发表于: 2017-08-06 21:50:58
1 894
今天完成的事情:
1、用postman测萝卜多复盘代码接口的访问耗时。
其中前台的 /a/jobInfo/search 达到了3000ms以上,
原因在于返回的data中的“tagList”部分消耗性能,在截图里可以看到tagList 是一个String 数组、而在代码里,循环生成这个数组时,它的外层还有一个循环。也就是每个循环内都会有另一个循环生成标签数组。
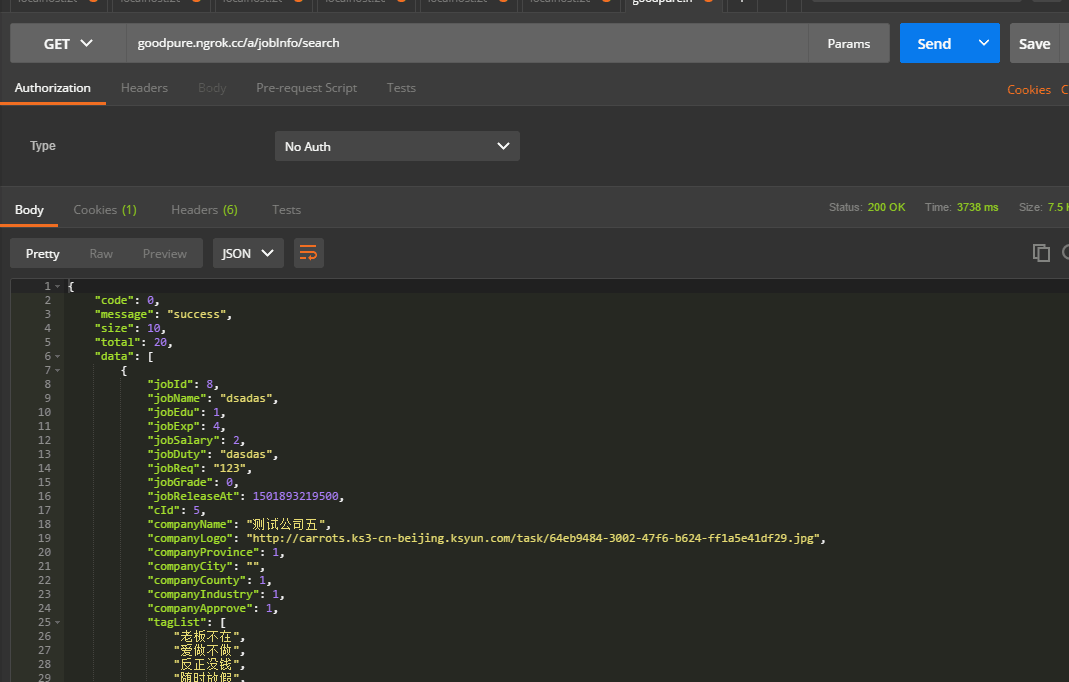
这个接口需要返回的是:每个职位,以及他们属的公司的一些字段、和公司的标签。
所以我写这个接口的思路是,先多条件查询到所有的 Job(id, cId, ....)。
遍历 Job 列表,从中取得公司ID,搞出一个公司ID列表。
通过公司ID 列表取到 公司列表。 通过“company_tag 表 (公司-标签关系表)”,
用公司ID去取出 companyTag对象的集合。
使用 MyListUtil 的 convert2ListMap(Field f, List datas)方法,传入 companyTag 的 cId 字段和 companyTagList。
得到一个 “公司ID——标签ID集合”的 Map,键为公司ID,值为标签ID(tagId)集合。
最后一步就是返回数据了。
①因为首先这个 接口返回的 是职位列表。所以拼装返回数据部分代码的主体结构肯定是遍历一个职位列表,
遍历职位时,又通过每个职位的的公司ID关联到了它的公司信息。
然后
②之前不是写过一个 又通过公司ID关
MyListUtil
getDistinctList
getUniqueList
2、
明天计划的事情:
1、复盘收尾,检查可以优化的地方。
2、了解rmi,Tuscany,wsdl,dubbo 之间的差异。
3、继续看博客和官方文档学习shiro。
4、熟练使用 MyListUtil、MyMapUtil 中的各个方法。
遇到的问题:
1、碰到稍微复杂一点的数据结构时容易晕。
收获:
1、这两天通过网上的博客又多了解了一点 shiro 框架。
3、如果通过了复盘,之后应该要做真实项目,当中应该会有几天空档。。




评论