发表于: 2017-07-06 19:52:53
2 987
一.今天完成的主要内容
1.用存储过程向数据库插入多条数据
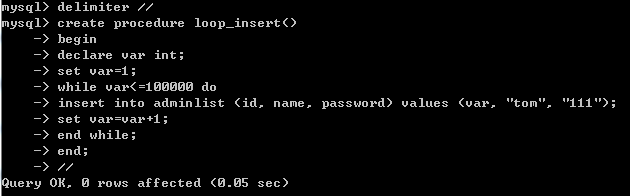
以上是sql的存储过程

以上是存储过程的执行过程,可以看到,插入十万条数据用了一个小时,而且只能插入相同的数据,效率非常低,以后肯定不会再使用
2.向数据库中插入了三十万条随机数据
方法是先用java随机生成数据,然后将数据写入.txt文本文档中,然后再利用navicat的导入文件功能将.txt文件中的数据导入到数据库中
(该方法比起存储过程快了许多,但耗费的时间同样非常多,以后肯定也不会再使用)
3.对比插入索引前后数据库查找数据的效率
插入索引前,查找比较靠后的数据如下:
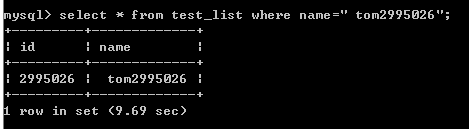
可以看到用时接近10秒钟,接下来是插入索引后的查找数据时间

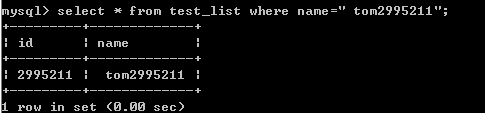
可以看到用时基本为0,速度快了不是一点半点.
4.尝试回答mysql中的深度思考问题
思考5: 为什么DB的设计中要用LONG替换DATE类型
选择数据类型时的两个原则,一是选择合理范围内最小的,二是选择相对简单的数据类型.因为日期加上时间(如YYYYMMDDHHMMSS)一般就是14位,8个字节的LONG整数类型(有符号的可以存放至少18位的数字)完全可以存放的下,所以根据上述原则,选择LONG类型替代Date类型,提高性能,尤其是在大型数据库中,性能提升会更加明显.再加上际应用中根据创建时间和更新时间排序是常有的操作,而使用LONG类型更容易进行排序,这样效率更高.
思考6: 自增ID有什么坏处?什么样的场景下不使用自增ID?
Mysql数据库中的id设为自增,容易产生id不连续的问题,如果一个表在创建时使用了自增ID,后续如果将该表中的数据删除了一部分,然后再添加一部分时ID依然是在未清除的基础上累加.还有当数据重复时系统不会处理.还存在一个问题,当两个表进行合并时自增ID不能保证数据的唯一.
思考7: 什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
索引就像是给无序的数据添加了一个目录,这样在查找数据时不用一个接一个的去找数据,而是通过目录快速对数据进行定位,提高查找效率.数据量越大,建索引和不建索引之间性能的差别越明显.因为每个索引都需要占用磁盘空间,所以索引也不是越多越好.如果一个字段经常需要进行排序,查询,那么这样的字段适合建立索引,简单的说就是频繁出现在where后面的字段就可以添加索引.如果该字段的值是唯一的话,那么还可以选择唯一索引,效率更高.
思考8:普通索引和唯一索引的区别,什么时候需要唯一索引
唯一索引基本和普通索引相同,其区别在于普通索引标示被索引的数据列中的值允许重复,但是被唯一索引标识的数据列中的值不允许重复.也就是说,唯一索引保证了数据的唯一性.所以唯一索引适用于对于每行数据来说都是唯一的那种数据,比如身份证号,学号,准考证号,电话号码,QQ号等.
思考9: 如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
不需要,因为唯一索引标识的数据必须唯一,数据库会检查该数据是否唯一,如果不唯一,该条数据是插入不到数据库中的,所以不需要事先判断这个QQ号是否存在.
思考11.修真类型应该是直接存储Varchar,还是应该存储int?
因为修真类型只有有限的几种,而且一旦写入一般不会更改,所以感觉可以在存储时使用tinyint类型,同时建立每种修真类型和整数之间的一一对应关系,比如java开发就用1表示,前端用2表示,这样不论是存储还是查找时速度都会更快,然后再创建一个表用于表示整数和修真类型之间的对应关系.感觉这样速度会更快一些
思考12. varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
Varchar类型的字符串是可变长度字符串,最大长度为65535个字节,但实际存储的数据最大长度要比65535要小一些,因为varchar类型会用一个字节来记录该数据值的长度,如果值超过255个字节,那么会用两个字节记录..varchar和Text之间最主要的区别还是在于varchar可以指定默认长度,而TEXT不能指定默认长度,使用时能用varchar的就不要用TEXT类型.
思考13 怎么进行分页数据的查询,如何判断是否有下一页?
在mysql中用sql语句是:select * from table_name limit start, pagesize;
其中start是从第几条开始,假设是1000,那么就是从第1001条数据开始,pagesize是查询的范围,假设是50条,那么就是查询从1001条到1050条之间的数据.如何判断暂时还没想到,还请师兄指点.
思考14.为什么不可以用Select * from table?
这条sql语句的功能是列出该表中的所有数据,如果一个表中的数据比较少还没有问题,如果一个表中数据量比较大,占用的时间非常多,而且没有什么意义.
5.配置maven文件,创建maven工程
创建出来的一个maven工程目录结构如图
通过mvn package命令,生成该项目的jar包,执行完毕后,可以看到在工程target文件下生成了jar包
然后再通过clean命令清理目标文件中的内容,执行完毕后,目录恢复到打包之前的结构
最后通过mvn install命令将jar包生成进本地仓库中,这样以后其他工程需要用到这个jar包时,可以直接在maven工程中添加依赖
执行完毕后,可以看到在本地仓库目录下生成该项目的依赖
二.明天的计划安排
1.编写DAO,尝试用JDBCTemplate和Mybatis链接数据库
2.学习Junit,尝试编写单元测试
3,如果进度较快的话,继续学习spring
三.遇到的主要问题
今天深度思考中的有些问题比较难.解决的方式是查阅各种博客技术文章,思考后得出一些自己的看法,不知道是不是准确,请师兄指点
四.收获
1.了解了sql存储过程的基本语法
2.了解了数据库普通索引,唯一索引,自增ID,varchar变量等更为细节的内容
3.了解了maven的作用,它主要是用来管理项目和依赖,能够自动生成比较规范的项目结构,并且只需要在配置文件中进行配置就可以使用jar包,而且可以通过命令完成编译,运行,打包的过程,大大简化了程序员的工作,提高工作效率.




评论