发表于: 2017-02-24 23:52:05
1 1164
一、今天完成的事情:
1.白天的时候彻底完成了后台的公司列表和职位列表页面。
2.晚上重新学习了执行上下文和内存空间;
二、明天要做的事情:
1.继续做后台
2.继续学习基础知识;
三、收获:
关于内存空间:
一、栈内存和堆内存
1.栈内存如何存取:
相当于一个乒乓球盒,先进的后出,后进的先出。如果我们要取到底层的东西,就必须要将前面的所有东西都取出才能取到最底层的
2.堆内存如何存取数据:
栈就相当于我们的书架,在书架中我们并不需要把每一本都拿出来才能取到最下面的东西,只要我们知道它的名字,就能够通过它的名字取到它。就像我们的json对象一样,用key-value来储存,它们并没有顺序,我们只需要知道它们的名字就能够直接取出它们。
二、变量对象与基础数据类型
1.变量对象与基础数据类型,变量对象是在我们js的执行上下文生成后,创建出了一个特殊对象---变量对象,js中的基础数据类型往往都保存在变量对象中,(严格意义上说,变量对象也是保存在堆内存中,但是由于它的特殊职能,我们需要在理解时将它与堆内存区分开来)。
2.基础数据类型:null、boolean、undefined、string、num,这五种是js中的基础数据类型,基础数据类型都是按值访问的,因为我们可以直接操作变量中实际的值。
三、引用数据类型与堆内存:
1.引用数据类型为:object和arry,
2.引用数据类型会保存在栈内存中,
接下来还是上demo:
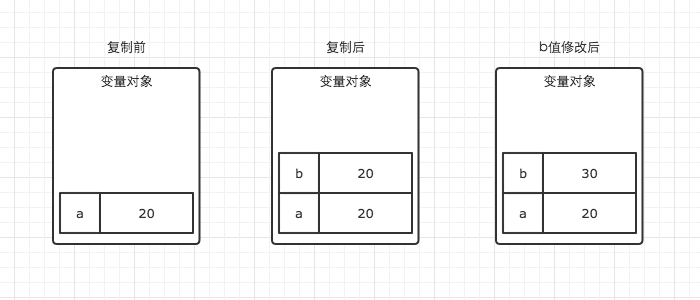
var a = 10;
var b = a;
b=30;
console.log(a) //10
var b = a;
b=30;
console.log(a) //10
为什么a会等于10,因为基础数据类型会储存在栈内存中,当b=a的时候,实际上a和b都已经独立出来了,所以改变b的值并不会影响a,图解;

接下来是引用数据类型:先上代码:
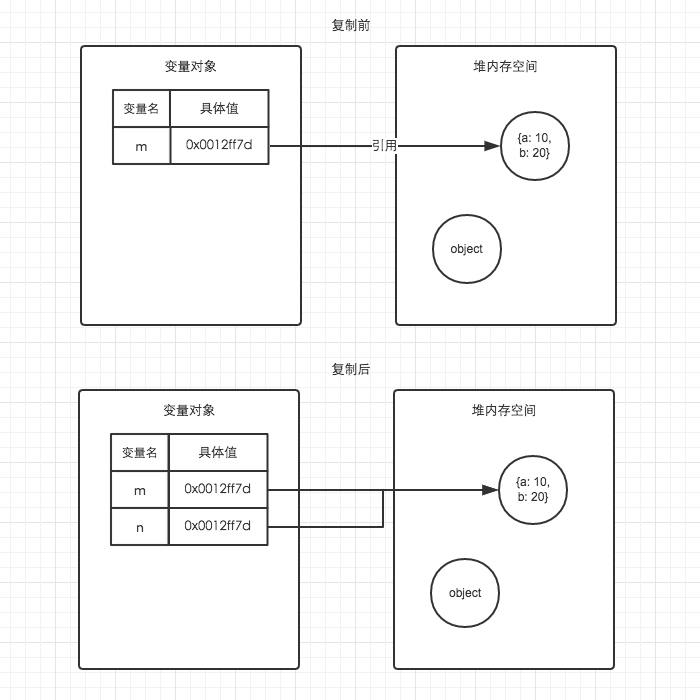
var m = { a:10, b:20 };
var n = m;
n.a = 15;
console.log(m) // { a:15, b:20 }
var n = m;
n.a = 15;
console.log(m) // { a:15, b:20 }
为什么这里又改变了呢,前面我们讲过,引用对象类型保存在堆内存中,我们这边将它赋值给m,只是将指向它的一个指针赋值给了m,保存在变量对象中,然后我们又将指向这个对象的指针赋值给了n,尽管在变量对象中,尽管它们的值是相互独立的,但是他们访问到的具体对象都是{a:10,b:20},因此我们改变了n中的a属性,也改变到了m中的a属性,看图:
.png)
四、内存空间管理:
1.标记清除,当js进入环境的时候,js会为所有变量加上标记,然后去除当前环境所用到的变量和被环境中的变量的引用的标记。当它又进入到下一个环境的时候,又会为所有的变量和它的引用都加上标记,在此期间,被加上标记的变量就是即将被回收的变量。
2.引用计数:我的理解是,当一个引用类型的东西被赋值给了一个变量,那么这个这个变量就储存了一个地址,这个引用类型的数字就加1,相反的如果包含这个地址的变量又有了另外一个地址,这个值就减1,当这个值等于0的时候,然后它就会释放所有计数为0的值。这种方式存在一个问题,当两个对象互相引用的时候,它永远不会被清除,上代码
var m = {a:'原始对象'}//次数为1
var n = m //次数加1 等于2
var m = {b:'新对象'}//这个是一个新的对象 所以-1等于1,现在n中保存的对象,还是指向原始对象的,所以原始对象还不会被清除。
var n = {c:'新对象'}//现在n中保存的地址也不指向原始对象了,所以原始对象的引用等于0,原始对象被回收
var n = m //次数加1 等于2
var m = {b:'新对象'}//这个是一个新的对象 所以-1等于1,现在n中保存的对象,还是指向原始对象的,所以原始对象还不会被清除。
var n = {c:'新对象'}//现在n中保存的地址也不指向原始对象了,所以原始对象的引用等于0,原始对象被回收
当然现在的浏览器都会使用标记清除模式,还需要提到一点是垃圾回收机制会在什么时候开始运行,IE6中它是这样运行的:256个变量、4096个对象或者64kb的字符串,它就会运行来尝试清除那些应该清除的变量和对象。这种方法带来的问题是,如果我一直都有这么多东西在使用的时候,垃圾处理机制会一直运行,严重影响性能,ie7的发布解决了这个问题,当它第一次发现清除的数据没有超过总量的15%,它将会将这个值翻倍,当清除了这么多之后,这个值又会回到基础值。为了保证我们的运行效率,我们可以在全局变量使用完之后,给它声明它等于null,这样内存回收机制就会回收它了。
两张图贴在最后面,请自行配合观看。。。看的东西都理解了,很开心




评论