发表于: 2017-04-23 22:53:10
8 2274
Task1的第二天
今日计划
- 1. 完成昨天未完成的Q8~11
- 2. 今天有点别的事,完成到Q16吧
今日完成
Q8:MySQL数据的导出与导入
MySQL的数据导入与导出主要依靠SELECT ... INTO OUTFILE和LOAD DATA INFILE ... INTO TABLE来完成。
此外,MySQL还提供了mysqldump用于转存储数据库。它主要产生一个SQL脚本,其中包含从头重新创建数据库所必需的命令CREATE TABLE INSERT等。
导出表
我们来看看如何完成最基本的表导出:
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u root -p jnshu entry_form > sql/entry_form.sql打开生成的entry_form.sql,可以看到sql文件中有删除表然后创建表的逻辑。如果我们的表已经存在且不想重新创建表,该怎么办呢?这种情况就要使用--no-create-info参数,表示不生成建表语句。
这时的命令如下:
mysqldump -u root -p --no-create-info --skip-triggers jnshu entry_form > sql/no_create_info_entry_form.sql--skip-triggers是用来屏蔽触发器的,如果你之前和我一样创建了触发器,这里可能需要屏蔽一下。
导入表
基本的表导入:
mysql -h localhost -u root -p jnshu < sql\no_create_info_entry_form.sql删除数据前:


导入数据后:


Q9:建立索引
日报里只写了MySQL中建立索引的步骤和语法,关于索引的概念,我放在了我的简书中。链接:MySQL中的索引——概念篇(简书)
添加索引的SQL语句:
创建索引的方式:
CREATE INDEX indexName ON mytable(field(length));
我的sql:
CREATE INDEX name ON entry_form(name(3));length用于索引的部分的长度,比如字符串的前三个字符用于索引,后面的不进行索引。如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
修改表结构的方式:
ALTER TABLE table)name ADD INDEX indexName (field);我的sql:
ALTER TABLE `entry_form` ADD INDEX `name` (`name`);在navicat中:

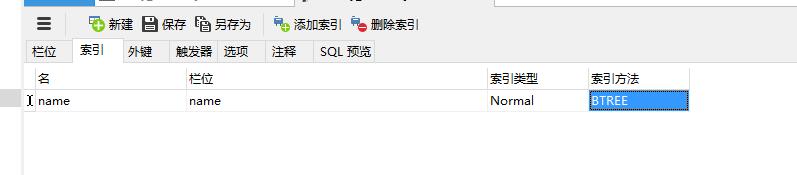
Q10:插入数据,测试索引对查询效率的影响
修改数据如下:

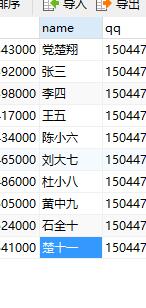
不使用索引查询:select * from entry_form where name='陈小六';
用时:1 row in set (0.02 sec)
使用索引查询:select SQL_NO_CACHE * from entry_form where name='陈小六';,记得不要使用缓存。
用时:1 row in set (0.00 sec)
从用时上来看,虽然很小,但是明显查询速度提高了。
Q11:回答深度思考
深度思考5:为什么DB的设计中要使用Long来替换掉Date类型?
为了数据格式的统一?百度也没百度到,可能是我姿势不对?另外比较好奇,为什么不用TIMESTAMP。
深度思考6:自增ID有什么坏处?什么样的场景下不使用自增ID?
自增id的缺点:
- 1. 当数据其他部分对自增ID有依赖时,在迁移数据库时就会出现问题;
- 2. 另外,还百度到在分布式下好像也会出现问题;
- 3. 还有自己在使用的时候,删除一条记录,然后再插入同样一条记录,id会自动递增,有点别扭。
不适合使用自增ID的场景:
- 1. 根据ID自增的特性,感觉会频繁删除记录的情况下不适合,这时候ID可能已经自增到100000了,而实际记录只有10条。
- 2. 看网友的说法,好像瞬间有大量数据插入,或者频繁插入的时候不适合,会影响性能什么的。
深度思考7:什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
什么是DB的索引:在Q9中解释过了。
多大数据量下建立索引会有性能差别:看网友说,应该在10w以上的时候,性能会有比较大的差别,这个还没试过,我看任务要求28有要求试验大数据量下的索引,这个问题放在28做完后再答吧。
深度思考8:唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
唯一索引和普通索引的区别:唯一索引较普通索引添加了唯一性约束,即添加索引的列的值不允许重复。
什么时候需要建唯一索引:需要建立唯一性约束时。
深度思考9:如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
需要判断,如果不判断进行插入的话,重复的时候会抛出异常。
深度思考10:CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
create_at应该在记录插入的时候赋值,update_at应该在插入和更新的时候赋值。
这两个字段我认为应该对外开放查询接口,关闭更新接口。
深度思考11:修真类型应该是直接存储Varchar,还是应该存储int?
看需求了,如果修真类型不是以选项的形式给出(比如报名帖中都是自己打的字),用varchar,灵活。如果给出明确选项,用int好一点,有利于查询。但是,为什么不用enum呢?
深度思考12:varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
varchar类型的长度怎么确定:有明确需求,且不会变更的情况下,按照存储的最长长度来设置;对输入的值不确定的情况下,确定大致范围,并多保留一定的空间;varchar的长度还可以用来规范数据的合法性。
Text和LongText的区别:存储长度的区别,TEXT,0-65535字节,LONGTEXT,0-4294967295字节(4GB)
深度思考13:怎么进行分页数据的查询,如何判断是否有下一页?
一般的分页查询:select * from table limit start, count,start是开始的偏移量,count是获取记录的条数。
判断下一页:使用select COUNT(*) from table获得数据表的总数,然后通过计算就可以得到是否有下一页了。
深度思考14:为什么不可以用Select * from table?
从网上看的:会影响效率。
自己想的:表结构的改变可能会引起Java代码的崩溃,比如列的顺序变了。
Q13:下载并安装Maven
这个完成并写了一篇文章,文章放在日报里感觉不合适,发表在我的简书里了。链接:Maven的安装及配置(简书)
Q14:在IDEA中配置外部Maven
这个就不写了,已经配好。
Q15~Q16:Maven项目的创建、编译、测试、打包和安装
同样写了一篇文章放在简书里了,链接:第一个Maven项目(简书)
明日计划
明天要上班,还有别的事,进度会慢点,计划推到任务要求21吧。
问题总结
明天要上班,提交不了日报,来不及总结问题了,先提交日报了。




评论