发表于: 2017-07-18 23:24:27
4 1328
今天完成的事情:
1.了解Debug模式
2. 尝试进行调试,对数据进行跟踪查看
3. 尝试向数据库插入100万条数据
明天计划的事情:
1.了解连接池,尝试配置
2. 买一台服务器,熟悉linux
遇到的问题:
1. IDEA链接数据库没有成功但没有表
点击数据库下方的Schemas-->ALL Schemas
2.在数据库中删除插入的几十万条的数据,没有删除
好像我电脑有问题,数据库发到师兄电脑上执行不到1S就删完了
收获:
1.日志的级别分
完成单元测试,到目前为止我还没有发现单
| Level | 描述 |
|---|---|
| ALL | 各级包括自定义级别 |
| DEBUG | 指定细粒度信息事件是最有用的应用程序调试 |
| ERROR | 错误事件可能仍然允许应用程序继续运行 |
| FATAL | 指定非常严重的错误事件,这可能导致应用程序中止 |
| INFO | 指定能够突出在粗粒度级别的应用程序运行情况的信息的消息 |
| OFF | 这是最高等级,为了关闭日志记录 |
| TRACE | 指定细粒度比DEBUG更低的信息事件 |
| WARN | 指定具有潜在危害的情况 |
log4j.rootLogger = debug,stdout,D,E
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=E://java/logs/springmybatis/error.log ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = logs/debug.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出ERROR 级别以上的日志到=E://java/logs/springmybatis/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ]
将DEBUG级别的日志信息输出到student,D和E处
org.apache.log4j.ConsoleAppender(控制台),
表示为输出日志的级别
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
%m 输出代码中指定的消息
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
%r 输出自应用启动到输出该log信息耗费的毫秒数
%c 输出所属的类目,通常就是所在类的全名
%t 输出产生该日志事件的线程名
%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
2. debug调试模式
- 首先打断点进入Debug模式
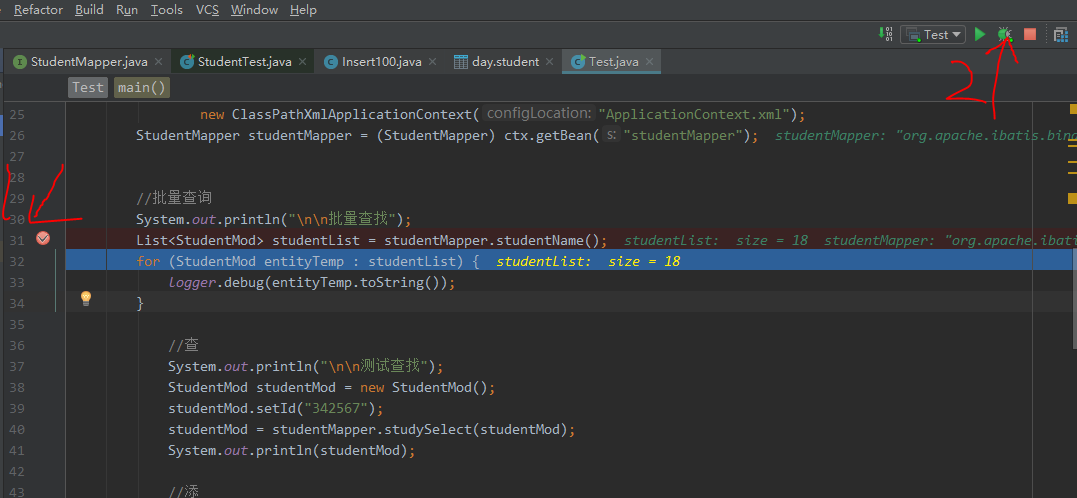
- F8执行下一步
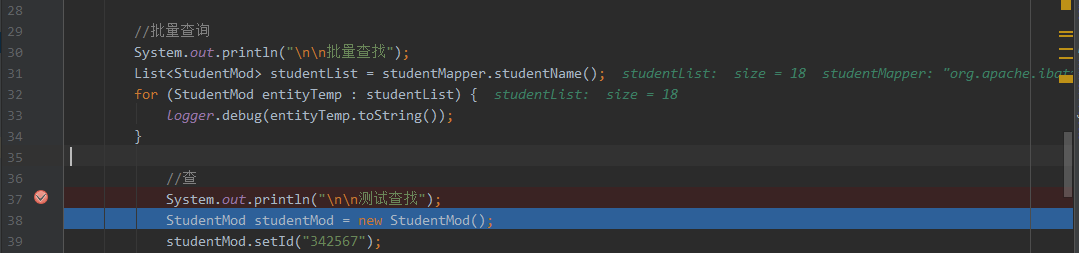
- 选中某个变量,ctrl+F1 常看详细属性(2)
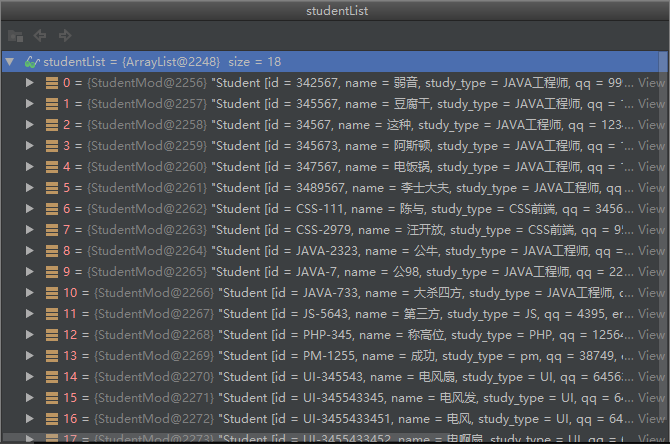
- F7,如果当前执行的不是方法,则继续向下进行如果是方法,则进入方法里, 开始单步执行如果其中还有方法,接着进入执行
- Shift+F8对应于F7,跳出执行的方法,返回调用该方法处(该方法已经执行),执行下一句
- F9直接执行到下一断点的位置为止
3. 尝试向数据库插入100万条数据
long k = 0;
// 保存sql后缀
StringBuffer suffix = new StringBuffer();
// 设置事务为非自动提交
conn.setAutoCommit(false);
PreparedStatement pst = (PreparedStatement) conn.prepareStatement("");
// 外层循环,总提交事务次数
for (int i = 1; i <= 100; i++) {
// 一次提交的记录
for (int j = 1; j <= 100; j++) {
// 构建sql后缀
Date nowTime = new Date(System.currentTimeMillis());
suffix.append("(" + k + ", " + k
+ ",'JAVAsds',111 , "+ nowTime +"),");
k++;
}
// 构建完整sql ,-1为去除sql语句最后一位的逗号
String sql = prefix + suffix.substring(0, suffix.length() - 1);
// 添加执行sql
pst.addBatch(sql);
// 执行操作
pst.executeBatch();
// 提交事务
conn.commit();
// 清空上一次添加的数据
suffix = new StringBuffer();
}
// 关闭连接
pst.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}catch (Exception e) {
e.printStackTrace();
}
用时178S
希望能想到更快的算法
参考资料:
关于批量插入数据之我见(100万级别的数据,mysql) (这个博客的代码有点小错误)
PS:开始接触linux




评论