发表于: 2017-06-20 20:19:31
4 1291
补回19日的日报和今天20
Java
昨天的日报没有写,听说今天扣分了,但是日报还是要写的,听师兄的话
Log44j
通常,我们写代码的过程中,免不了要输出各种调试信息。在没有使用任何日志工具之前,都会使用 System.out.println 来做到。 这么做直观有效,但是有一系列的缺点:
1. 不知道这句话是在哪个类,哪个线程里出来的
2. 不知道什么时候前后两句输出间隔了多少时间
3. 无法关闭调试信息,一旦System.out.println多了之后,到处都是输出,增加定位自己需要信息的难度
我是这样理解的,在实际项目中,我们自己设计的程序出现并反馈信息,我们必须要快速定位到某个类或某个线程并去解决异常,修改错误
首先要使用log4j获取对象日志输出
要准备log4j的JAR包,并且要有一个log4j配置对象,和一个对象
在src目录下创建log4j配置文件
log4j.rootLogger=debug, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n%d%m
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=example.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=5
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
1. 输出在控制台,并且格式有所变化,如图所示,会显示是哪个类的哪一行输出的信息
2. 不仅仅在控制台有输出,在把日志输出到了 E:\project\log4j\example.log 这个位置
package log4j;
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyConfigurator;
public class TestLog4j{
static Logger logger = Logger.getLogger(TestLog4j.class);
public static void main(String[] args) throws InterruptedException {
PropertyConfigurator.configure( "f:\\Practice\\src\\log4j.xml" );
for (int i = 0; i < 5000; i++) {
logger.trace( "跟踪信息" );
logger.debug( "调试信息" );
logger.info( "输出信息" );
logger.warn( "警告信息" );
logger.error( "错误信息" );
logger.fatal( "致命信息" );
}
}

BasicConfigurator.configure();采用指定配置文件
PropertyConfigurator.configure("e:\\project\\log4j\\src\\log4j.properties");
Log4j的配置方式按照log4j.properties中的设置进行
设置日志输出的等级为debug,低于debug就不会输出了
设置日志输出到两种地方,分别叫做 stdout和 R
log4j.rootLogger=debug, stdout, R
第一个地方stdout, 输出到控制台
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
输出格式是 %5p [%t] (%F:%L) - %m%n, 格式解释在下个步骤讲解
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
第二个地方R, 以滚动的方式输出到文件,文件名是example.log,文件最大100k, 最多滚动5个文件
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=example.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=5
输出格式是 %p %t %c - %m%n, 格式解释在下个步骤讲解
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
代码比较
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | log4j.rootLogger=debug, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# Pattern to output the caller's file name and line number. log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=example.log log4j.appender.R.MaxFileSize=100KB log4j.appender.R.MaxBackupIndex=5
log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n |
log4j日志输出格式一览:
%c 输出日志信息所属的类的全名
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy-MM-dd HH:mm:ss },输出类似:2002-10-18- 22:10:28
%f 输出日志信息所属的类的类名
%l 输出日志事件的发生位置,即输出日志信息的语句处于它所在的类的第几行
%m 输出代码中指定的信息,如log(message)中的message
%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL。如果是调用debug()输出的,则为DEBUG,依此类推
%r 输出自应用启动到输出该日志信息所耗费的毫秒数
%t 输出产生该日志事件的线程名
所以:
%5p [%t] (%F:%L) - %m%n 就表示
宽度是5的优先等级 线程名称 (文件名:行号) - 信息 回车换行
与 Log4j入门 中的BasicConfigurator.configure();方式不同,采用指定配置文件
PropertyConfigurator.configure("e:\\project\\log4j\\src\\log4j.properties");
Log4j的配置方式按照log4j.properties中的设置进行
步骤 4 :
解释log4j.properties
设置日志输出的等级为debug,低于debug就不会输出了
设置日志输出到两种地方,分别叫做 stdout和 R
log4j.rootLogger=debug, stdout, R
第一个地方stdout, 输出到控制台
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
输出格式是 %5p [%t] (%F:%L) - %m%n, 格式解释在下个步骤讲解
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
第二个地方R, 以滚动的方式输出到文件,文件名是example.log,文件最大100k, 最多滚动5个文件
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=example.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=5
输出格式是 %p %t %c - %m%n, 格式解释在下个步骤讲解
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
代码比较
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | log4j.rootLogger=debug, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# Pattern to output the caller's file name and line number. log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=example.log log4j.appender.R.MaxFileSize=100KB log4j.appender.R.MaxBackupIndex=5
log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n |
步骤 5 :
格式解释
log4j日志输出格式一览:
%c 输出日志信息所属的类的全名
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy-MM-dd HH:mm:ss },输出类似:2002-10-18- 22:10:28
%f 输出日志信息所属的类的类名
%l 输出日志事件的发生位置,即输出日志信息的语句处于它所在的类的第几行
%m 输出代码中指定的信息,如log(message)中的message
%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL。如果是调用debug()输出的,则为DEBUG,依此类推
%r 输出自应用启动到输出该日志信息所耗费的毫秒数
%t 输出产生该日志事件的线程名
所以:
%5p [%t] (%F:%L) - %m%n 就表示
宽度是5的优先等级 线程名称 (文件名:行号) - 信息 回车换行

输出完之后,我尝试增加一下日志输出日期和时间,以及输出他信息所属的类全名。查看有得到有以下
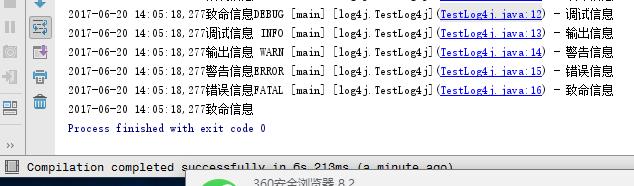
看到他的输出和平时报错,异常了一样,点击可以跳到类的指定行

明天计划:学习一下讲一个小课堂,拖了两天了。 然后尝试插入10W条数据,建索引对比不建索引查询的时间
遇到的问题:一开始遇到的是jar包没有正确导入导致报错。
今天的收获,学习了简单的log4j的使用。但是要配合自己具体使用还要日后自己多加练习
Java 2017.6.20
今天做的事情,就是准备小课堂所需要的索引搜索测试,由于很难看懂百度到的插入百万数据记录,只能选择一个会做的 建表,根绝JDBC连接数据库的方法, 用循环语句插入100W记录,但是自己电脑不好,而且这种很耗内存,导致只能插入50W条记录,而且数据有丢失不完整。
在库里建一个叫pw_tasklog的表,创建task_id,clientid,profileid,app_id,package_name,appkey,status,create_ip,point_amount,platform字段
import java.sql.*;
import java.util.Random;
public class TestSUOYING {
public static final String ALLCHAR = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
public static final Random random = new Random();
public static void main(String[] args) {
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://127.0.0.1:3306/db1";
String user = "root";
String password = "luozeying";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url, user, password);
if (!conn.isClosed()) {
System.out.println("connect to Mysql database successfully!");
}
conn.setAutoCommit(false);
String sql = "insert into pw_tasklog(task_id,clientid,profileid,app_id,package_name,appkey,status,create_ip,point_amount,platform) values(?,?,?,?,?,?,?,?,?,?)";
PreparedStatement pstmt = conn.prepareStatement(sql, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
for (int i = 0; i < 1e6; i++) {
pstmt.setString(1, generateString(42));
pstmt.setString(2, generateString(32));
pstmt.setString(3, generateString(32));
pstmt.setLong(4, random.nextInt(100));
pstmt.setString(5, generateString(20));
pstmt.setString(6, generateString(10));
pstmt.setInt(7, random.nextInt(2) + 1);
pstmt.setString(8, random.nextInt(255) + "." + random.nextInt(255) + "." + random.nextInt(255) + "." + random.nextInt(255));
pstmt.setInt(9, random.nextInt(30));
pstmt.setInt(10, random.nextInt(2));
pstmt.addBatch();
if (i % 100 == 0) {
pstmt.executeBatch();
conn.commit();
}
}
conn.commit();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
public static String generateString(int length) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < length; i++) {
sb.append(ALLCHAR.charAt(random.nextInt(ALLCHAR.length())));
}
return sb.toString();
}
}
由于用的是是最不效率的方法插入,因为其他的方法不懂java基础,所以也看不懂,只能通过jdbc连接数据库的方法去实现操作。然后插入数据及其的满,插了好几个小时都没插好100万调数据,而且这个方法也只是单纯的循环几条数据一致循环,没有一个自增长的ID给我查看,搞得测试的只能通过多种的条件查询才能查看到 测试数据,用其他方法太慢了。
明天计划的事情:明天再从头把DAO到mybatis在来一次,这一次要深度学习mybatis 了解基本功能,实现原理和有几种实现方法,等等。然后在去看看spring。接下来去整合他们。正确这一个星期里过完这些去整合spring和mybatis。
遇到的问题:
1.不知道用什么样的方法去插入百万条数据。想学习着用for循坏方法,但是看不懂,不懂得用
收获:今天终于插入了好几十万条了,但是由于机器跑不动,爆内存所以说不是很好的,第一次用别人的例子插入并用了查询语句去测试有索引和没有索引的区别。很好。又复习了一波简单的sql语句和学习用范围方法去查看数据。
select * from table1 limit 10; //查看table1 的表的前10行数据
reset query cache; // 清楚缓存
select app_id from table1 where app_id >10 and app_id < 20;// 在表1的 app_id字段里面找大于10小于20的值
insert into table2 select * from table1; //从1表把数据全部插入到2表里面
desc table1; //查看表的结构




评论