发表于: 2017-07-20 22:23:15
2 993
一 今天做的事情:
1 学习了索引相关知识:
A 一个数据库对象,唯一作用是通过使用快速路径访问方法来快速定位数据,加速对表的查询,减少了磁盘的I/O。我的理解:索引就是目录。
B 在数据字典中独立存放,但必须属于某个表。在MySQL中同一个表内的索引不能同名,在Oracle中无论是否是同一个表索引名都唯一。
C 创建和删除索引都有自动和手动两种方式。
a 创建索引语句:
create index 索引名
on 表名(字段名1,字段名2...);
b 删除索引语句:
drop index 索引名 on 表名
c 自动不再详述。
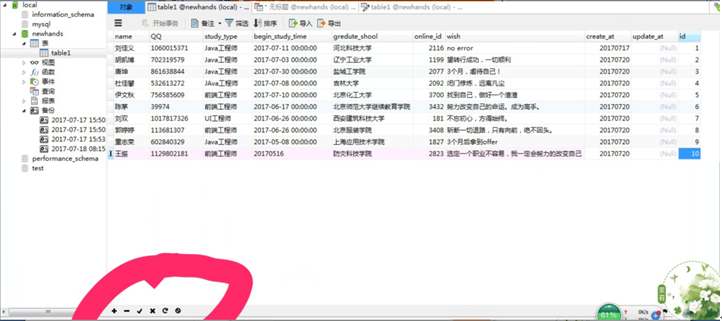
2 Navicat添加记录的方法:
(1 如图,下面洋红色圈起来的地方,点击+增加一条记录,-减少一条记录,在完成操作后点击对号保存操作。
(2 选中任何一条语句的任何一个字段,按键盘上的向下的方向键就能新建一条记录,超快捷。
3 索引总结:
http://blog.csdn.net/xluren/article/details/32746183
这篇博客关于索引写的很好,分享。我上面只说了任务中需要的一些基本的概念和语句。
4 实际操作:
a 给姓名创建一个索引:
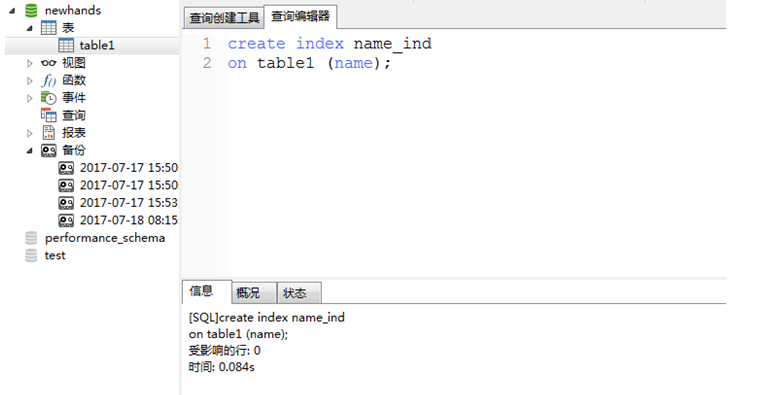
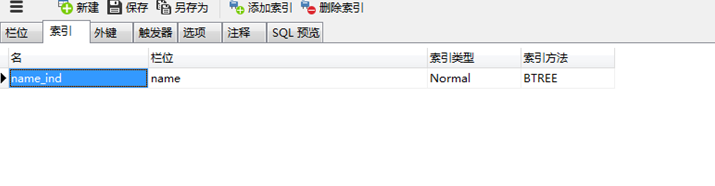
b 思考一下还应该给哪些数据建索引?
插入10条数据:方法有两种,用Navicat和SQL语句,我用的是Navicat:
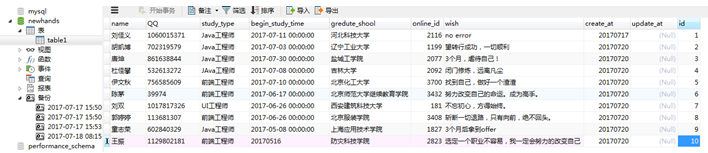
防灾科技学院莫名的笑点。。。乱七八糟的学校,我来淮阴工学院没学到什么,只学会了做小抄。

PS:我做的小抄不是吹,老师在我跟前我一样抄,啥事儿都没有。如果有师兄师弟师姐师妹看到这篇日报需要学习这项技能的话,我免费教。我觉得大学考试作弊不涉及什么公平的问题,我只想过,拿个毕业证而已。
回来接着思考:我做了6次查询:
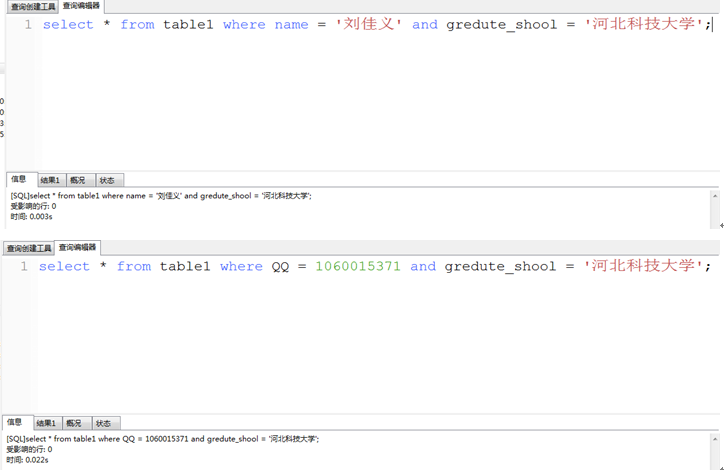
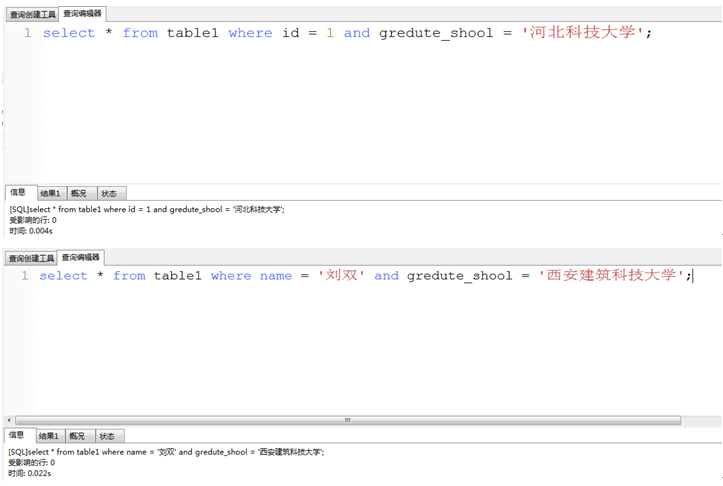
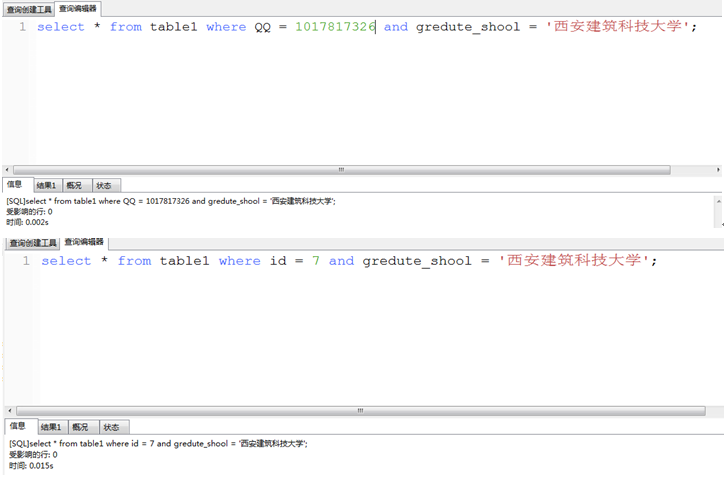
图有点乱,我用Excel表格来总结上面六个截图的数据:

字段name和id有索引,name为手动索引,id为自动索引,按照我的理解刘佳义的时间数据是对的,刘双的数据是错的,他的数据应该和刘佳义的数据差不多,即name+gredute_shool的时间约等于id+gredute_shool的时间,因为name和id都有索引,而QQ+gredute_shool的时间应大于上述两者,因为QQ没有索引。
网上翻了一下一些索引的东西,也明白了索引的原理。但是还是不能说明上述问题。可能是我的数据太少了吧,有索引和无索引根本区别不出来;亦或者我这种比较方式就是不科学的。等等。。。
既然达到了学习的目的,就不在意这些细节了。师兄如有兴趣可以解答一下,不过我相信我迟早会弄明白数据为什么是“错误的”。

哪位师兄能说下这个步骤11中所说的深度思考在哪么?想思考都不知道思考在哪,人生的悲哀不过如此。
二 明天要做的事情:
因为暑假开始就在学Java,对Java有些基础,下面的步骤应该会很顺利。
祈祷明天顺利吧。




评论