发表于: 2017-06-09 17:06:03
4 1335
完成的任务:
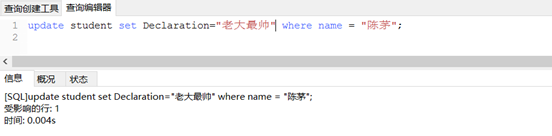
1. update 语句修改表中的数据, 宣言改为老大最帅,用SQL语句:
update student set Declaration=”老大最帅” where name = “陈茅”;

用Navicate 直接改动表格即可;
2. Navicate 可以转存为student.sql文件,增删改查之后,再运行之前的保存下的sql文件进行还原;

3. 建立name 索引,可以通过navicate 和 sql 语句建立。除了姓名以外,还可以给id建立索引(unique 索引)。


插入10条记录,分别在有索引和无索引的状态下进行语句查询:
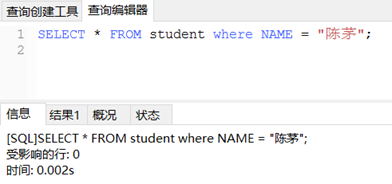
无索引时:

有索引时:
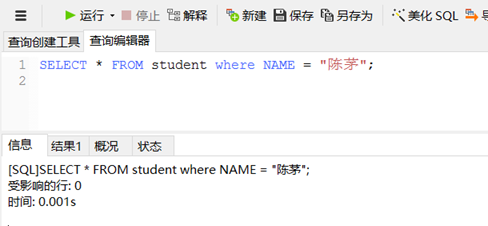

相差0.001s,差距不明显,可能数据量不够大,索引查询的优势不明显。
建立索引的时候,索引方法(btree、hesh)的选项不能理解什么意思,看了师兄的日报,说和数据结构有关系,以后要补一补数据结构和算法的知识。

4. 深度思考(查了一些资料,花费了很多时间,能够回答其中一部分问题,不知道是否妥当,但是后面有几个问题没有回答完,有时间继续)
A . MySQL相关问题深度思考
为何要用LONG类型替换DATE类型?
· 经过查资料,两种类型虽然所占字节不同,long(即double)对应的是8字节,date对应的是3字节,long所占的类型比date还要多,但是之所以用long 格式应该是因为通过数值比较效率很高。
· 在数据仓库系统里,如果用datetime这种日期格式,为了进一步简化计算,往往也把date和time分开,都用int型来表示。
B. 自增ID有何坏处?哪些场景不用自增ID?
· 自增ID的目的是唯一识别每一条记录,可方便用于查询,修改,删除,不用程序维护,比较方便;
· 坏处:1. 不存在连续性,如果删除其中一条数据,ID不会自动更新;
2. 数据重复之后也不会提示和处理;
3.数据导入导出、数据库迁移的时候,ID不唯一,易出错;
解决办法: 使用uuid在数据库移植、多表所数据库分布式存储时较为方便
(暂时不理解,后续学习)
C. 数据分页
使用数据分页的原因——因为很多时候数据不可能完全显示,需要进行分页显示;
Mysql是使用关键字LIMIT来实现的。Limit offset,size表示从多少索引去多少位,
D.什么是索引,多大数据量下建索引有性能的差别,什么情况下该对字段建索引?
索引用于快速找出再某一列中有一个特定值的行,如果没有索引,mysql会从头开始读完整个表,直到找出数据记录。表越大,查询的时间越慢。如果有查询的列有一个索引,就能快速到达文件的位置去进行查询,不必读完整个数据。
(1)索引并非越多越好,一个表中如有大量的索引,不仅占用磁盘空间,而且会影响语句的性能,因为当表中的数据更改的同时,索引也会进行调整和更新。
(2)避免对经常更新的表进行过多的索引,并且索引的列尽可能的少。
(3)数据量小的表最好不要使用索引,
(4)在条件表达式中经常用到的不同值较多的列上建立索引,不同值较少的列不要建立索引,比如“性别”的列;
(5)当某列数据唯一时,指定唯一索引
(6)频繁进行排序或分组的列(group by, order by)上建立索引。
E.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
普通索引是 MySQL 中的基本索引类型,允许在定义索引的列中插入重复值和空值。
唯一索引,索引列的值必须唯一,但允许有空值。
如果是组合索引,则列值的组合必须唯一,主键索引是一种特殊的唯一索引,不允许有空值。
F. 如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
需要。否则会报错
后续任务:安装JDK,maven,补充知识。




评论