发表于: 2017-05-13 17:55:14
1 1068
今日完成的事:
1,测试一下不关闭连接池的时候,在Main函数里写1000个循环调用会出现什么情况。
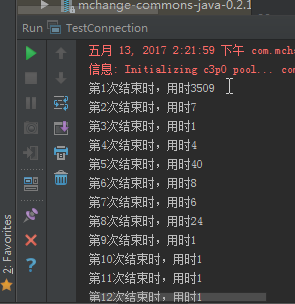
就已开始用时多点,后面就基本在1ms以下了。
2,数据库里插入100万条数据,对比建索引和不建索引的效率查别。再插入3000万条数据,然后是2亿条,别说话,用心去感受数据库的性能。
a.给数据库插入了100万的数据,用时50min。
b.在没建索引的情况下,通过姓名查询,用时15s 389ms。
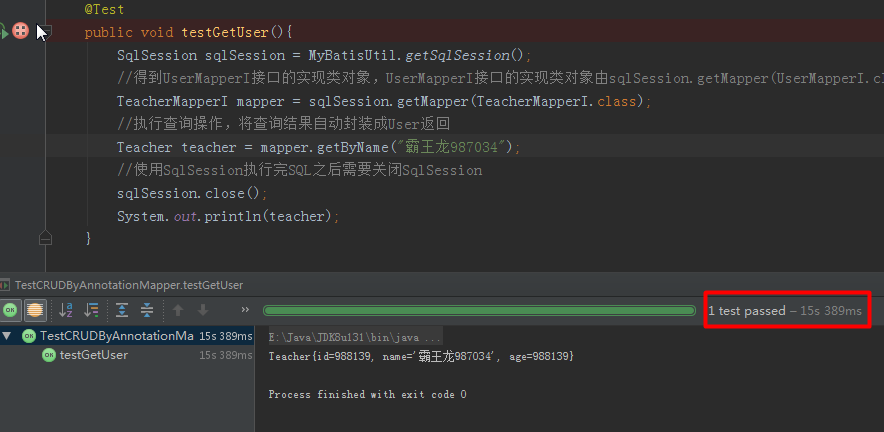
c.给name建立索引,用时9s多,还是很震惊的,再想到100万多的数据,就能释然了。
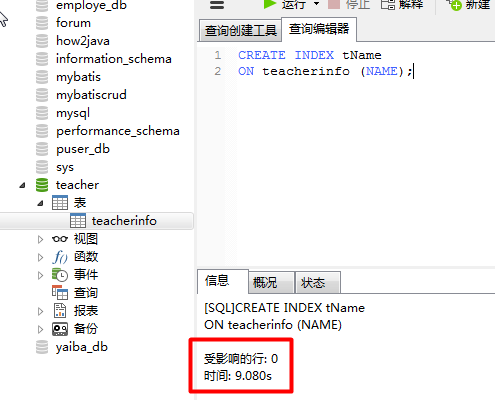
d.通过索引查询,用时1s 756ms。
明日计划:
任务一跌跌撞撞地做完了,许多东西还是需要加强,因此明日不准备先做任务二,先把任务一梳理回顾一遍,把深度思考写下来。周一开始再做任务二。
遇到问题:
前面在学数据库的时候,对索引只是大概了解了一下,也没太在意,对索引的理解:
一个数据库表中有许多字段,所以得建立相当于在查询时不用遍历字段,知己可以找到所需字段(比如name)--这是错误的。
今天在查询100万多的数据时,如果按上面的理解,表中只有两个字段(name,age),加不加索引页不至于相差8s这么久,这才引起重视,发现索引的是用一种叫做 “B-树“的方法。简单理解就是:要查询1~100中的87,没索引时,数据库就老老实实地从1查到100,然后找到是87的数据。加了索引却是将1~100分为a:1~50【子节点:1~25、26~50】、b:51~100【51~75、76~100】两个一级节点,四个二级节点(举例,也可以有别的分法),然后87>50,所以去b节点找,然后指向76~100。(举例只为说明,原理与例子有区别,只是为了帮助理解。)
总结:加索引之所以能节省查询时间,是因为索引的存在将无效数据进行了有效隔离,从而避免了遍历的情况。




评论