发表于: 2017-04-07 17:00:16
1 1295
今天完成的事情:
8.将表导出成Sql文件,并使用navciat和Sql分别尝试删除此条数据,并用之前备份的Sql恢复。
9.给姓名建索引,思考一下还应该给哪些数据建索引
10.插入10条数据,查看有索引和无索引的情况下,Sql语句执行的效率
8.中,前一天已经完成前半部分。今天完成sql的恢复,语句如下
LOAD DATA LOCAL INFILE 'D:/jnshu/task01/task01.txt' INTO TABLE task01_student_info
执行后成功导入数据
9.姓名建立索引的语句入下
CREATE INDEX stu_name ON task01_student_info(student_name(5));
CREATE INDEX ol_id ON task01_student_info(online_id(5));
另外为线上id设置了索引,理论上讲id类的属性都应该加索引方便查找,下面的语句实现了查询表中的索引。
SHOW INDEX FROM task01_student_info;
10.为了测试索引的效率,需要使用存储过程创建数据
创建数据存储过程如下:
DROP PROCEDURE IF EXISTS proc1;
DELIMITER $$
SET AUTOCOMMIT = 0$$
CREATE PROCEDURE proc1()
BEGIN
DECLARE v_cnt DECIMAL (5) DEFAULT 0 ;
DECLARE v_id CHAR (10) DEFAULT 1 ;
dd:LOOP
SET v_id = LEFT(UUID(),10);
INSERT INTO task01_student_info (student_id,create_at,update_at,student_name,student_type,online_id)
VALUES (NULL,UNIX_TIMESTAMP(NOW()),UNIX_TIMESTAMP(NOW()),v_id,'java',v_cnt);
COMMIT;
SET v_cnt = v_cnt+1 ;
IF v_cnt = 1000 THEN LEAVE dd;
END IF;
END LOOP dd ;
END;$$
DELIMITER ;
在query窗口中使用CALL proc1();调用存储过程就实现了测试数据的创建。
mysql中使用profiles实现语句执行时间的分析,下面语句中,第一条实现查看profiles的相关属性,第二句实现开启profiles,三四句实现多条与单条的profile(s) 查询
SHOW VARIABLES LIKE "%pro%";
SET profiling = 1;
SHOW profiles;
SHOW profile FOR QUERY 6147;

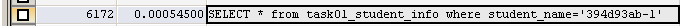

明天计划的事情:由于eclipse与maven都已安装完毕,明天会从15项开始。
遇到的问题:
测试数据的构建、存储过程的使用。查询的相关资料已经转存在个人的博客中
http://blog.csdn.net/yy243/article/details/69567388
http://blog.csdn.net/yy243/article/details/69565118
http://blog.csdn.net/yy243/article/details/69547321
http://blog.csdn.net/yy243/article/details/69542373
收获:初步了解了索引对于查找效率的提高,了解了利用存储过程构建测试数据的方法,了解了uuid()的使用与截取




评论