发表于: 2017-05-15 14:58:30
3 1380
今日计划
war包部署到云服务器tomcat上
访问服务器地址/项目名称 显示jsp页面
学习连接池
完成任务一
今日完成
eclipse输出war包
上传war包到tomcat webapp下
配置tomcat conf文件夹下context.xml jsp页面显示
连接池概念及1000个循环语句
当有多个线程,每个线程都需要连接数据库执行SQL语句的话,那么每个线程都会创建一个连接,并且在使用完毕后,关闭连接。
创建连接和关闭连接的过程也是比较消耗时间的,当多线程并发的时候,系统就会变得很卡顿。
同时,一个数据库同时支持的连接总数也是有限的,如果多线程并发量很大,那么数据库连接的总数就会被消耗光,后续线程发起的数据库连接就会失败。
数据库连接池原理-使用池
与传统方式不同,连接池在使用之前,就会创建好一定数量的连接。
如果有任何线程需要使用连接,那么就从连接池里面借用,而不是自己重新创建.
使用完毕后,又把这个连接归还给连接池供下一次或者其他线程使用。
倘若发生多线程并发情况,连接池里的连接被借用光了,那么其他线程就会临时等待,直到有连接被归还回来,再继续使用。
整个过程,这些连接都不会被关闭,而是不断的被循环使用,从而节约了启动和关闭连接的时间。
ConnectionPool构造方法和初始化
1. ConnectionPool() 构造方法约定了这个连接池一共有多少连接
2. 在init() 初始化方法中,创建了size条连接。 注意,这里不能使用try-with-resource这种自动关闭连接的方式,因为连接恰恰需要保持不关闭状态,供后续循环使用
3. getConnection, 判断是否为空,如果是空的就wait等待,否则就借用一条连接出去
4. returnConnection, 在使用完毕后,归还这个连接到连接池,并且在归还完毕后,调用notifyAll,通知那些等待的线程,有新的连接可以借用了。
package jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class ConnectionPool {
List<Connection> cs = new ArrayList<Connection>();
int size;
public ConnectionPool(int size) {
this.size = size;
init();
}
public void init() {
try {
Class.forName("com.mysql.jdbc.Driver");
for (int i = 0; i < size; i++) {
Connection c = DriverManager
.getConnection("jdbc:mysql://127.0.0.1:3306/student?characterEncoding=UTF-8", "root", "admin");
cs.add(c);
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public synchronized Connection getConnection() {
while (cs.isEmpty()) {
try {
this.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Connection c = cs.remove(0);
return c;
}
public synchronized void returnConnection(Connection c) {
cs.add(c);
this.notifyAll();
}
}
测试类
初始化一个有3条连接的数据库连接池
然后创建1000个线程,每个线程都会从连接池中借用连接,并且在借用之后,归还连接。拿到连接之后,执行一个耗时1秒的SQL语句。
package jdbc;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import jdbc.ConnectionPool;
public class TestConnectionPool {
public static void main(String[] args) {
ConnectionPool cp = new ConnectionPool(3);
for (int i = 0; i < 1000; i++) {
new WorkingThread("working thread" + i, cp).start();
}
}
}
class WorkingThread extends Thread {
private ConnectionPool cp;
public WorkingThread(String name, ConnectionPool cp) {
super(name);
this.cp = cp;
}
public void run() {
Connection c = cp.getConnection();
System.out.println(this.getName()+ ":\t 获取了一根连接,并开始工作" );
try (Statement st = c.createStatement()){
//模拟时耗1秒的数据库SQL语句
Thread.sleep(1000);
st.execute("select * from entry_form");
} catch (SQLException | InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
cp.returnConnection(c);
}
}
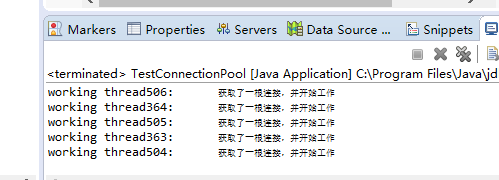
因为设定了初始连接数上限,且无空余连接时等待,直到有新的连接可以借用,运行正常。
无卡顿,资源利用正常,没有异常产生。
中断db TryCatch能否正常处理
修改连接为云服务器地址,连接使用云服务器mysql数据库
运行状况和连接本地db一样。
关闭云服务器,再次尝试。
com.mysql.jdbc.CommunicationsException: Communications link failure due to underlying exception:
** BEGIN NESTED EXCEPTION **
java.net.ConnectException
MESSAGE: Connection timed out: connect
STACKTRACE:
连接异常
TryCatch能正常处理
关闭连接
try-with-resource的方式自动关闭连接,因为Connection和Statement都实现了AutoClosable接口
举例
package jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class TestJDBC {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
try (
Connection c = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/how2java?characterEncoding=UTF-8",
"root", "admin");
Statement s = c.createStatement();
)
{
String sql = "insert into entry_form values()";
s.execute(sql);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
检查代码规范,检查DB表格
数据库插入100万条数据,对比建索引和不建索引效率差别
网上找到的办法,十个线程同时插入。小笔记本电脑怕搞不定,回家拿台机试。
首先准备数据库studet
数据库建表entry_form
插入表头id name qq profession
实体类
package tenThreadInsert;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Date;
public class MyThread extends Thread{
public void run() {
String url = "jdbc:mysql://127.0.0.1/student";
String name = "com.mysql.jdbc.Driver";
String user = "root";
String password = "198712";
Connection conn = null;
try {
Class.forName(name);
conn = DriverManager.getConnection(url, user, password);//获取连接
conn.setAutoCommit(false);//关闭自动提交,不然conn.commit()运行到这句会报错
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
// 开始时间
Long begin = new Date().getTime();
// sql前缀
String prefix = "INSERT INTO entry_form (name,qq,profession) VALUES ";
try {
// 保存sql后缀
StringBuffer suffix = new StringBuffer();
// 设置事务为非自动提交
conn.setAutoCommit(false);
// 比起st,pst会更好些
PreparedStatement pst = (PreparedStatement) conn.prepareStatement("");//准备执行语句
// 外层循环,总提交事务次数
for (int i = 1; i <= 10; i++) {
suffix = new StringBuffer();
// 第j次提交步长
for (int j = 1; j <= 100000; j++) {
// 构建SQL后缀
suffix.append("('" +i*j+"','123456'"+ ",'java'"+"),");
}
// 构建完整SQL
String sql = prefix + suffix.substring(0, suffix.length() - 1);
// 添加执行SQL
pst.addBatch(sql);
// 执行操作
pst.executeBatch();
// 提交事务
conn.commit();
// 清空上一次添加的数据
suffix = new StringBuffer();
}
// 头等连接
pst.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
// 结束时间
Long end = new Date().getTime();
// 耗时
System.out.println("100万条数据插入花费时间 : " + (end - begin) / 1000 + " s"+" 插入完成");
}
}
测试类
package tenThreadInsert;
public class Test {
public static void main(String[] args) {
for (int i = 1; i <=10; i++) {
new MyThread().start();
}
}
}
先上不加索引的
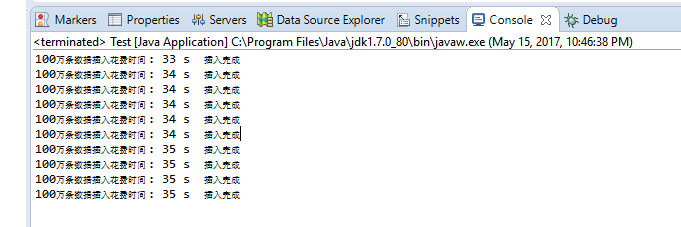
合计1000万条数据
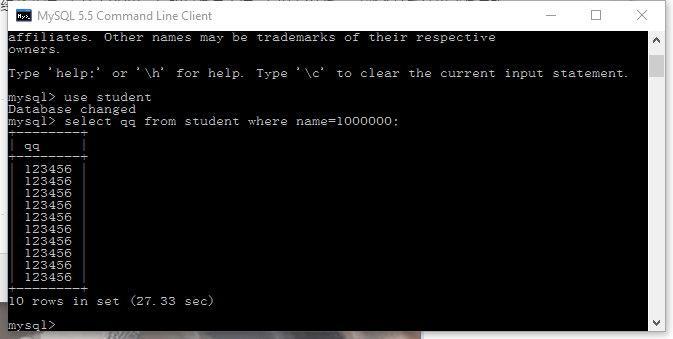
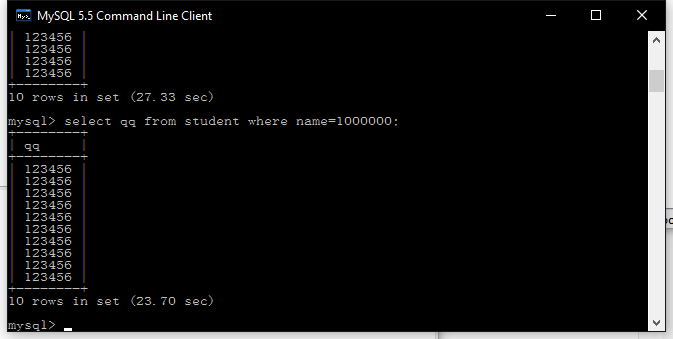
添加索引后少了4秒,对比网上其他测试结果,有极大出入,正常来说加索引后查询速度应该是毫秒级,可能是缓存问题。
修改单线程添加数目为1000万,即总计1亿条数据,cpu占用率30%+
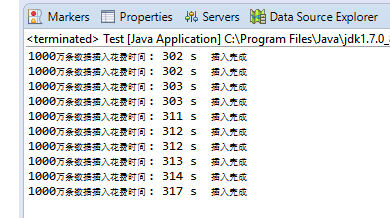
一首歌的时间
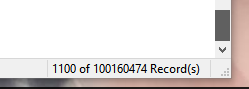
1亿+数据量
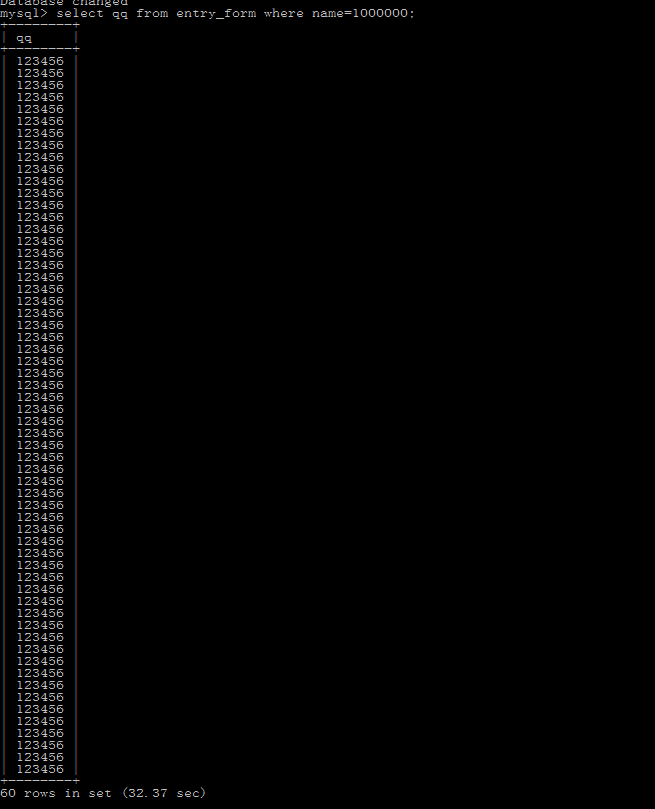
加索引
用navicat加索引很漫长

查询时间还是不对,居然要32.82秒
navicat查看,之前添加索引卡死取消的索引出现了,删除多余索引,再次尝试
结果依然不理想,难道是唯一键的问题?
对比网上页面,猜测应该是由于name值不唯一,降低了查找效率,即使添加索引也没有多大改善。
明天重新构造查询测试项目
对比下任务审核要求,深入思考还没做完。也遗漏了一些点,明天补齐。
困难
不知道其他师兄有没有高效的插入大量数据的办法,数量级上千万后,用navicat或者Mysql-front查看数据经常卡死。
收获
体会到了索引对大规模数据库效率的提升
学会了云端服务器部署项目
理解了数据池的概念
明日计划
重构千万级数据表
完成深度思考剩下内容
一条条对照验收标准检查
好好写任务总结




评论