发表于: 2017-04-02 23:56:51
0 1523
4月2日完成的事情:
1、远程听老大训话
4月3日计划的事情:
1、完成修改codeReview结论提出的问题
存在的问题:
1、关于查询数据表中根据查询条件获取count,
现在的写法是:
List<Long> count = talentService.getIdsByDynamicCondition(Talent.class, param, 0, Integer.MAX_VALUE);
这种方式的问题在于性能,设置start为0,size为Integer.MAX_VALUE它会把符合条件的数据全部返回,而我们仅仅是需要统计符合条件的记录数,
之前对sql语句学习的不深,今天听老大讲才知道数据库中有专门统计个数的语句,后面就学了一下mysql中count用法,count(*)和count(列名)的执行效率问题
网上查到一些资料:
1.除非要统计某列非空值的总数,否则任何情况一律用COUNT(*),效率比COUNT(列名)高很多
2.除非有特殊需要,否则COUNT(*)不要加WHERE条件,会严重影响效率,如果加了条件COUNT(*)和COUNT(主键)效率是一致的,COUNT(非主键)效率很低
3.在没有WHERE条件的情况下:COUNT(*)等于COUNT(主键)优于COUNT(非主键有索引)优于COUNT(非主键无索引)
4.只要加了WHERE就会降低效率,即使是WHERE 1=1
不过在有WHERE限制条件的情况下,COUNT(*)会比COUNT(COL)快非常多;
项目中用到是动态查询符合条件的个数,即只需要统计主键也就是id的个数,所以COUNT(*)和COUNT(id)的效果也就是一样了,用COUNT(*)
动态拼接sql语句,修改DynamicUtil工具类getTalentList方法代码
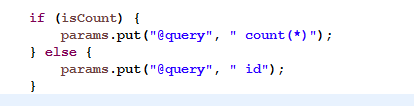
方法参数增加一个isCount字段,count统计时传入true,查询ids时传入false,

这是相对select id的一种优化,其实count主要是用来统计数据量用于显示总页码,对于显示总页面,今天听老大提供了一个思路:
不允许使用select id的方式查询数据量,应该使用count查询得到总记录数
但是count查询也仍属性很耗性能的一种方式,一旦数据量很大的话就容易出问题。
这时要考虑的是用到缓存memcache,项目用到的dao中做了还多事情,其中一个count实现中有关于这部分内容,
如果缓存仍然不能满足需要时,就要考虑不显示总页码而只提供上一页和下一页操作,
最后当上一页下一页也满足不了的情况下老大给了一个判断是否有下一页的小技巧:
查询当前页数据时多查询一条数据,然后判断这条数据是否存在,如果存在,就说明有下一页,否则就没有下一页,这个小技巧挺妙的。
这是今天老大讲到的根据不同的数据量规模,系统要求的不同而采用不同的优化方案,而作为一个后端工程师要想往深处发展就必须考虑代码的优化
明天继续。。。




评论