发表于: 2017-05-16 14:23:01
4 1391
今日计划
重新构造数据库
对照任务一验收标准检查
完成剩下的深度思考
写任务总结
今日完成
插入1000万条数据
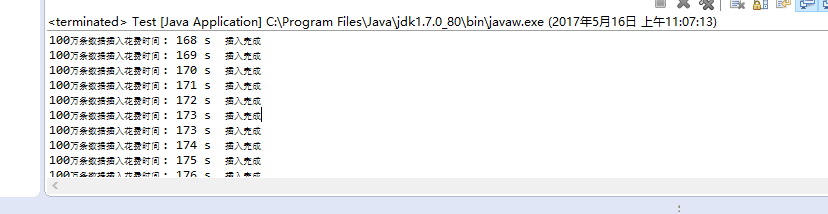
生成速度慢了一倍以上
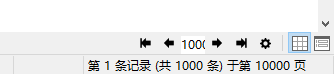
数据确实是1000w条
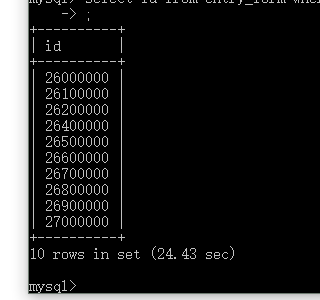
不添加索引的搜索结果
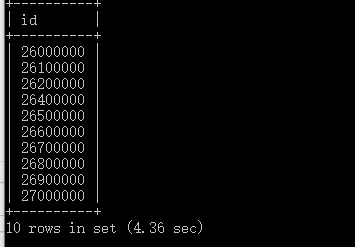
添加索引到name搜索的结果。与昨日结果差别较大,猜测应该是设置了主键的原因,提高了数据库执行效率。
sql语句是select id from entry_form where name=1000000
尝试插入1亿条数据,10线程,每线程1000万条数据,提示内存溢出
set global max_allowed_packet = 100*1024*1024
修改max_allowed_packet为10m,重新执行代码,机器卡死,只能重启
用蠢办法一步步添加吧,机器内存和cpu差了一截。cpu利用率在40%~50%波动。老机器还是不行,尝试用台式机插入一亿条数据。
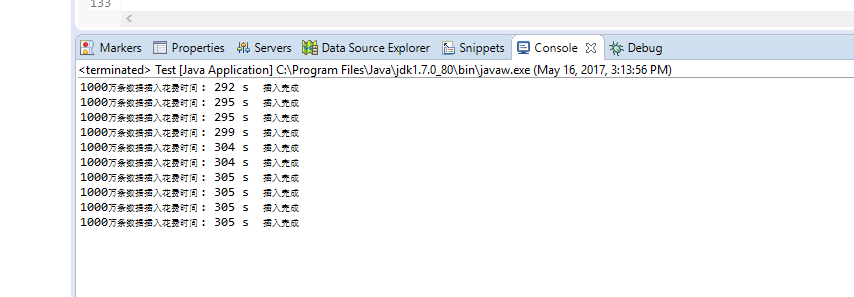
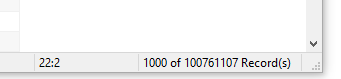
1亿+数据
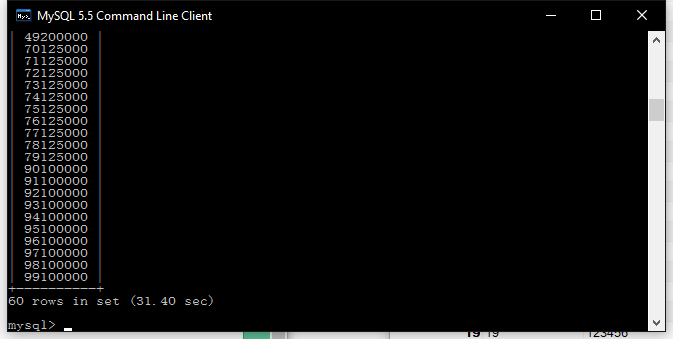
加入索引
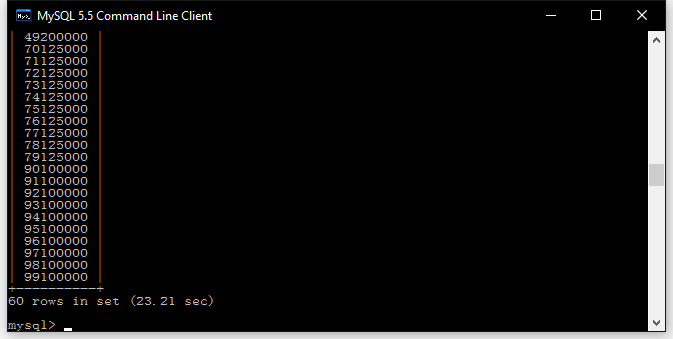
搜索时间明显缩短,可以确定昨天加索引后搜索效率无明显提升的原因是主键缺失了
删除索引,再插1亿条
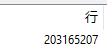
2亿+行数据
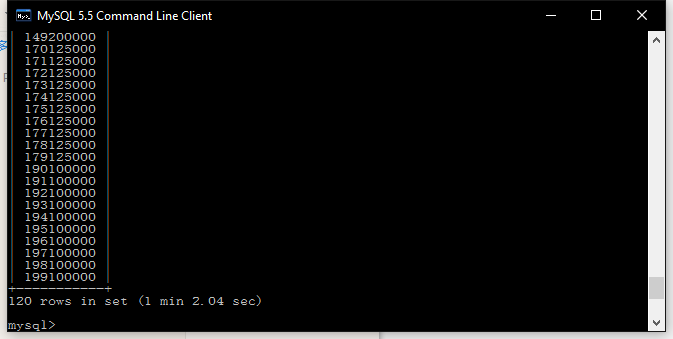
到1分钟啦,现在试试加入索引
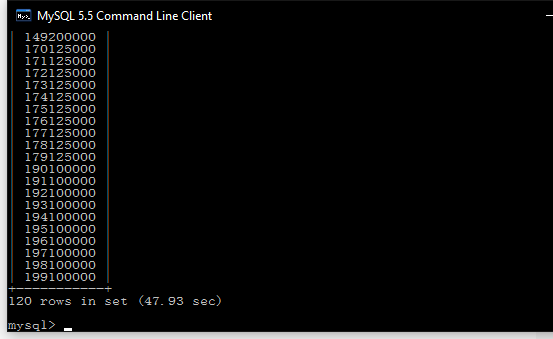
优势很明显
通过杨舜师兄的日报,找到一个nb方法检索。200线程并发同时查询数据库表及索引优化
package insert;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class ThreadToMysql extends Thread {
public String name;
public String qq;
public ThreadToMysql(String name, String qq) {//构造函数传入要查询姓名和qq
this.name=name;
this.qq=qq;
}
public void run() {
String url = "jdbc:mysql://127.0.0.1/student";
String name = "com.mysql.jdbc.Driver";
String user = "root";
String password = "198712";
Connection conn = null;
try {
Class.forName(name);
conn = DriverManager.getConnection(url, user, password);//获取连接
conn.setAutoCommit(false);//关闭自动提交,不然conn.commit()运行到这句会报错
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
if (conn!=null) {
Long startTime=System.currentTimeMillis();//开始时间
String sql="select id from entry_form where name='"+name+"' and qq='"+qq+"'";//SQL语句
String id=null;
try {
Statement stmt=conn.createStatement();
ResultSet rs=stmt.executeQuery(sql);//获取结果集
if (rs.next()) {
id=rs.getString("id");
}
conn.commit();
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
Long end=System.currentTimeMillis();
System.out.println(currentThread().getName()+" 查询结果:"+id+" 开始时间:"+startTime+" 结束时间:"+end+" 用时:"+(end-startTime)+"ms");
} else {
System.out.println(currentThread().getName()+"数据库连接失败:");
}
}
}
package insert;
public class TestThreadToMysql {
public static void main(String[] args) {
for (int i = 1; i <=200; i++) {
String name=String.valueOf(i);
new ThreadToMysql(name, "123456").start();
}
}
}
参考杨舜师兄的办法,name栏位的值改为唯一值。
通过插入UUID实现
package insert;
import java.sql.SQLException;
import java.util.UUID;
public class ThreadToMysql {
public static void main(String[] args) throws SQLException {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
java.sql.Connection conn = java.sql.DriverManager.getConnection("jdbc:mysql://localhost/student", "root", "198712");
java.sql.Statement stmt = conn.createStatement();
int total = 25000;
System.out.println("====start=====");
long start = System.currentTimeMillis();
// 测试插入数据库的功能:
for (int n = 0; n <8000; n++) {
StringBuffer sBuffer = new StringBuffer(" insert into entry_form(name) values ");
for (int i = 0; i < total; i++) {
String name = UUID.randomUUID().toString();
if (i == total - 1) {
sBuffer.append("('" + name + "');");
} else {
sBuffer.append("('" + name + "'),");
}
}
System.out.println("第" + n + "次插入2.5万条数据!");
stmt.executeUpdate(sBuffer.toString());
}
long end = System.currentTimeMillis();
System.out.println("run time:" + (end - start)/1000+"秒");
stmt.close();
conn.close();
}
}
插入2亿条数据


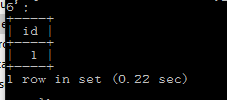
对比有无索引select语句效率,质的区别
验收标准
1.DB的设计和命名符号规范
字母大小写等,参考草船云,列出来
2.除了CRUD的基本单元测试,加上根据学员名字,学号去查找报名贴的单元测试
CRUD已经实现,后面的根据学员名字和学号查找报名贴单元测试还没做
3.Java代码符合命名规范
参考草船云,列出来
4.Interface和ServiceImpl分开
任务要求,没问题
5.分别使用Mybatis的配置文件和Annotation方式去配置数据库
mybatis配置数据库没问题,注解法没在jdbc中做
6.使得Log4j来记录日志
maven项目依赖添加log4j模块,pomxml实现。
7.通过远程连接Mysql,使用自定义域名并通过配置本地Host来配置DB连接文件
云服务器mysql配置和数据库导入已完成,自定义域名还没研究
8.添加数据返回ID,删除或更新数据返回True/False
远程数据库操作?这里没有做
9.访问数据的时候使用Try/Catch捕获异常,关闭DB之后测试异常代码可以正确执行
任务要求,已实现
10.关闭连接
trycatch resource功能,自动关闭
困难
随机数据插入的问题,已经找杨舜师兄解决
收获
索引对大规模数据库效率提升
索引选取栏位唯一性高时,数据库操作效率更是质的飞跃
对比师兄代码,自己trycatch异常处理和链接关闭喜欢遗忘
明日计划
对照审核标准,完成遗漏部分
深度思考未完成部分




评论