发表于: 2017-07-15 23:43:16
2 1497
今天完成的事情:
24.直接执行Main方法,去在服务器上跑通流程。
在所需打包项目的pom.xml加入
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2-beta-5</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.summerwaves.service.TestInsert</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
打包后把jar包放到服务器上
命令行执行jar:
结果:

25.测试一下不关闭连接池的时候,在Main函数里写1000个循环调用会出现什么情况。
测试代码:
public class ConnectionPoolTest {
public static void main(String[] args) throws SQLException {
Connection conn = null;
PreparedStatement ps = null;
for (int i=0;i<1000;i++) { //循环一千次
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=true","username","password");
conn.setAutoCommit(false);
ps = conn.prepareStatement("insert into user (user_name,password,sex) values(?,?,?)");
ps.setString(1,"user");
ps.setString(2,"password");
ps.setInt(3,1);
ps.execute();
conn.commit();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
try {
if (ps != null) {
ps.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
注:循环调用jdbc插入1000次,不关闭数据库连接
560条数据之后出错

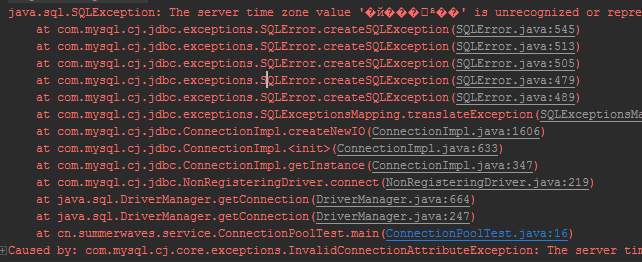
26.测试一下连接DB中断后TryCatch是否能正常处理。
测试代码:
public class InterruptTest {
public static void main(String[] args) throws SQLException {
Connection conn = null;
PreparedStatement ps = null;
try {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=true", "username", "password");
conn.setAutoCommit(false);
ps = conn.prepareStatement("INSERT INTO user (user_name,password,sex) VALUES(?,?,?)");
ps.setString(1, "user");
ps.setString(2, "password");
ps.setInt(3, 1);
ps.execute();
conn.commit();
conn.close(); //在这里提前把数据库连接关闭
} catch (SQLException e) {
e.printStackTrace();
}finally {
try {
if (ps != null) {
ps.close();
}
System.out.println("ps.close");
} catch (SQLException e) {
}finally {
try {
if (conn != null) {
conn.close();
}
System.out.println("conn.close");
} catch (SQLException e) {
e.printStackTrace();
}finally {
System.out.println("Catch success!");
}
}
}
}
}
注:提前执行conn.close()中断数据库连接
测试结果:
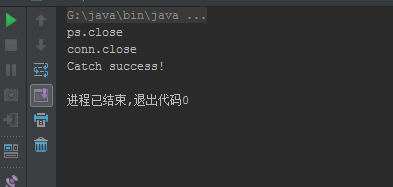
结论:数据库连接中断后TryCatch可以正常处理
27.检查一下自己的代码是否符合规范,如果DB的表格有改动,应该改哪些内容,需要多久。
mybatis和JdbcTemplate的不规范,总结的时候再把代码发出来,表格改动没想过,也想不太出来,先跳过,看看师兄的日报是怎么说的
28.数据库里插入100万条数据,对比建索引和不建索引的效率查别。再插入3000万条数据,然后是2亿条,别说话,用心去感受数据库的性能。
最终版测试代码:(双循环,每次插入100w数据)
public class InsertTest3 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Connection conn = null;
String sql = "INSERT INTO user (user_name,password,sex) VALUE ('username','password',1)";
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=true&useServerPrepStmts=false&rewriteBatchedStatements=true", "username", "password");
conn.setAutoCommit(false);
PreparedStatement ps = conn.prepareStatement(sql);
try {
long start = System.currentTimeMillis();
for (int i =0; i<1;i++) {
//long localStart = System.currentTimeMillis();
for (int j = 0; j < 1000000; j++) {
ps.addBatch(sql);
}
ps.executeBatch();
conn.commit();
//long localEnd = System.currentTimeMillis();
System.out.println("第" + (i+1) + "次");
}
long end = System.currentTimeMillis();
System.out.println("插入100万条数据所需时间" + (end - start));
} catch (SQLException e) {
e.printStackTrace();
}finally {
try {
if (ps != null) {
ps.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
测试结果
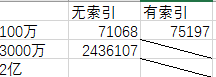
结论:
1. 100w有无索引数据对比
增加索引会增加数据的插入时间
2. 100w和3000w数据对比
从100w数据插入所用时间,按简单的乘法3000w数据所用时间应该是:71068 * 30 = 2132040
但实际插入时间却相差较大,可以初步得出结论:数据量越大,单位插入数据所用时间会更长
2亿的数据插入还没做,主要是C盘没那么大,也到凌晨了,明天插入2亿数据时把每100W所用的时间也打出来就可以知道结论是否正确了
明天计划的事情:
1. 把2亿的数据插入做完
2. 学习svn、github
遇到的问题:
上面的插入百万级数据的代码有两个循环
一开始我使用的是单循环,插入100w数据的时候没问题,但是插入3000w数据时报错(无论是使用PreparedStatement还是Statement)
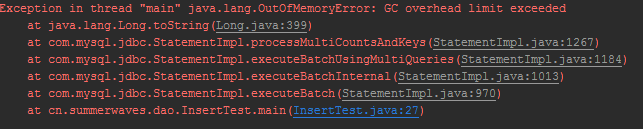
通过搜索引擎知道这是因为内存溢出发生的错误,通过jvm启动参数设置-XX:-UseGCOverheadLimit可以解决问题
但是还是出现了问题j
java.lang.OutOfMemoryError: Java heap space
还是内存报错
http://blog.csdn.net/hphua/article/details/51234499
找到了解决的方法,但是我没有去试有没有效果,
因为这时候我想到了使用双循环,每次插入100w,并且成功的插入了3000w数据
收获:
1. 数据库连接超过一定量之后就会无法再建立,理解了jdbc教程里的“每个连接都很珍贵”
2. 操作数据库的TryCatch与是否连接数据库无关
3. 数据库的性能和索引的多少、插入数据库的数据量的大小有关




评论