发表于: 2017-04-05 20:37:50
2 1850
有点拖沓了,但是必须扎实前进
今天完成的事:建立了姓名索引,然后在没有索引和有索引的情况下,分别查询某条姓名数据,
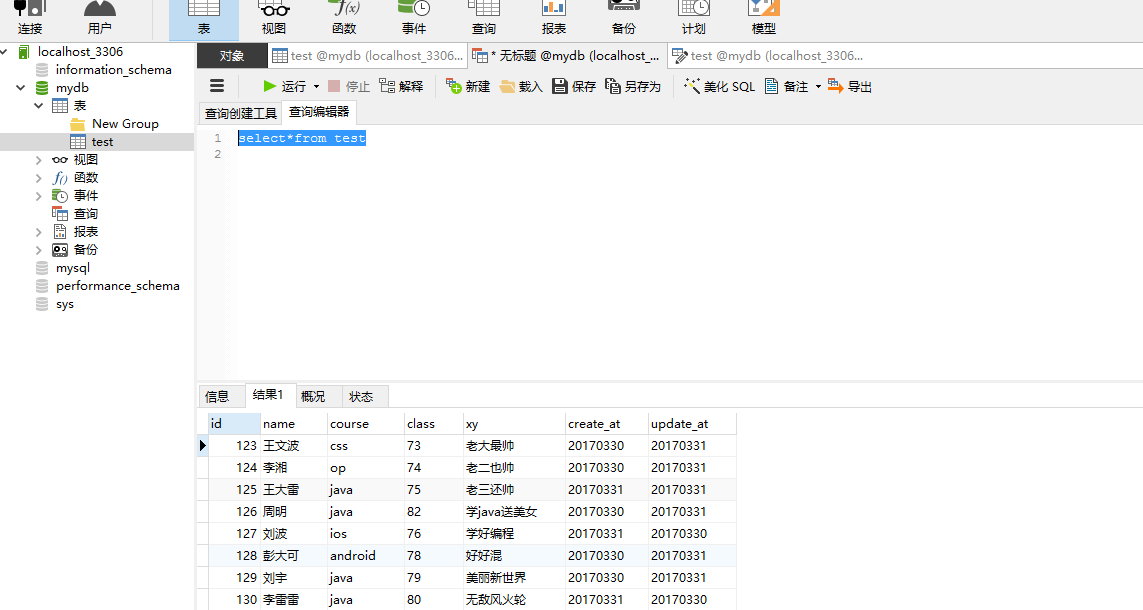
好像结果没差在哪儿,没出现他们帖子中速度加快的情况
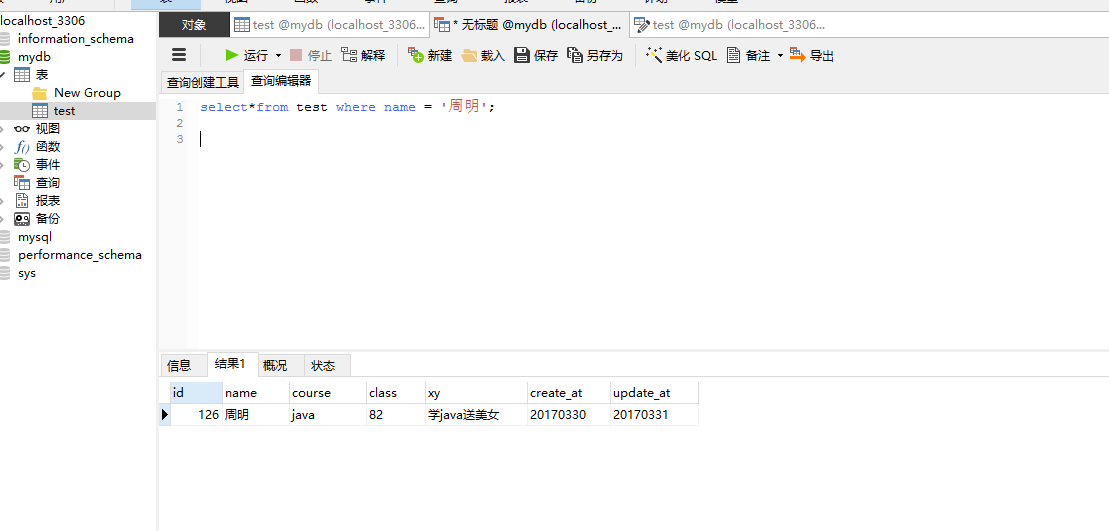
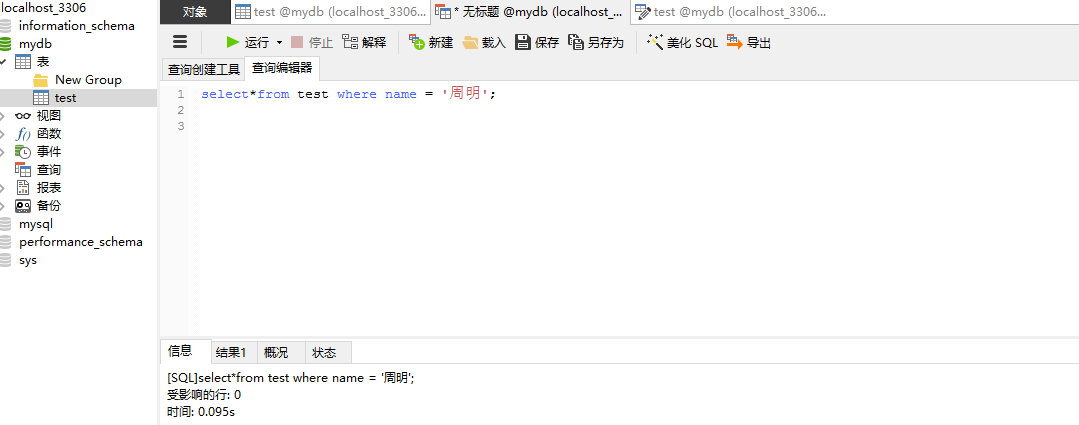

上次的问题:时间都用long型
原因:long,首先id对应的是bigint类型 而其他两个create_at和update_at使用long类型是将时间转化为毫秒存储在数据库中,这是为了节省空间也是为了存储方便
使用sql语句时,要留意数据类型。字符串string类型,内容要加单引号,而且是英文输入法的单引号,否则会出错。
遇到的问题:mysql 插入数据失败防止自增长主键增长的方法
解决方法:这个错误应该是插入数据的时候,表中出现了相同的主键把Mysql主键如果在insert插入时有值,将不使用自增。也就是说插入数据的时候只要自己把ID加上就按照插入的数进行自增了,这个数通过自己的逻辑判断代码来赋值,只要ID不重复就可以了
这是自己觉着比较有用的两篇文章:
数据库表字段命名规范http://www.cnblogs.com/gssajl/articles/2457048.html
Navicat建立索引http://blog.csdn.net/morelzh/article/details/28599609
关于深度思考的问题:
1.为什么DB的设计中要使用Long来替换掉Date类型?
答:long表示简单,占用内春晓把java中的时间long值直接存入数据库,在数据库里可以使用int,int占4个字节,DATETIME/TIMESTAMP 占8个字节,而且我发现有些系统是使用的int标识的。
时区问题也是需要考虑的因素,上传一个项目,服务器在美国,咱在国内访问,看到的却是美国的时间。存储时间的毫秒,创建Date的时候传入此毫秒值和使用此时间的时区即可。这样同一时间值在不同的时区显示的事不同的时间表示。推荐用long,从设计意义上说,可以很容易的解决时区问题,即使用不到。
2.自增ID有什么坏处?什么样的场景下不使用自增ID?
答:所有插入的数据id必须是顺序排列的,如果遇到id是无序的,不能自己操作
优点:节省时间,根本不用考虑怎么来标识唯一记录,写程序也简单了,数据库帮我们维护着这一批ID号。
缺点:for example, 在做分布式数据库时,要求数据同步时,这种自增ID就会出现严重的问题,因为你无法用该ID来唯一标识记录。同时在数据库做移植时,也会出现各种问题,总之,对此自增ID有依赖的情况,都有可能出现问题。
3.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
答:索引是对数据库表中一个或多个列(例如,employee 表的姓名 (name) 列)的值进行排序的结构。数据库索引好比是一本书前面的目录,能加快数据库的查询速度。多大数据量这个不知道,也没百度出来,如果一个字段有很多不同的值,就要建索引了。
4.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引?
答:唯一索引和普通索引使用的结构都是B-tree,执行时间复杂度都是O(log n)。
1、普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。普通索引允许被索引的数据列包含重复的值。比如说,因为人有可能同名,所以同一个姓名在同一个“员工个人资料”数据表里可能出现两次或更多次。
2、唯一索引
如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。这么做的好处:一是简化了MySQL对这个索引的管理工作,这个索引也因此而变得更有效率;二是MySQL会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在某个记录的这个字段里出现过了;如果是,MySQL将拒绝插入那条新记录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
以上答案均为百度或参考师兄,自身尚无能力感悟,仍需努力!
收获:在解决的几个语法型错误后发现,还是一些语法的基础不是很好,还有一些编程的思想要领悟,自己有了一定的了解,希望下面可以更进一步
明天计划的事:在进一步深入学习和理解数据库的基础上,开始JAVA7的使用和学习




评论