发表于: 2021-12-16 23:07:14
0 1743
深度思考:缓存应该在Service里,还是应该存放在Controller里,为什么?
放在services层,复用高,易管理。因为一般的web是不会controller对缓存这层做直接控制的
放在Service
好处:统一管理,复用性高,controller层不需要理会数据是从缓存中获取还是从mysql中获取,controller完全解放出来了。
不好处:没法对单个controller进行控制了,controller失去了对缓存的控制权。
放在Controller
好处:可以单个Controller进行控制,每个controller中有各自对数据的键,以及缓存时间等。
不好处:每个controller需要写一份几乎一模一样的代码,很繁琐。即使你写一个公共的方法,那也要在各个地方写上这个公共方法,属于重复工作了。
深度思考:什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
热点数据及高频数据应该放入缓存中
缓存淘汰算法
不可能实现的算法 OPT
OPT(OPTimal Replacement,OPT)算法,其所选择的被淘汰的数据将是以后永不使用的,或是在最长(未来)时间内不再被访问的数据。
未来发生的事情是无法预测的,所以该算法从根本上来说是无法实现的,OPT算法对于内存缓存来说,能够提供最高的cache命中(cache hite)率,通过OPT算法也可以衡量其他缓存淘汰的算法的优劣。
无脑算法 FIFO
FIFO(First Input First Output,FIFO)算法算是一种很无脑的淘汰算法,实现起来也很简单,即每次淘汰最先被缓存的数据。
FIFO算法很少会应用在实际项目中,因为该算法并未考虑数据的 “热度”,一般来说,应该是越热的数据越应该晚点淘汰出去,而FIFO算法并未考虑到这一点,所以,该算法的cache命中率一般会比较低。
常见算法 LRU
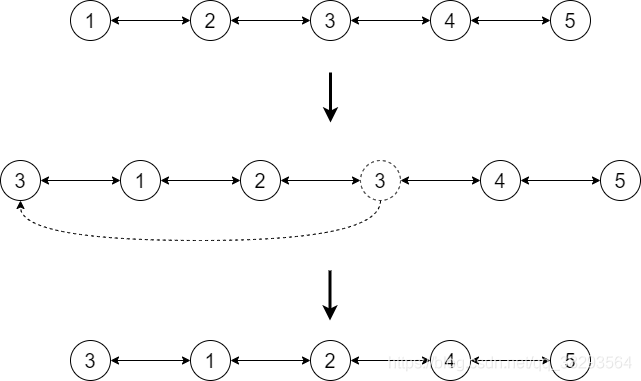
LRU(Least Recently Used,LRU)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU最友好的数据模型为具有时间局部性的请求队列,每访问一个已缓存的节点,就将该节点转移到队列头部,每次淘汰时,以此淘汰队列尾部节点,示意图如下:
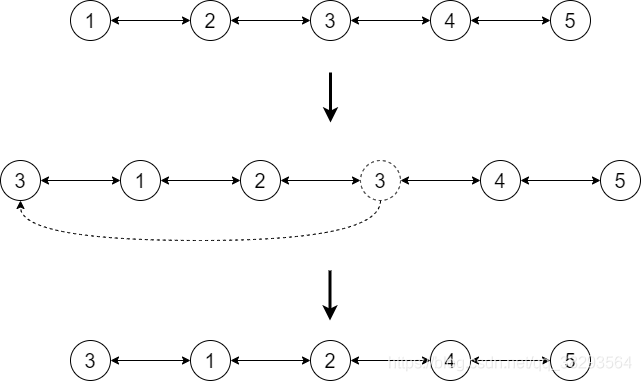
采用队列实现的话,每转移一个节点,都需要遍历该队列,为了提高查找效率,通常会采用Hashmap+双向链表来实现LRU算法。
当存在热点数据时,LRU的缓存命中率比较高,但是由于未考虑频率因素,偶发性的、周期性的批量操作时缓存效果较差,缓存污染严重。
为了解决LRU算法未考虑频率因素的问题,人们在此基础上又提出了LRU-K算法,其中,K代表最近使用的次数,因此LRU可以认为是LRU-1算法,其核心思想是将 “最近使用过1次”的判断标准扩展为“最近使用过K次”。
相比LRU,LRU-K需要多维护一个访问历史队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
LRU-K算法不仅具有LRU算法的优点,而且LRU-K算法将LRU算法的“访问1次”扩展为“访问K次”,弥补了LRU算法未考虑频率因素的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者采用更大的K值,缓存命中率会增高,但适应性会变差,因为随着K值得增大,需要大量的数据访问才能将历史访问记录清除;同时,LRU-K算法需要维护一个历史访问队列,因此内存消耗也会增加,同时,LRU-K需要将缓存队列的中元素按照访问时间排序,以方便淘汰访问时间最久的元素,所以,该算法也需要额外的O(logN)时间复杂度。
进阶算法 2Q
2Q(Two Queues)算法和LRU-2类似,不同点在于2Q将LRU-2算法中的访问历史队列改为一个FIFO缓存队列,即2Q算法有两个缓存队列:一个是FIFO队列,一个是LRU队列。
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据,示意图如下:
2Q算法和LRU-2算法缺点类似,由于维护了两个缓存队列,内存消耗会增加,但是2Q算法的时间复杂度优化到了O(1)。
和LRU-K算法类似,MQ(Muti Queue)是2Q算法的拓展算法,MQ算法将按照数据的访问频率划分成多个队列,不同的队列具有不同的访问优先级,MQ算法总数优先缓存访问次数最多的数据,随着数据的访问频率越高,其所处的队列优先级也越高,当数据从最高优先级访问队列中淘汰出去之后,会重新加入到第一级的访问队列中,以此类推。
但是MQ算法需要维护多个优先级队列以及缓存数据,内存消耗比较大。
进阶算法 LIRS
LRU算法是应用范围很广的cache淘汰算法,但是该算法存在以下几个缺点:
对冷数据突发性访问抵抗能力差,可能会因此淘汰掉热的文件;
对于大量数据的循环访问抵抗能力查,极端情况下可能会出现命中率0%;
不能按照数据的访问概率进行淘汰;
可以说其主要缺点是第三条,其他缺点,都是由于该确定所导致的,所以,在LRU的基础上,又有了LRU-K、2Q、MQ等各种衍生算法,但是这些算法由于要多维护几个缓存队列,会消耗更多的内存资源,为了解决上述的所有问题,后面又提出了一种LIRS缓存淘汰算法。
LIRS算法中,对于每一个缓存数据块,都维护了以下两个变量来衡量数据的访问频率:IRR(Inter-Reference Recency)和R(Recency),IRR为一个数据块最近两次访问期间,有多少个不同的数据块被访问过,当数据块第一次被访问时,IRR初始化为无穷大(inf)




评论