发表于: 2017-08-09 13:07:46
5 1288
今天做的事:
今天上午有回顾一下昨天学习的Nginx,然后尝试了一下配置静态服务
同样是修改配置文件nginx.conf中的server块
server {
listen 80;
server_name localhost;
location / {
root D:\www;
index index.html index.htm;
}
location /images/ {
root D:\image;
autoindex on;
}
}
这里每个字段的意思是:
listen:监听的端口
server_name:你的IP或域名,自己随便取名是不允许的!(除非你使用的是子域名,但子域名已经在hosts文件中进行了相关配置,不然也是不可以的)
location块:该处是一个定位的功能,比如上面的代码中,/代表所有url的匹配,root定义的是本地的资源包,index定义的是导航页面;下面的代码是匹配/images/的url,如localhost/images/1.jpg,autoindex进行自动匹配资源
这样一个静态服务是配好了,但是问题来了,我的服务访问自己定义的index.htm页面没问题,但是访问静态资源图片时就出现404错误,不清楚问题出在哪,百度也没找到解决方法,限于时间问题,放弃。
恰好老大巡视,顺便问了问题,然后解决了。
问题的关键在于关键字root和alias的区别:附链接http://blog.csdn.net/line_aijava/article/details/71473793
正确的代码块应该是
location /images/ {
alias D:\image\;
autoindex on;
}
这里那个alias后的\不能少
这里的意思就是,如果我使用root访问源文件夹,那么Nginx请求会有一个拼接的过程
比如我打出的url为http://localhost/image/1.jpg
关键字为root的请求为http://localhost\image/image/1.jpg
而使用alias关键字后,请求的url就是http://localhost/image/1.jpg
具体的解释等请看上面的链接
然后具体问题是什么就不必讲了,很简单的一个点,主要想讲一下老大解决问题的过程,感觉学到了
首先一上来就看出差距了。。。
先是给老大演示了一下案发现场,然后老大做的第一件事是还原案发现场。
然后第二件事,找到错误代码块,因为上半部代码块成功了,所以锁定问题在下半部。
第三件事,看error.log日志这也是我最欠缺的地方,昨天今天卡了这么久,虽然看过日志,但看的不仔细,就扫了一眼,需要加强。
第四件事,测试,就是各种测试,寻找发生错误的原因。
最后一件事,百度。。。(也是最看出差距的地方)看到老大百度问题,瞬间感觉到差距,因为通过恰当的关键字组合能最快的搜索出想要寻找的解决方案,这也是我最需要也最有待提高的部分,因为总感觉自己搜索东西很欠缺,总是驴唇不对马嘴,这个要学习加强。
暂时学到这些,话说老大解决问题的时候,我亚历山大。。。。
然后又回顾了一下子域的配置过程
server {
listen 8080;
server_name wojuedeok.com;
location / {
proxy_pass 服务器IP;
}
}
hosts文件中相应加入
服务器IP wojuedeok.com
我理解的过程如下:首先在浏览器中输入url
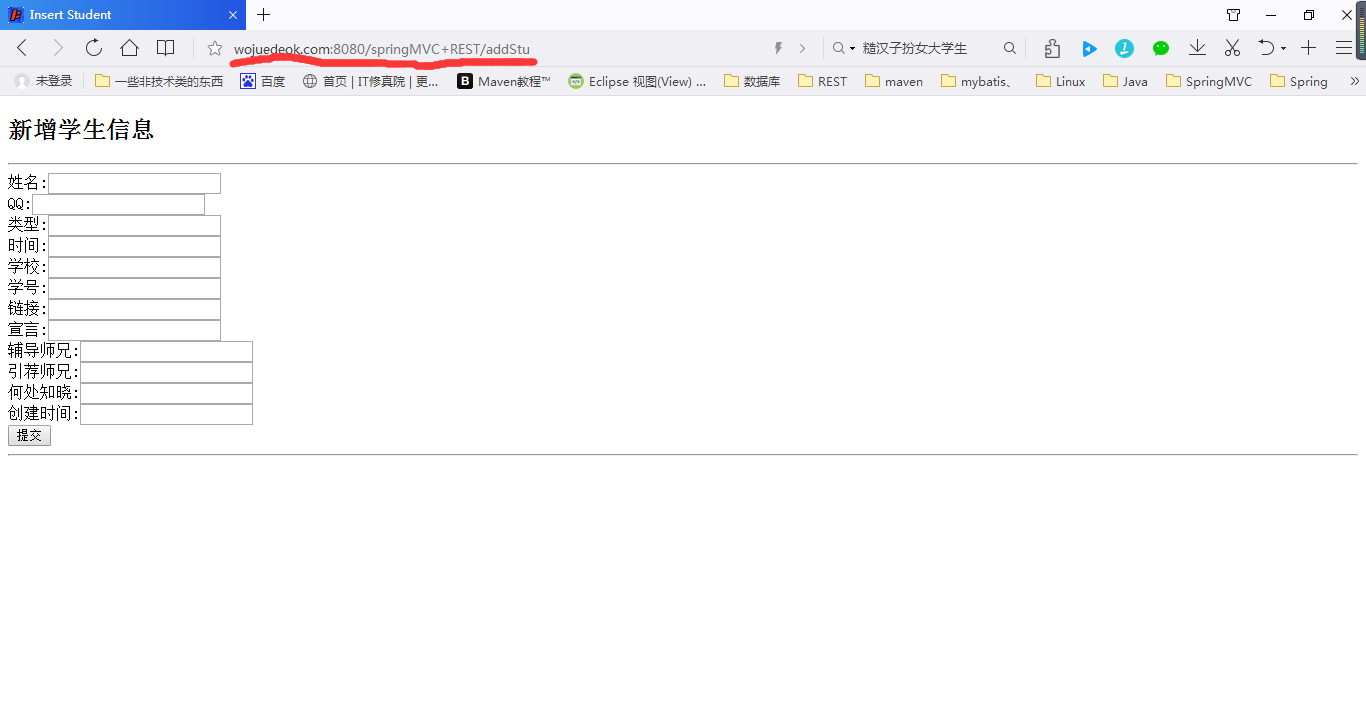
这里就是通过子域访问,本地hosts文件将子域名转化为服务器IP,在经由Nginx监听8080端口
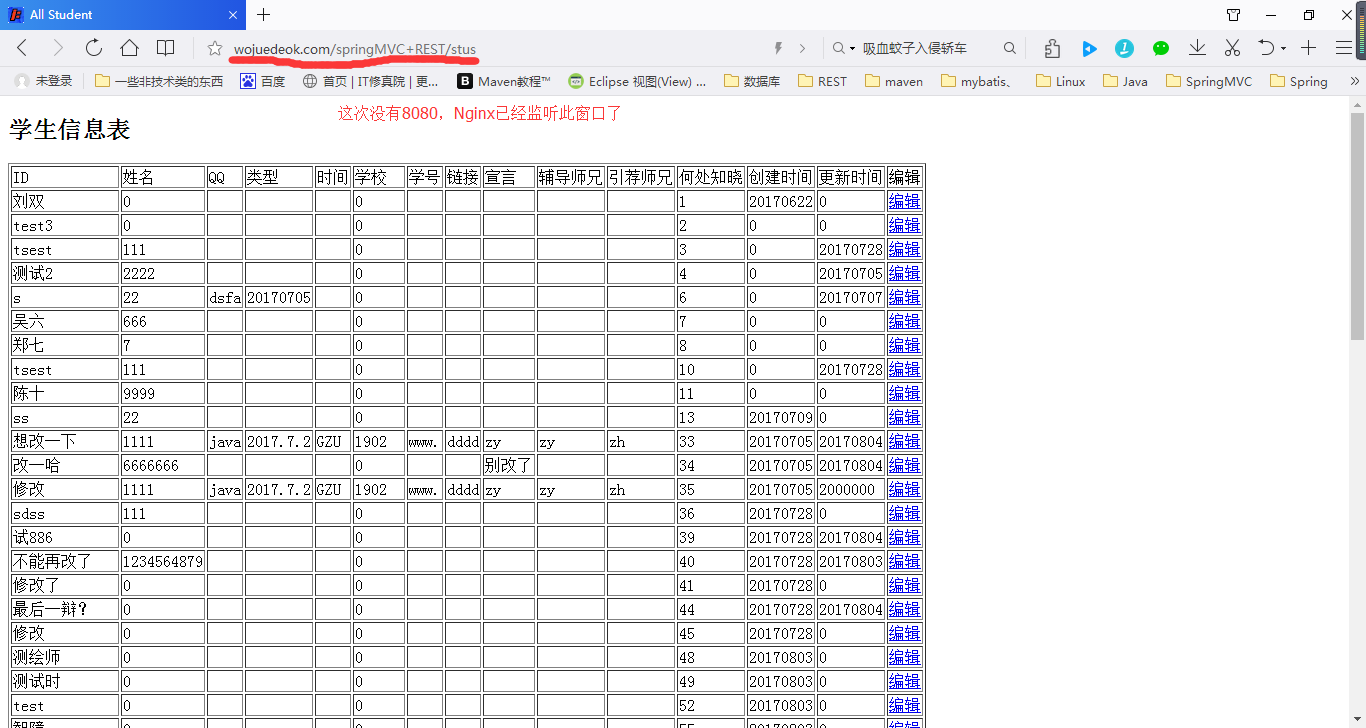
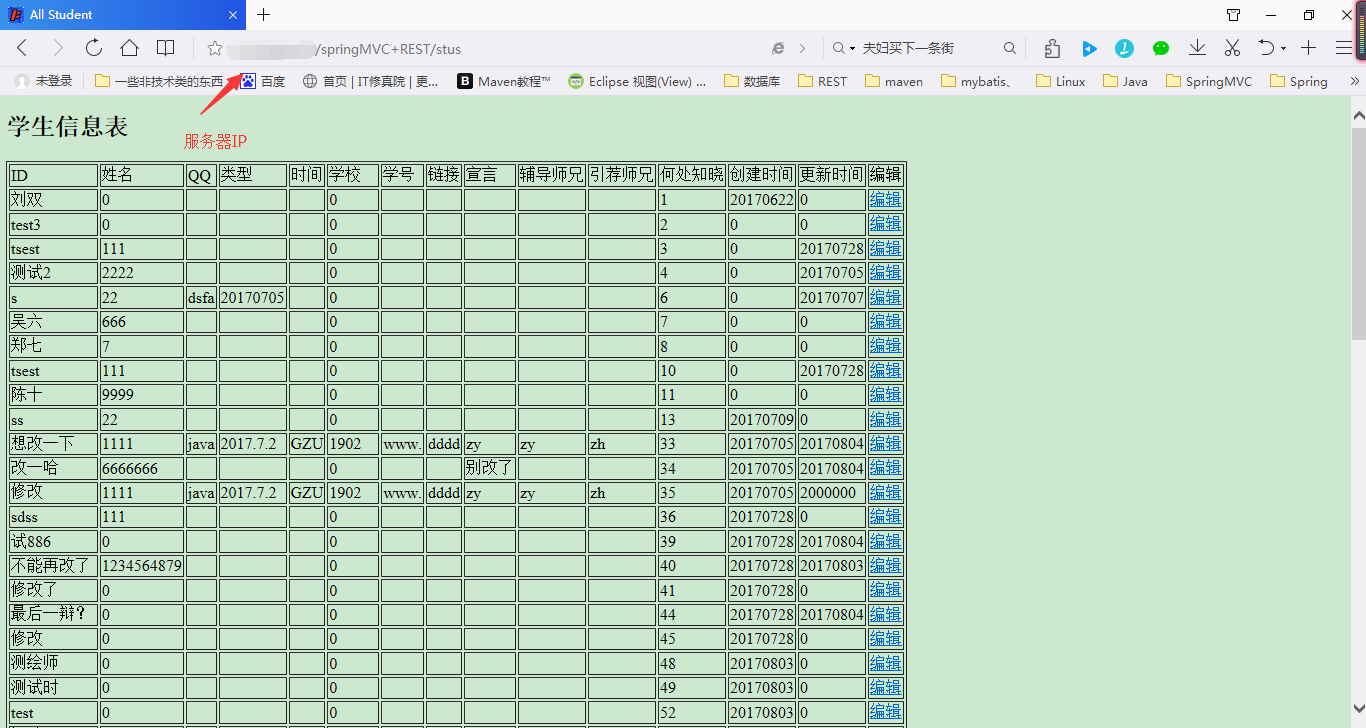
可以看到子域访问成功,你肯定奇怪,jetty的端口不是8080吗?为什么没加端口号也可访问,这是因为我在服务器的Nginx上同样配置了监听80端口,然后使用proxy_pass进行代理服务,代理本地8080端口。
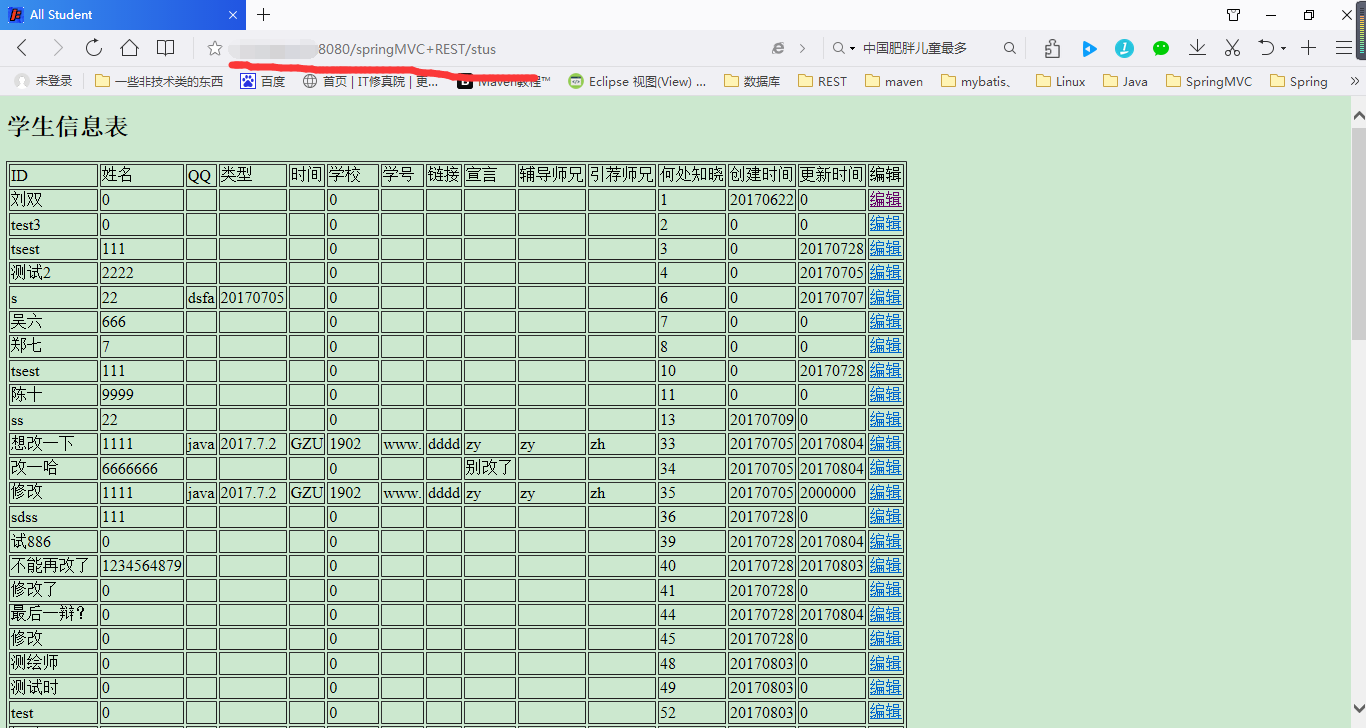
可以看到,我将配置文件改掉,用8080端口正常访问,在使用80端口访问
至此,可以说终于对子域访问进了比较全面的理解。
一个错误
OpenEvent<"Global\ngx_reload_6360"> failed <2: the system cannot find the specified>
原因:nginx未启动
之后开始做Nginx的统计,因为Nginx监听时会有很多抓包的ip来干扰,所以需要就行过滤。
cat /usr/local/nginx/logs/access.log |grep 'springMVC+REST' > a.txt
这里的|管道命令,是将一个命令的标准输出管道为另外一个命令的标准输入;而grep命令是一种强大的文本搜索工具,全称是Global Regular Expression Print,它能在文件中搜索符合要求的文本,并把匹配的行打印出来。
使用方法是 grep 参数 查找条件 文件名。
然后>命令和>>一起讲
linux命令>和>>的区别
简单说>是覆盖,>>是追加
> 是定向输出到文件,如果文件不存在,就创建文件;如果文件存在,就将其清空;
>>是将输出内容追加到目标文件中。如果文件不存在,就创建文件;如果文件存在,则将新的内容追加到那个文件的末尾,该文件中的原有内容不受影响。
再查看a.txt文件即可看到
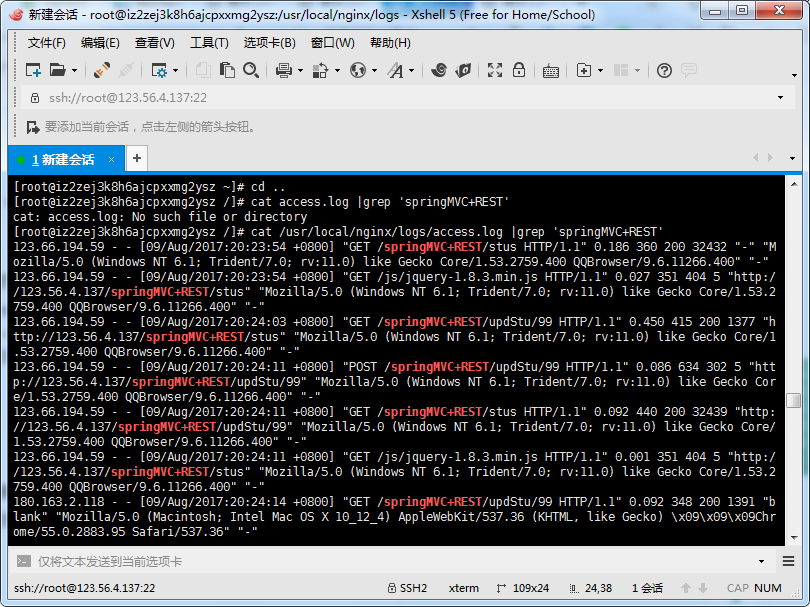
然后使用命令可以统计行数

这里其实可以将两个命令组合,就直接打印行数了。
然后使用命令可以统计延时响应时间
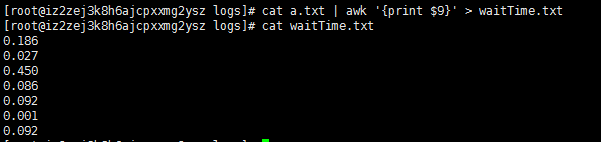
这里介绍一下 awk 命令
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键"
这里使用的awk将之前输入a.txt文件的每行字符串分隔,然后使用参数 '{pring $9}'打印这行字符串的第9段
至此,完成 查看Nginx日志,编写脚本统计访问次数,统计响应延时。




评论