发表于: 2017-05-27 08:16:50
9 1314
今日完成
不知道为什么提交第一个任务后还不能做第二个任务,继续写日报反思前这个任务
1: 如果不关闭连接池循环开1000个连接的结果
我开到第247个连接的时候就出错了,出现NoConnection Exception。 错误信息显示说,Data Source 拒绝建立新的connection。
2:测试一下连接DB中断后TryCatch是否能正常处理。
因为使用了try catch,无法连接数据库的时候使用select 返回值null
3: 数据库插入速度太慢,
我在做插入100w 记录时发现每秒大概400行record。而且越来越慢。我尝试插入了1000w条,用去了43分钟。
把除了PK的index都取消后继续插入,速度还是400每秒,但是不会比较明显的越来越慢。看了下workbench 上面乱七八糟的,我把performance 记录关掉了,没什么变化。发现workbench里面显示一共5个connection最多。
解决:
没找到如何设置connection的最大数,就选择了在spring datasource上配置了C3P0。 很简单,Maven引入jar包,Spring context xml文件里配了下datasource,直接就可以使用了,我设置了最大连接20个,插入速度瞬间升到每秒2000以上(目测)。 这部分应该肯定还可以优化,但不算事眼下的重点了。
4: 在100w条数据中测试selectByRealname的速度
我的Realname用的是UUID ,每个Realname都是又臭又长的好似ea3aa818-7a43-4001-941e-13c3b94ebe14。我选择去找第100w条数据。循环找100次。
(InnoDB Engine)
Realname无索引状态下用时: 58秒+
Realname有索引状态下用时: 59秒+
改为MyISAM engine 有索引: 21秒+
和预期的不一样,以为有索引状态下InnoDB的select by realname速度会高呢。也许和我的数据都是unique的 UUID有关吧?
5: 插入3000W条数据
据百度说,InnoDB插入速度快,我把数据库换回InnoDB + 无索引,再来插入2900W条数据看看,连接处设置为最大200个。目测每秒4000条的插入,看workbench,链接数量是7个,估计设置200个连接也是浪费了,最大连接200应该是没啥用。下次设少点看看。
(吃早饭去鸟,回来看我的3000W条数据)
吃完饭回来插了1400w条,还是有点慢,baidu了一下,直接用INSERT INTO table (列名不包含id)(SELECT 列名不包含id FROM table; 这语句直接考本。用了一下链接30秒后断。应该是1400w条有点多。限制了下,一次拷贝100w条,用了28秒。比java快。。。一顿胡乱搞,终于3000W条了。。。
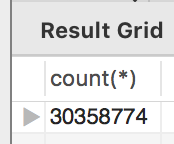
用sql还是比用java 循环插快。
6:比较3000条下select的速度差
执行: SELECT enroll_id FROM enroll.enroll where enroll.realname='6b4ad9aa-9c79-4c59-87cf-f70b3648e78e';
InnoDB情况下
不加index到realname,搜索一次用了9秒多

加了index到realname之后

第一次用了27秒,第二次10秒,和以前的测试的结果相仿,不知道为什么有了index也没快,是不是因为我用UUID每个都是unique的原因
改成MYISAM引擎试试:
realname有index: 19秒

去掉index之后,7秒多。。

小结:
想起某位师兄说:不要给string 加 index,估计就是这个意思了。不能给加index。
没想通为什么realname 无index 比有index快。




评论