发表于: 2017-06-03 19:01:11
2 1149
写在步骤前,mysql的一些基本语句:
show databases; 查看有多少数据库
use 库名: 进入数据库
creat database 库名; 创建库
drop database 库名; 删除库
show columns in 表名; 查看表结构
describe 表名; 查看表结构
creat table 库名 表名<属性 类型>; 创建表
rename table 原名 to 新名; 表重命名
alter table 原名 rename 新名; 表重命名
drop table 表名; 删除表
alter table 表名 add(或change,rename,drop) 列名 要改的属性; 更该表结构
例 alter table test_double add column address varchar(20) notnull;
insert into 表名(列名,列名)values(属性名,属性名);
update 表名 set 列名=" " where id= ; 更新表内容
select * from 表名; 查看表内容
delete from 表名 where id= ; 产出表中的列
alter table 表名 add index(列名); 给某一列建立索引
select* from 表名 where 列名= ; 用列名查找
source 路径\XXXX.sql 恢复数据
今日完成的事:
步骤6:从报名帖插入最近一条报名 并根据姓名查找


步骤7:用navicat和mysql 改宣言


步骤8:导出sql文件,并使用navicat和mysql删除此记录 用之前的备份恢复


navicat右键表名 选择转出sql文件 结构和数据 (这里并不能用导出向导,用了之后导入不进去,我又重新写了一遍表结构..) 接下来成功恢复内容
步骤9:给姓名建立索引 思考下还应该给哪些数据建立索引

可能是数据太少 这建立索引感觉丝毫没用啊 索引类似于图书目录 给某个属性建立索引 这个属性应该具有独一性 个人认为 可以给姓名 线上ID 和QQ建立索引 但是QQ感觉没啥大必要
步骤10:插入十条数据 查看有无索引对sql语句执行效率的区别
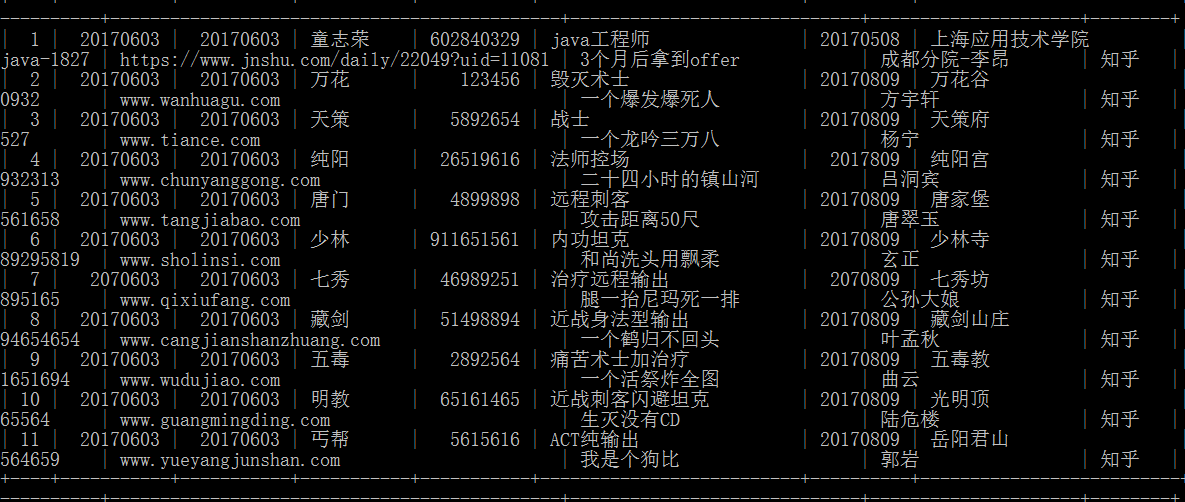
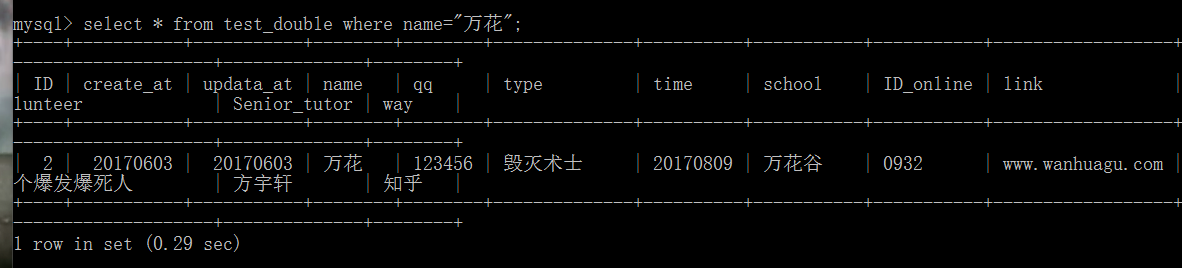
讲道理,并没有发现有啥区别 感觉应该是数据太少看不出差别 也不大懂什么叫执行语句的效率 个人理解是在这么多数据里 查询数据的效率 总之感觉就是数据太少 看不出来
步骤10:深度思考
1:为什么要用long类型代替datetime:
查网页资料貌似有个时间戳的概念,datetime敲在mysql貌似使用格林威治的北京时间到创建时候的秒数 好像是不能准确地表达出时间,还有就是一个时区问题(实在是看不懂概念,只能个人理解到这)
2:自增ID有什么坏处 什么情况下不使用自增ID
自增ID貌似不会理会中间被删除的数据 例如1,2,3,4 第三条删除后 由于是自增ID ID4并不会进位到3 是数据不具有连续性
可能当ID 是唯一主键的时候 或者索引是ID的时候 应该不会用自增ID 因为修改数据后不能连续 所以查数据的时候会很麻烦.
3:什么是DB的索引 多大的数据量建索引会有性能差别的 什么情况下对该字段建索引
DB索引可以通过指定的条件快速查找想要找的数据, 多大数据量没啥概念 通过插入十条数据内个任务 耗时0.29秒 估计万条左右的数据会有性能差别.
遇到的问题:
最主要的问题是:最开始插入数据的时候 怎么着也插不进去 卡了我一天多的时间 就差拜雍正了 后来问朋友 当属性为notnull的时候 而没有插入数据 会出现语法错误 别的数据 也插不进去 本来按照mysql的错误提示复制粘贴着查原因 找不到具体原因 或者自己完全看不懂 而朋友直接在百度搜mysql插入数据失败 直接找到了原因..... 严重的说明了! 自己搜索筛选有用信息的能力及其的差劲!!!!!!
然后就是插入数据 语法已经搜出来 然后也插入失败了好多次 其实都是语法错误 后来手动插入十条数据 就好多了 都是一次成功 熟能生巧 而且()""这些富豪都是成对出现 要打一定要先打出一对 然后再在里面写数据 教训:一定要养成良好的书写习惯.
明天的计划:
并不知道下面任务的难度,尽量多完成吧,最重要的理解,而不是为了完成任务去做




评论