发表于: 2017-01-16 15:11:09
1 2016
今日完成:
1.参考修真院线下报名贴(学习资料-线下报名-北京报名)中报名的格式,整理出业务模型,确定需要几个对象,每个对象的属性是什么,对象和对象之间的关系是一对一,还是一对多。
两个对象(报名,用户,一对一)
2.下载并安装及配置Mysql 5.5
完成
3.下载Navcat,或者是Hedisql,连接Mysql,别问我Navcat收费怎么办。
完成
4.创建出来报名贴的业务表,并将表结构粘贴到日报中,对比之前师兄的表结构设计,看看有什么差别
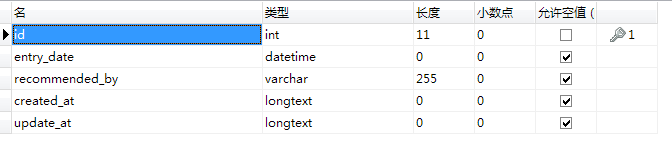
以上是报名表

以上是用户表
5.使用Navcat设计mysql数据库,数据库要有三个基本的字段,ID(自增Long),create_at,update_at(所有的时间都用Long)。
完成
6.从报名贴中找一条最近报名的师弟,用Mysql插入这条数据,并能够根据姓名查出来这条记录
完成
7.分别用Navcat和Sql语句去将本条数据记录的报名宣言改成老大最帅
完成
8.将表导出成Sql文件,并使用navcat和Sql分别尝试删除此条数据,并用之前备份的Sql恢复。
完成,有点纠结怎么用语句实现备份,看了http://dev.mysql.com/doc/refman/5.7/en/backup-methods.html。发现内容及其丰富,估计需要以后慢慢消化了。
9.给姓名建索引,思考一下还应该给哪些数据建索引
需要用来搜索的,数据本身变化很多的都需要索引,比如预计入学日期。
10.插入10条数据,查看有索引和无索引的情况下,Sql语句执行的效率
有索引时效率会慢一点。
11.MYSQL深度思考题:
5.为什么DB的设计中要使用Long来替换掉Date类型?
不理解,我上Stackoverflow上看到的答案几乎都是建议使用Date。理由
是避免日期格式问题,方便日期运算,减少储存量。
6.自增ID有什么坏处?什么样的场景下不使用自增ID?
http://stackoverflow.com/questions/2186260/when-to-use-an-auto-incremented-primary-key-and-when-not-to
假设表中已有一列可以做为ID使用(该列数据不重复),这种情况下再使用自增ID来寻找,会比通过查找此列操作多。Query语句会更复杂。
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情
况下该对字段建索引?
在http://stackoverflow.com/questions/1108/how-does-database-
indexing-work的第一个答案中有比较好的解释。我的理解是,对于无法
使用快速搜索算法的列的数据,使用索引给他一个数字的标志符。
数据量越大,性能差别越明显。
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
前者保证某一列中的数据都是唯一的。例如ID,号码类需要唯一索引。
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判
断这个QQ号已经存在了?
不需要,数据库会报错无法插入。
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间
应该在什么情况下赋值?是否应该开放给外部调用的接口?
INSERT INTO / UPDATE 。否,由数据库自行写入。
11.修真类型应该是直接存储Varchar,还是应该存储int?
Int,这样避免类似于"Java工程师"和"JAVA工程师"这样的命名不统一造
成的问题。再建一张表用来保存修真类型和id之间的关系
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的
区别是什么?
13.怎么进行分页数据的查询,如何判断是否有下一页?
14.为什么不可以用Select * from table?
一是增大了数据库内的操作量;二是服务器收到的数据也会更多;两者都
会降低处理速度,对于后端人员来说还需要编写代码来过滤数据。
明日计划:
Java环境配置,使用Maven创建和管理项目
问题和解决:
整理出业务模型:为了理解一对多和多对一,看了不少关于外键的资料,不只是讲怎么实现外键,而是理解外键是用来约束数据的,当主键被修改时外键会有相应的约束或者变化。
收获:
基础知识是关键,Navicat能把数据库的操作变得很简单,但背后是MySQL等数据库软件,再背后是SQL这门数据库语言,再背后是所谓的关系型数据库这个思想。每一层都有大量的知识需要了解。以前只是写写前端或者后端的代码的自己,现在看到数据库,觉得不简单了。




评论