发表于: 2017-02-05 17:36:14
6 2235
今天完成的事情
1、完成了任务1中的具体步骤5、6、7、8、9、10、11、12
2、将表中字段名修改为英文,今天理解了报名格式,所以重新设计了表结构,因为还不会将两个表联系在一起,所以都安排到了一张表,如下。

步骤6 插入
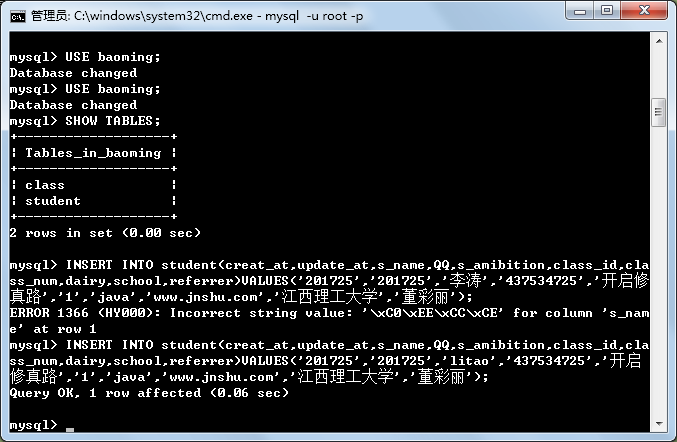
步骤7 更新数据

步骤8 备份删除与还原

步骤9、10 索引

建立索引前

建立索引后

可以明显看到建立索引使得查找时间变短,认为还应为ID字段建立索引,因为ID的唯一性与经常使用ID查找的特性,因为不太了解索引的全部功能,觉得查找某一班级,或修某一课程的所有人也是经常用到的查找,这个问题待解决。
步骤12
JDK和JRE从他们的英文全称很容易区分开,一个是 Java development kit,一个是 Java runtime environment。更简单的来说就是如果不需要开发程序而只需要运行Java程序,则只用下载JRE,否则JRE、JDK都需下载。
明天计划的事情
完成步骤13、14、15、16,了解什么是Maven,继续学习Java Collection类
遇到的问题
设计数据库表时任务中Long类型到底只什么类型?creat_at和update_at为什么要设置成Long而不是Date?按Java中的说法,Long是指一个类?
解决:
百度说法为long是指4 Byte的数据,按此说法应选择类型中的int。
原来的师兄也提出过这个问题,也有师兄的解答,对我很有用学习了,看来任务中的Long is not mean Long类

收获
1、更好的理解了怎么建立报名表,会写简单地SQL语句了,对Navicat也熟悉了许多,对索引的概念有了了解,以后还需深入学习。
2、索引是对数据库表中一个或多个列(例如,employee 表的姓名 (name) 列)的值进行排序的结构。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),即可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多。可见,索引是用来定位的。
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。有关数据库所支持的索引功能的详细信息,请参见数据库文档。
提示:尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。
唯一索引 唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
主键索引
数据库表经常有一列或多列组合,其值唯一标识表中的每一行。该列称为表的主键。
在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
聚集索引和非聚集索引的区别,如字典默认按字母顺序排序,读者如知道某个字的读音可根据字母顺序快速定位。因此聚集索引和表的内容是在一起的。如读者需查询某个生僻字,则需按字典前面的索引,举例按偏旁进行定位,找到该字对应的页数,再打开对应页数找到该字。这种通过两个地方而查询到某个字的方式就如非聚集索引。




评论