发表于: 2017-06-23 22:34:59
9 1198
首先:最后一题先写,给后来者当个教程
1.maven是什么,和Ant有什么区别?
Maven是一个项目管理工具,Ant 为 Java 技术开发项目提供跨平台构建任务
2.clean,install,package,deploy分别代表什么含义?
clean清除,install安装,package包,deploy配置部署
3.怎么样能让Maven跳过JUnit?
两种方法
mvn install -DskipTests
或者
mvn install -Dmaven.test.skip=true
4.为什么要用Log4j来替代System.out.println?
1.方便,Log4j只需要改配置文件就可以输出很多信息
2.DEBUG模式更是把方法调用信息都输出出来,简直太变态
3.增加扩展性,源代码不用动就可以改很多东西
5.为什么DB的设计中要使用Long来替换掉Date类型?
因为long相比date要节省空间
6.自增ID有什么坏处?什么样的场景下不使用自增ID?
删减后会造成数据不连续,在多表引用和数据迁移时候会遇到问题
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
索引目的是为了加快检索速度,数据量越大差距就越大,在数据重复度低的情况下建索引
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
唯一索引不能重复
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问
速度。
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
是的,需要判断,否则会报错
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
createAt在创建时就应该被自动赋值为佳(我还不会),updateAt在被updat
e语句修改时自动赋值(yeah),显然不应该。
11.修真类型应该是直接存储Varchar,还是应该存储int?
用int更省空间,最好用枚举.
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
varchar(M)M最大字符串255,text最大64kb,longText最大4gb。
13.怎么进行分页数据的查询,如何判断是否有下一页?
用ResultSet的rs.next()方法判断
14.为什么不可以用Select * from table?
因为真实的数据库数据量是非常庞大的,
所有的数据都遍历一遍会非常浪费时间
15.什么是贫血模型,什么是充血模型?为什么我们会强制要求使用贫血模型?
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层。
充血模型: 层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(Business Facade)->Business Logic->Domain Object->Data Access。
直接放个链接好了http://www.oschina.net/question/54100_10399
16.Spring中的IOC是什么意思,为什么要用IOC而不是New来创建实例?
IOC 反转控制 是Spring的基础,Inversion Of Control
简单说就是创建对象由以前的程序员自己new 构造方法来调用,变成了交由Spring创建对象
17.为什么要使用Interface,而不是直接使用一个实体类来完成任务?Interface和Implement这种方式的好处是什么?
先吐槽!单词忘记怎么拼了吧,忘记了写中文好不啦
1、重要性:在Java语言中, abstract class 和interface 是支持抽象类定义的两种机制。正是由于这两种机制的存在,才赋予了Java强大的 面向对象能力。
2、简单、规范性:如果一个项目比较庞大,那么就需要一个能理清所有业务
的架构师来定义一些主要的接口,这些接口不仅告诉开发人员你需要实现那
些业务,而且也将命名规范限制住了(防止一些开发人员随便命名导致别的
程序员无法看明白)。
3、维护、拓展性:比如你要做一个画板程序,其中里面有一个面板类, 要负责绘画功能,然后你就这样定义了这个类可是在不久将来,你突然发现这个类满足不了你了,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦。
如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
4、安全、严密性:接口是实现软件松耦合的重要手段,它描叙了系统对外的所有服务,而不涉及任何具体的实现细节。这样就比较安全、严密一些(一般软件服务商考虑的比较多)。
18.为什么要处理异常,TryCatch应该在什么样的场景下使用,在真实的系统中,会出现网络中断,DB连接不上的错误吗?多久会发生一次?
1.能让你知道哪里出了问题
2.捕获到异常可以事先进行预测并处理,让程序正常运行3.即使中途出错也会执行finally内的程序,如关闭连接等,
多长时间?谁知道呢,万一月经紊乱呢
19.日志应该怎么打,在什么位置,需要打印出来什么样的关键参数?
log4j有DEBUG,INFO,WARN,ERROR,FATAL几种模式
可以在log4j.properties文件中修改
og4j.rootCategory=INFO, stdout , R
stdout是输出到控制台,R是输出到文件
放个链接:
http://www.cnblogs.com/pigtail/archive/2013/02/16/2913195.html
20.为什么需要单步调试?Debug的时候IDE是怎么找到源码的?
单步调试可以更清晰的看到程序的运行过程
怎么找到源码的?what我母鸡啊,我只会ctrl+左键
21.可否远程连接到线上直接调试?真实的项目中,遇到问题的排查方案是什么?
应该不可以吧,程序正在运行,怎么调试,应该是停机维护
排查应该是先看日志,然后寻找错误,找到错误后,写测试代码上传测试(不对的还请师兄指正)
今天完成的事情:
今天结束任务一:
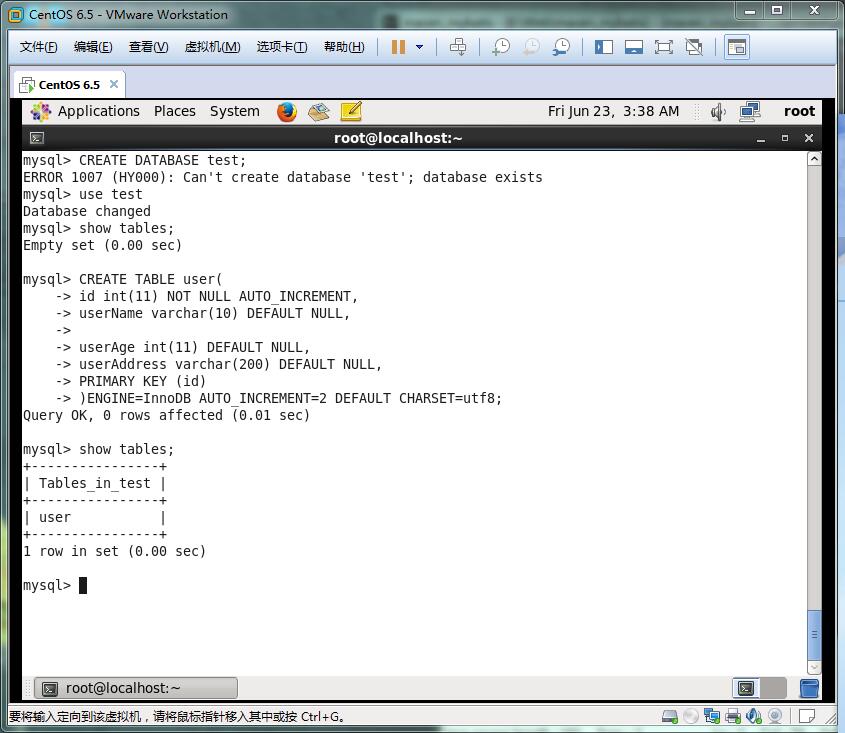
首先我创建了一个user表
然后写了一个mybatis
源码已同步到github:链接为
https://github.com/wudihui/MyBaits/commit/34b3fc8a2073641b2a2fb88dcaac5e5fe8392845
然后插入了一条数据
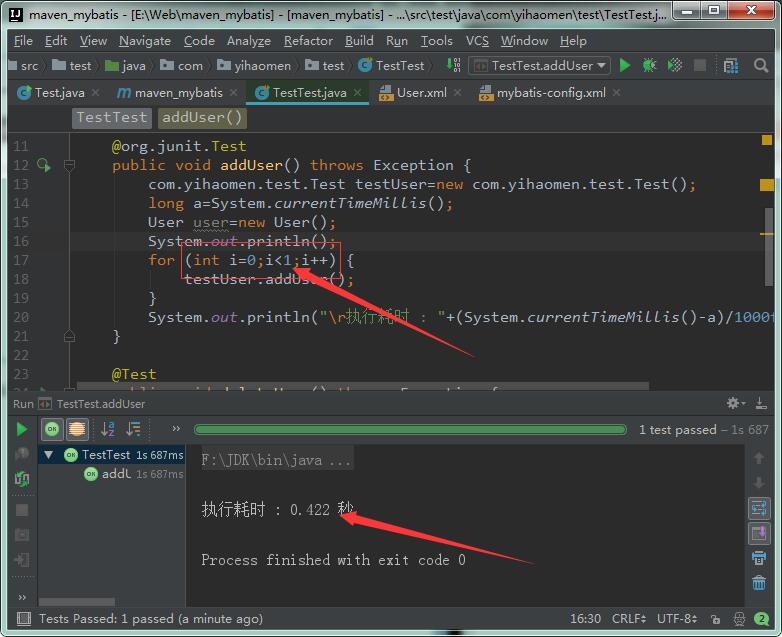
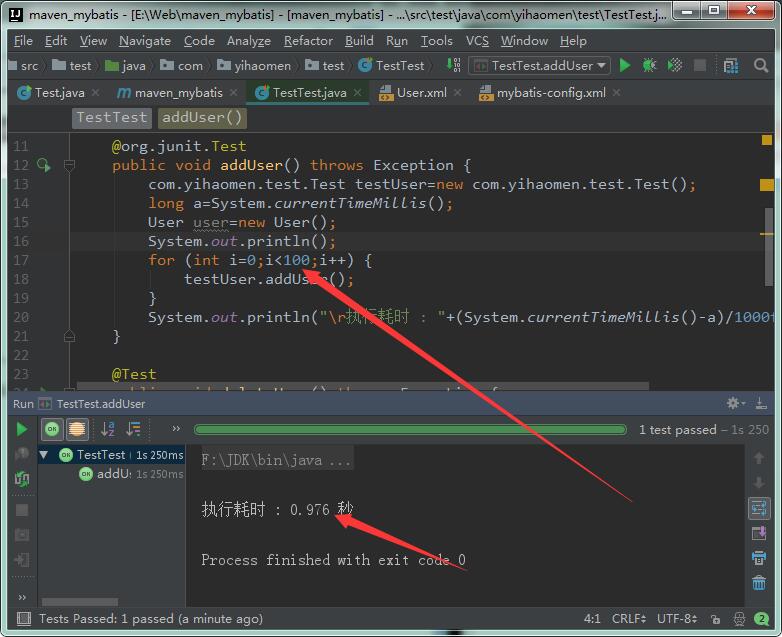
然后插入100条,由此可见创建一个Connection连接消耗了0.4秒如果没有线程池服务器效率肯定不高
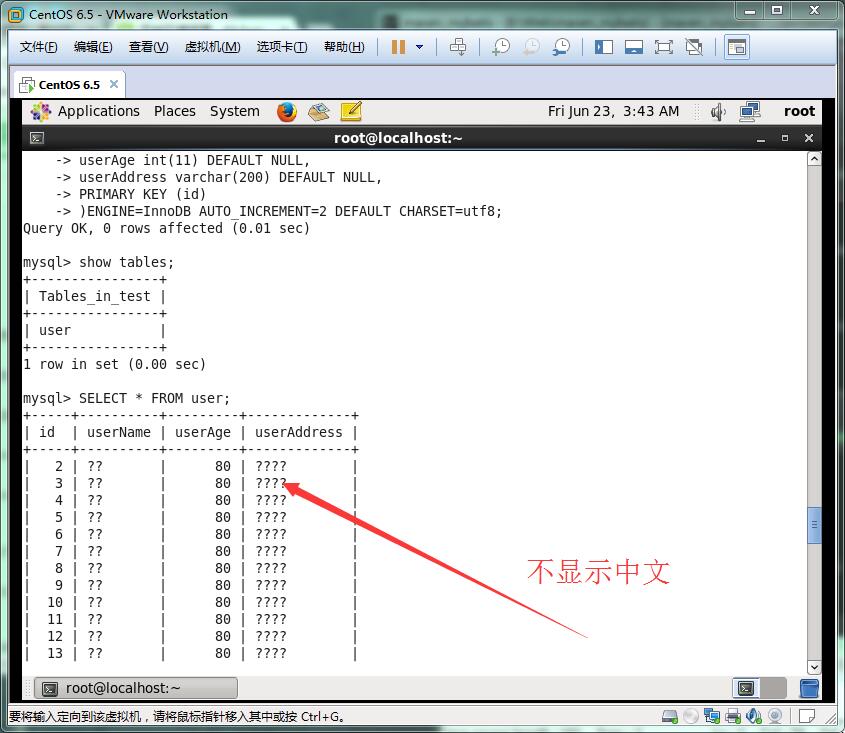
插入后查看发现是乱码,然后百度解决把字符编码都改成UTF-8
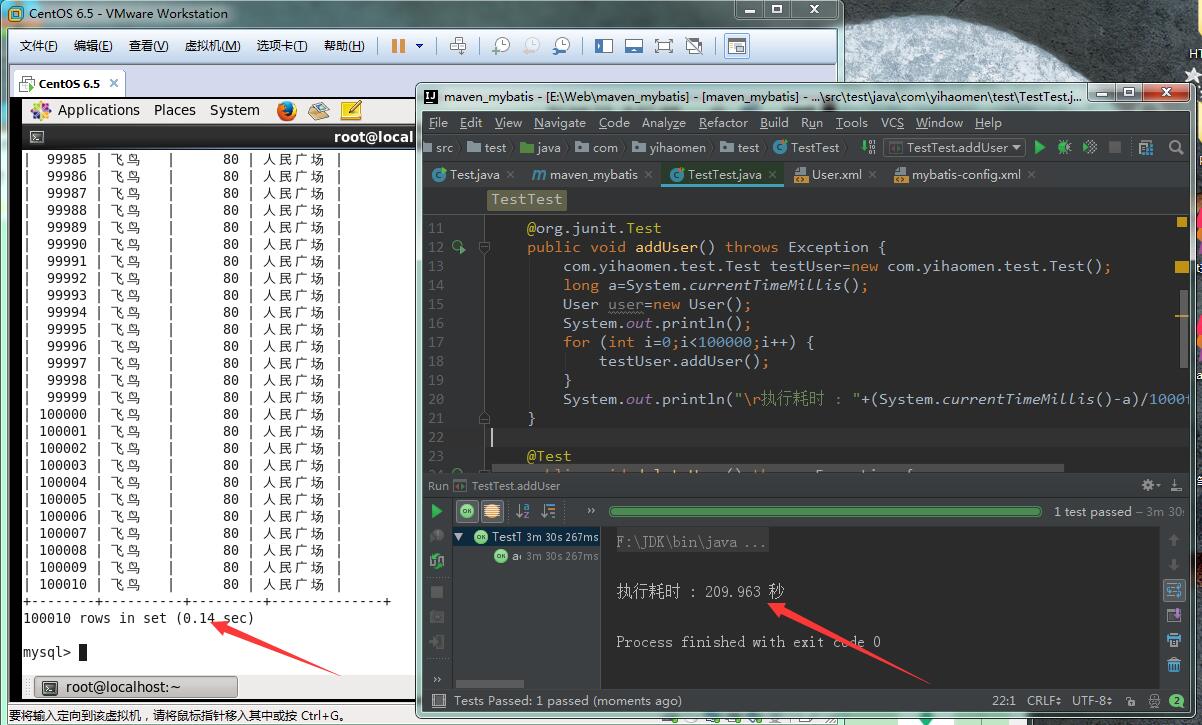
然后就是插入10万条数据
听着V12缸的电脑引擎的咆哮声表示很心疼
有索引的查询就是快,10万条数据查询不到一秒
但是插入就慢了,而且我不会建没索引的表,就不对比了
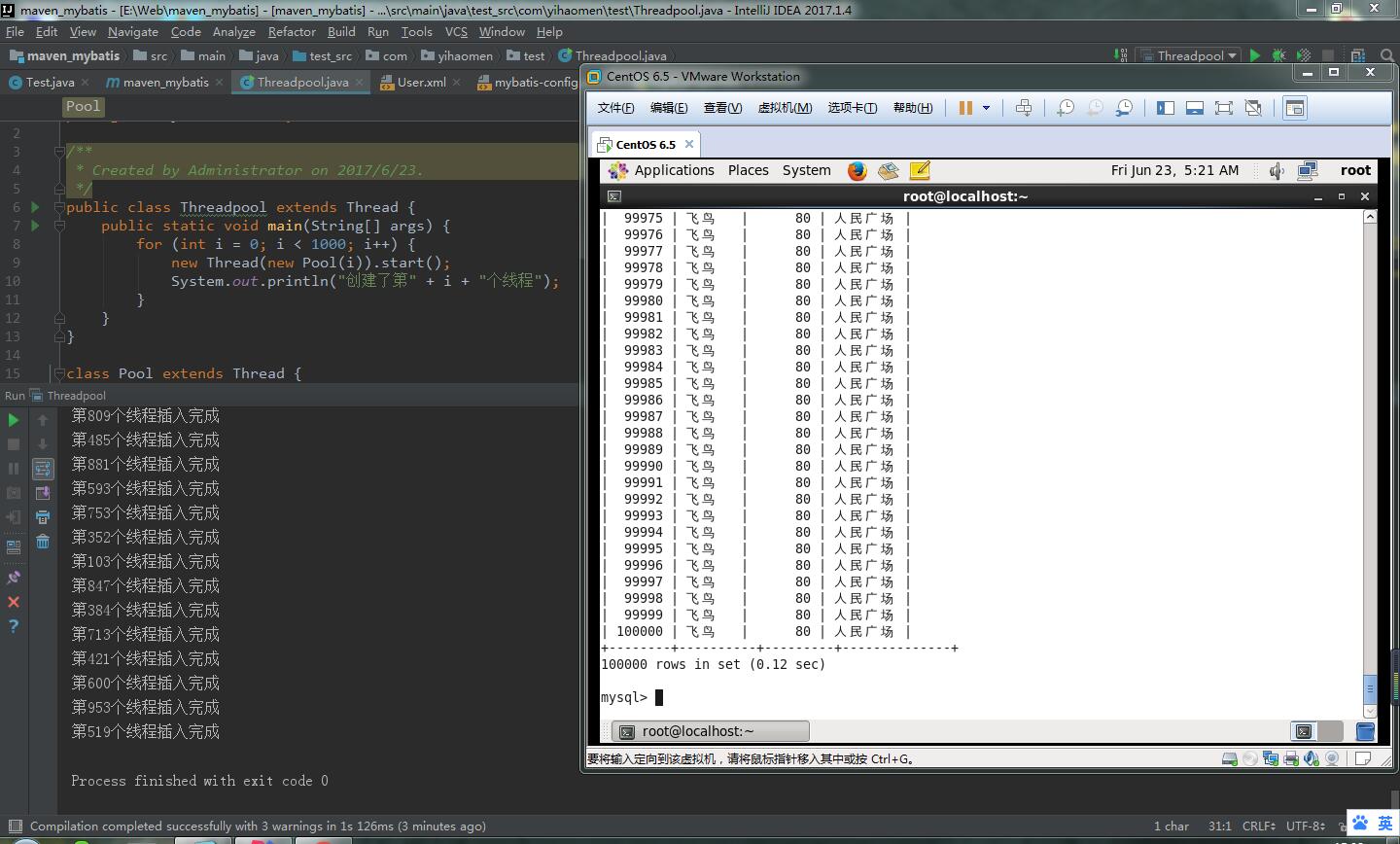
最后写了个一千个线程调用addUser方法,每个线程插入100条数据
然后发现线程创建后,线程是交替运行的,说明连接是有限的,至于如何分配就是有mybatis决定的了
其实结果之前就知道,但是亲手验证一下加深下理解
最后求上品啊师兄
让世界充满爱
明天计划的事情:
开始任务二
遇到的问题:无
收获:上面的都是我的收获




评论