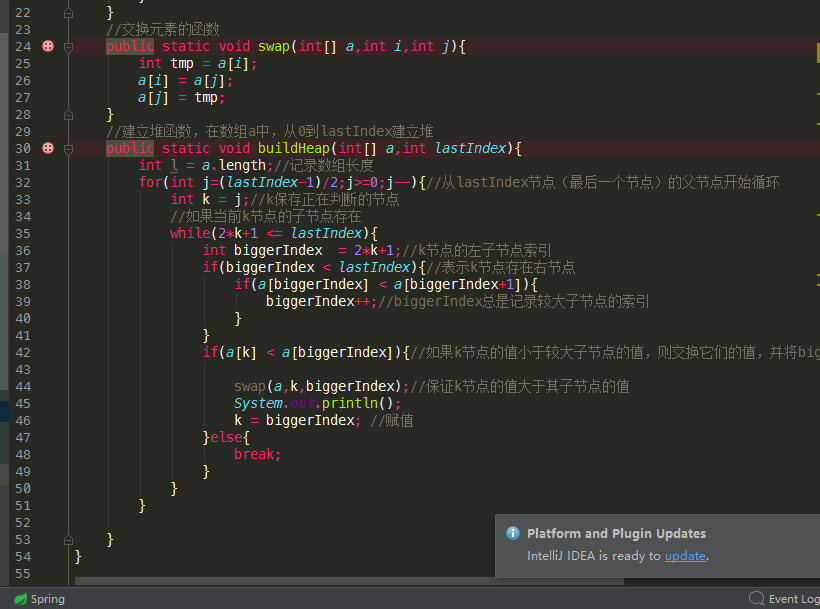
二、遇到的问题:其实这样做到头来还是遍历了数据排序确定。
三、明天计划的事情:
四、收获:有大佬告诉其实可以用二分排序加小端校验选出100条无序的数据,在使用插入排序。这样的效率应该是最高的,还没有理解,还在想。




评论